Ein allgemeines Buch über die Grundlagen der Datenanalyse mit R+; ein dicker Brocken, eher als allgemeine Einführung gedacht. Ich würde aber immer eher das Buch von Hadley empfehlen
Als generelle Einführung in die Statistik empfehle ich The Art of Statistics+ oder Naked Statistics+, beides sehr gute und unterhaltsame Bücher (nicht nur für Statistiker)
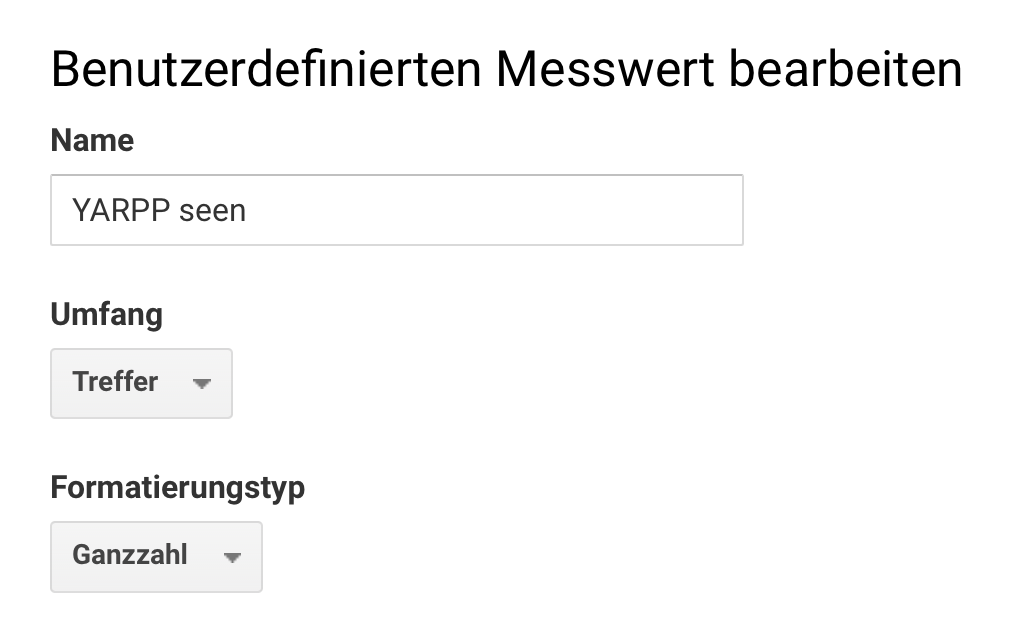
Zum Jubiläum der Website Boosting (60. Ausgabe!) gibt es hier einen Deep Dive, wie man einen benutzerdefinierten Bericht zu den bis zum Ende gelesenen Texten erstellen kann. Dies ist eine Ergänzung zu meiner vierteiligen Serie “Webanalyse: Wie aus Daten Taten folgen”, in der 60. Ausgabe findet sich der 3. Teil. Grundsätzlich hatte ich über das Thema auch schon einmal hier geschrieben im Vergleich zur Scrolltiefe. Dies ist ein Beispiel dafür, wie benutzerdefinierte und berechnete Messwerte verwendet werden können.
In dem Screenshot wird pro Seite angegeben:
Wie viele Wörter ein Text hat
Wie häufig eine Seite aufgerufen wurde
Der Anteil der Aufrufe, der zu einem Ausstieg geführt hat
Die Anzahl der Sichtbarkeit des YARPP-Elements (YARPP steht für Yet Another Related Posts Plugin, welches ähnliche Artikel am Schluss eines Artikels anzeigt. Ist dieses Element auf dem Bildschirm des Nutzers sichtbar, so wird davon ausgegangen, dass der Artikel über dem Element zu Ende gelesen wurde)
Der Anteil der Sichtbarkeit des YARPP-Elements mit Hinblick auf alle Seitenaufrufe
Die Anzahl der Klicks auf einen YARPP-Link
Der Anteil der Klicks auf einen YARPP-Link in Bezug auf die Sichtbarkeit des Elements
Welches Problem wird mit diesem Bericht gelöst?
Wird ein Text seltener zu Ende gelesen als andere Texte, dann scheint dieser Text nicht so interessant geschrieben zu sein.
Die Länge des Textes könnte ein Prädiktor dafür sein, ob ein Text zu Ende gelesen wird; wird aber ein kürzerer Text nicht zu Ende gelesen, so könnte das ein noch stärkeres Signal dafür sein, dass der Text optimierungswürdig ist.
Werden die Links zu ähnlichen Artikel nicht angeklickt, obwohl sie sichtbar sind, so scheinen sie nicht relevant zu sein.
Erstellen der benutzerdefinierten Dimension und Messwerte
In Analytics auf Verwaltung (links unten) gehen und dann in der Property-Spalte auf Benutzerdefinierte Definitionen klicken.
Zunächst auf Benutzerdefinierte Messwerte und dann auf den roten Button Neuer Benutzerdefinierter Messwert klicken
Einen verständlichen Namen auswählen (z.B. “YARPP Seen”)
Der Umfang (Scope) ist Treffer (Hit)
Der Formatierungstyp ist Ganzzahl (Integer)
Die restlichen Werte können leer gelassen werden
Auf Speichern klicken.
Den Prozess noch einmal wiederholen, dieses Mal für die “YARPP Clicks”. Die Einstellungen sind dieselben.
Der erste Eintrag sollte nun den Index-Wert 1 haben, der zweite Eintrag den Index-Wert 2, es sei denn, es wurden schon einmal benutzerdefinierte Variablen definiert.
Sollte auch die Anzahl der Wörter eines Textes erfasst werden, so ist dazu eine benutzerdefinierte Dimension notwendig. Der Prozess ist ähnlich, hier wieder einen passenden Namen auswählen und den Umfang Treffer. Auch hier muss der Index-Wert für diese benutzerdefinierte Dimension in Erinnerung oder notiert werden, da er später im Google Tag Manager verwendet werden soll.
Implementierung im Google Tag Manager
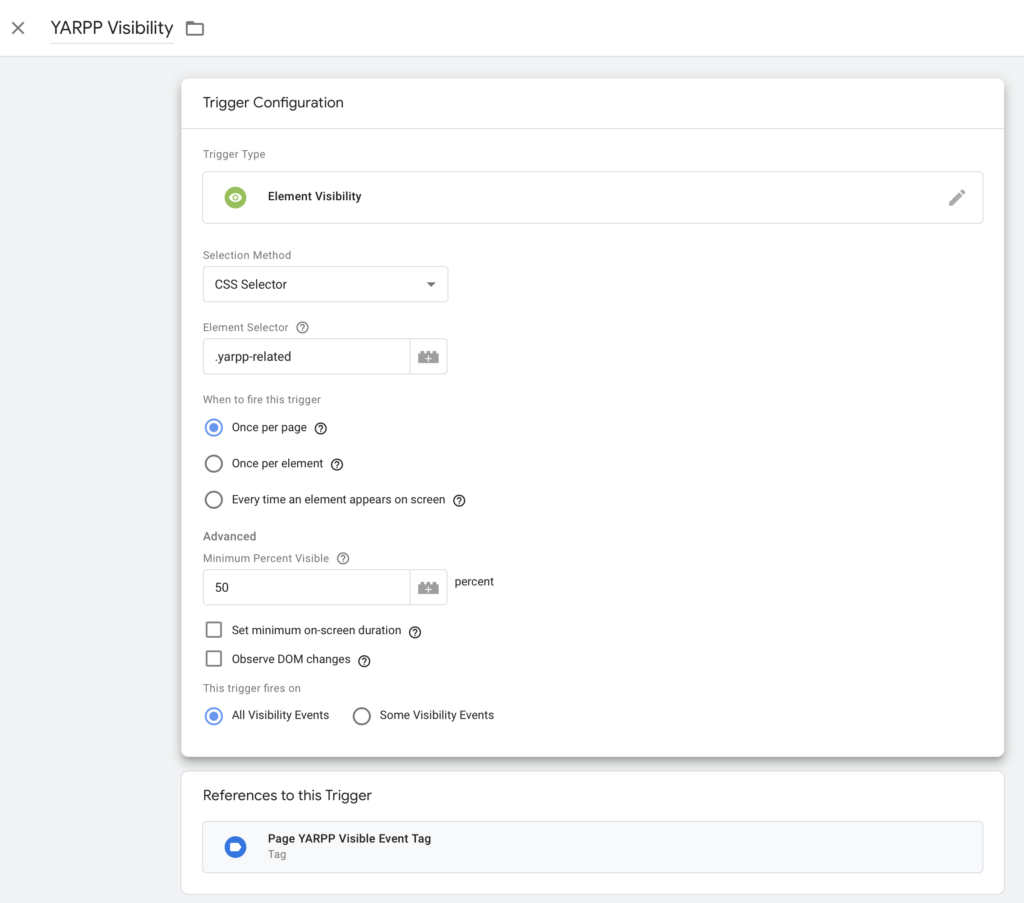
Sind die benutzerdefinierten Definitionen und Messwerte implementiert, so können nun Werte in diese Variablen geschrieben werden. Dies geschieht mit dem Tag Manager. Zunächst einmal muss das Element ausgewählt werden auf der Seite, bei dem der Trigger der Sichtbarkeit ausgelöst werden soll. Die dazu notwendigen Schritte sind bereits in diesem Artikel beschrieben. Dann wird der folgende Trigger konfiguriert:
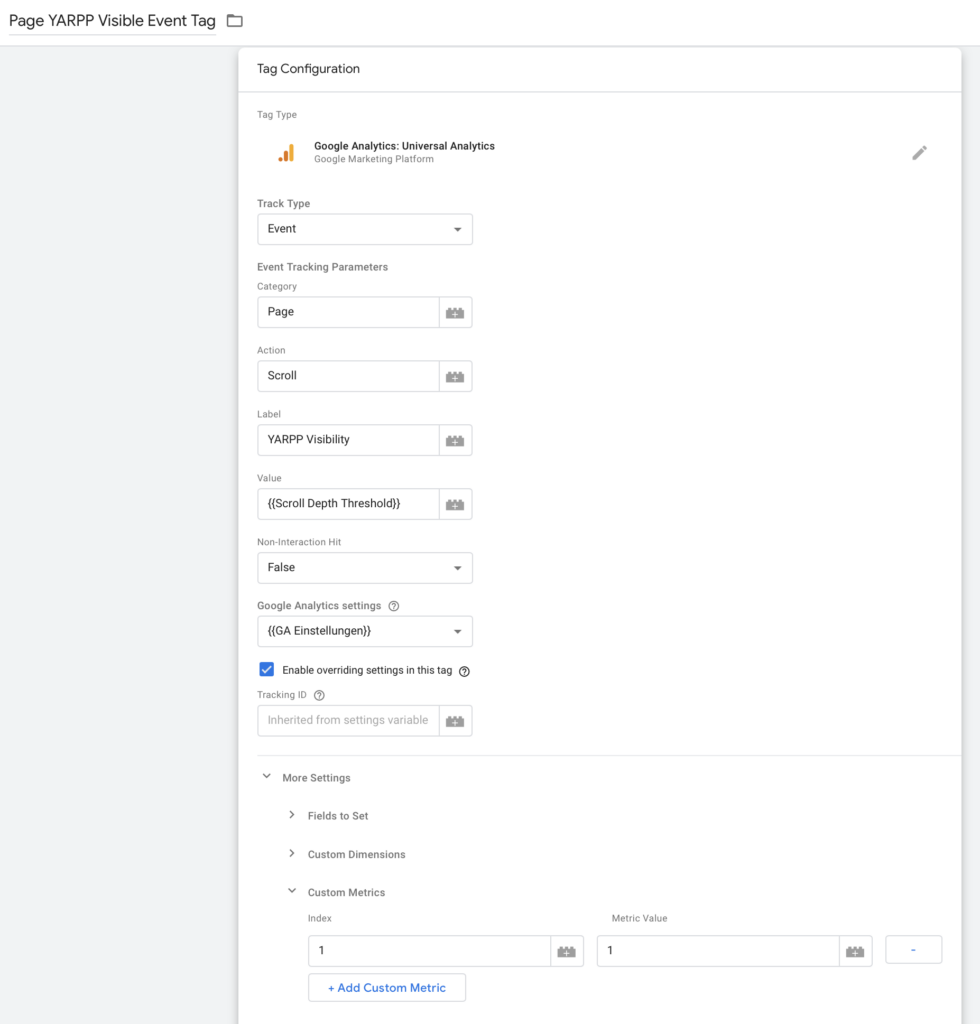
Der Trigger feuert einen Tag, der nun auch noch konfiguriert werden muss:
Wichtig ist in diesem Schritt, dass die Einstellungen überschrieben werden, da nur so ein Messwert als benutzerdefinierter Messwert (im Screenshot Custom Metrics) übergeben werden kann. Hier muss dann der Indexwert gewählt werden, der in dem Schritt oben von Analytics definiert wurde. Der Wert des Messwerts ist hier 1, da für jede Sichtung der Zähler um 1 nach oben springt.
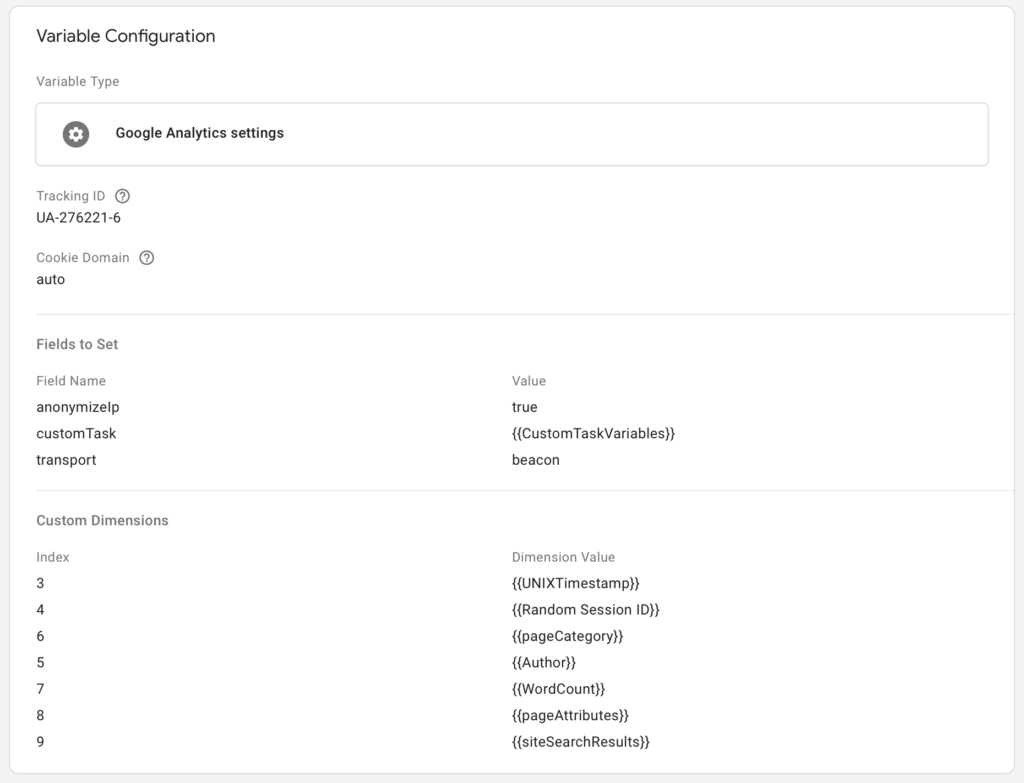
Die Variable Scroll Depth Threshold ist nicht notwendig, eventuell muss sie zunächst konfiguriert werden. Dieser Schritt muss dann noch einmal wiederholt werden für die Klicks auf einen YARPP-Link und gegebenenfalls für die benutzerdefinierte Dimension der Anzahl Wörter pro Text. Diese können aber bereits in den Google Analytics Einstellungen übergeben werden, die als Variable definiert werden. In meinem Fall sieht die Konfiguration so aus:
Wie man schön sehen kann, ist an meiner Konfiguration einiges speziell, aber der WordCount wird in eine benutzerdefinierte Dimension mit dem Indexwert 7 übergeben.
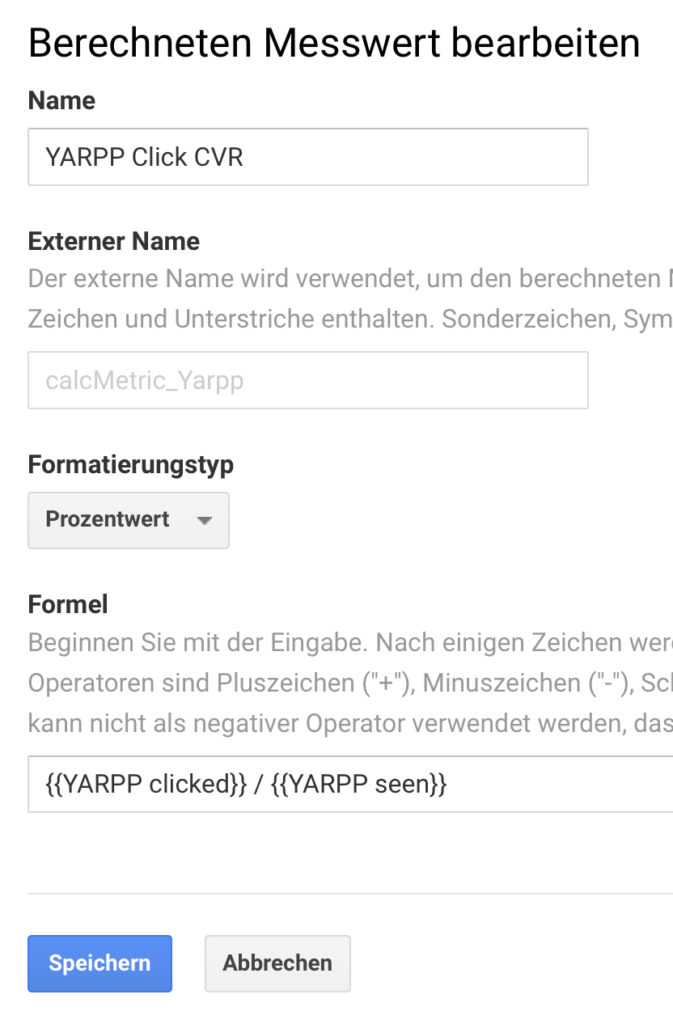
Erstellen des berechneten Messwerts
Damit eine Ratio beziehungsweise Conversion Rate angezeigt werden kann, wird ein berechneter Messwert erstellt. Dies sind die Spalten “YARPP Seen CVR” und “YARPP Click CVR” in dem Beispiel-Bericht im ersten Screenshot. Hinweis: Es kann etwas dauern, bis die benutzerdefinierten Messwerte hier sichtbar sind! Das heißt, dass dieser Arbeitsschritt eventuell erst nach einigen Stunden oder sogar erst nach einem Tag durchführbar ist.
In dem Screen Verwaltung in der ganz rechten Spalte findet sich der Eintrag Berechnete Messwerte. Hier auf den roten Button Neuer Berechneter Messwert klicken und dann im folgenden Screen die folgenden Einstellungen übernehmen. Es reicht, die ersten Buchstaben des Variablennamens einzutippen, Analytics vervollständigt die Namen. Dies ist die Einstellung für die Click CVR:
Für die Seen CVR wird die Formel {{YARPP seen}} / {{Seitenaufrufe}} verwendet.
Erstellen des benutzerdefinierten Berichts
Zu guter Letzt wird nun ein Bericht erstellt, so wie er im ersten Screenshot oben zu sehen ist. Unter Anpassung (links oben) und Benutzerdefinierte Berichte kann ein neuer Bericht erstellt werden. Hier werden alle gerade benutzerdefinierten und relevante ab Bord verfügbare Metriken ausgewählt und dazu die passende Dimension ausgewählt. Leider kann hier keine sekundäre Dimension bereits ausgewählt werden; dies muss dann manuell geschehen, wenn der benutzerdefinierte Bericht aufgerufen wird.
Google Optimize ist eines meiner Lieblings-Tools, denn es ermöglicht jedem schnell a/b-Tests zu bauen; in meinen Kursen staunen die Teilnehmer häufig, wie schnell so ein Test online sein kann. Natürlich ist die Vorarbeit, das saubere Erstellen einer Hypothese, nicht so schnell getan, aber es macht auch keinen Spaß, monatelang auf die Live-Schaltung eines Tests zu warten. Über die Vorzüge von Google Optimize will ich auch gar nicht weiter eingehen, sondern stattdessen auf drei Feinheiten hinweisen, die nicht so offensichtlich sind.
Google-Optimize-Daten in Google Analytics Rohdaten verwenden
Die Google Analytics API erlaubt auch den Zugriff auf Google Optimize-Daten, die in Analytics reinlaufen, was ermöglicht, dass die Analytics-Rohdaten zu einem Google Optimize-Test analysiert werden können. Das ist vor allem dann interessant, wenn etwas nicht als KPI in Optimize verwendet werden kann, man in Google Optimize vergessen hat, einen KPI einzustellen oder Nebeneffekte analysiert werden sollen. Einiges davon geht auch hinterher mit Segmenten, aber hey, hier geht es ums Hacken (im Sinne von Tüftler, nicht Krimineller), da macht man auch Dinge, weil man sie machen kann, nicht weil sie immer notwendig sind
Die beiden wichtigen Optimize-Dimensionen heißen ga:experimentId und ga:experimentVariant, mittlerweile existiert auch eine Kombination, die ga:experimentCombination heißt. Wobei, wenn man nur einen Test fährt, dann reicht es auch, nur die Dimension ga:experimentVariant abzufragen. 0 ist die Originalvariante (Kontrollgruppe), danach wird pro Variante hochgezählt. Hat man mehrere Tests am laufen, so einfach in der Google Optimize-Oberfläche die ID nachschauen; sie findet sich in der rechten Spalte unter Google Analytics. Sie ist meistens sehr kryptisch, wie man auf dem Bild sehen kann.
In meinem Beispiel habe ich zwei Experimente am Laufen, so dass ich mir die Kombination ausgeben lasse neben drei Custom Dimensions (Client ID, Hit Type und UNIX Timestamp) sowie Seitentitel (die Client ID hab ich auf dem Bild etwas abgeschnitten, da es ja nur ein pseudonymisiertes Datum ist). Wir sehen auf dem zweiten Bild die beiden Experimente und die jeweiligen Varianten in einem Feld. In dem Test, der mit c-M startet, hatte ein Kursteilnehmer die Hypothese aufgestellt, dass die Besucher meiner Seite mehr Seiten ansähen und mehr Zeit verbrächten, wenn das Suchfenster weiter oben wäre. Ich habe nicht daran geglaubt, aber Glauben ist nicht Wissen, also haben wir den Test gefahren mit dem KPI Session Duration. Vergessen hatte ich hier, die Anzahl der Suchen als zweiten KPI einzustellen. Nun gut, dass ich die Rohdaten habe, auch wenn ich dafür natürlich auch ein Segment bauen könnte.
Wie wir in dem Screenshot auch sehen können, sind die Nutzer gleichzeitig in zwei Tests, da der andere Test keinen Einfluss auf den ersten Test haben sollte. Nun gab es während der Test-Laufzeit von 4 Wochen auf meiner Seite nur 3 Nutzer, die nach etwas gesucht haben, einer der Nutzer hat eine Query mehrmals gesucht, ein Nutzer hat zwei verschiedene Terme gesucht. Bei einer so geringen Fallzahl brauchen wir erst gar nicht über Signifikanz nachdenken. Zwischenzeitlich sah es mal so aus, als würde tatsächlich die Suchfenster oben-Variante gewinnen, aber dazu im letzten Abschnitt mehr. Die Frage ist nun, warum überhaupt die Variante besser sein kann, wenn doch kaum gesucht wurde? Oder hat allein die Präsenz der Suchbox zu einer längeren Session Duration geführt? Sehr unwahrscheinlich!
Das sollten wir uns einmal genauer anschauen…
Zu beachten ist in den Rohdaten, dass es nun für jeden Hit eines Nutzers zwei Einträge gibt, einen pro Test. Außerdem wird nicht jeder Nutzer in einem Test sein, auch wenn 100% des Traffics getargeted sind, was man aber auch schon in Google Analytics sehen kann. Ebenso können wir überprüfen, ob durch die zufällige Auswahl von Test- und Kontrolgruppenteilnehmern eine einigermaßen gleichmäßige Aufteilung der Nutzer erfolgt ist (z.B. Mobile versus Desktop etc). Auch das ist natürlich mit dem Interface möglich.
Das erste, was auffällt, wenn ich die Daten aus der API ziehe, ist, dass die Werte nicht mit denen aus der GUI übereinstimmen. Das ist zunächst einmal ziemlich beunruhigend. Schaue ich mir nur Users und Sessions an, so stimmen die Werte genau überein. Nehme ich die Dimension experimentCombination hinzu, so passen die Zahlen nicht mehr, und es liegt nicht an den Unterschieden zwischen API v3 und v4. Es ist nicht ungewöhnlich, dass die Daten nicht zusammen passen, meistens geschieht das durch Sampling, aber das kann hier nicht der Fall sein. Interessanterweise stimmen auch die Zahlen innerhalb der GUI nicht überein, wenn ich mir die Daten unter Experiments ansehe und sie mit dem Dashboard zur Zielgruppe vergleiche. Die Zahlen aus der API stimmen aber mit den Daten aus dem Experiments-Bericht überein. Vorsicht also wer Segmente bildet!
Ziehe ich die Daten inklusive meiner ClientID-Dimension, so habe ich etwas weniger Users, was sich dadurch erklärt, dass nicht jeder User eine solche ID in die Custom Dimension reinschreibt, d.h. er hat diese Client ID wahrscheinlich (oder sicherlich, denn sonst könnte GA ihn nicht als einzelnen Nutzer identifizieren), aber ich schaffe es irgendwie nicht die ID in die Dimension zu schreiben, so dass dort zB “False” steht.
Nun schauen wir uns einmal ein paar Daten an. Mich interessiert zum Beispiel, ob Optimize es schafft, die gleiche Verteilung über Devices hinzubekommen wie ich sie auf der Seite habe:
Der Großteil meines Traffics findet noch auf dem Desktop statt. Wie sieht es in Optimize aus?
Die Verteilung ist definitiv eine andere. Das ist auch wenig verwundertlich, denn auf AMP-Seiten sollte kein Optimize-Experiment ausgespielt werden; es ist also eher verwunderlich, warum hier überhaupt noch Experimente auf Mobilgeräten stattgefunden haben. Und diese Fälle haben andere Werte in Bezug auf den Ziel-KPI, wie man auch in Analytics sehen kann:
Wir können also nicht von den Testergebnissen auf die ganze Seite schließen, wir wissen aber auch nicht, wie groß der Effekt der unerwarteten Mobile-User auf das Testergebnis ist. Hierzu müssten wir also den Gewinner neu ermitteln. Doch wie wird der Gewinner überhaupt ermittelt? Wir könnten zum Beispiel einen Chi-Square-Test verwenden mit der Beobachtung der durchschnittlichen SessionDuration:
chisq.test(x) Pearson’s Chi-squared test with Yates‘ continuity correction data: x X-squared = 1.5037, df = 1, p-value = 0.2201`
In diesem Fall ist p über 0.05, zu p im nächsten Abschnitt mehr. Sollte der Chi-Square-Test überhaupt der richtige Test sein, so ergäbe er, dass der Unterschied nicht statistisch signifikant ist. Allerdings ist das nicht der Test, den Google Optimize verwendet.
Bayessche Inferenz versus NHST
Was passiert da eigentlich genau unter der Motorhaube? Schauen wir uns an, wie Google Optimize berechnet, ob eine Variante gewonnen hat oder nicht. Im Gegensatz zu Adobe Test & Target zum Beispiel oder den meisten Signifikanzrechnern wie dem von Konversionskraft (wobei Konversionskraft nicht mal sagt, was für einen Test sie nutzen), basiert Google Optimize nicht auf einem t-Test, Mann-Whitney-U- oder Chi Square-Test, sondern auf einem Bayes-Inferenz-Verfahren. Was bedeutet das?
Hier treffen zwei unterschiedliche Vorstellungen aufeinander, die der sogenannten Frequentists (NHST steht für Null Hypothesis Significance Testing) und die der Bayesschen Inferenz-Anhänger. Diese wurden und werden zum Teil immer noch in der Statistik intensiv diskutiert, und ich bin nicht der Richtige, um hier ein Urteil zu fällen. Aber ich versuche, diese beiden Ansätze für Nicht-Statistiker zu beleuchten.
In den meisten A/B-Test-Tools werden Hypothesen-Tests durchgeführt. Man hat zwei Gruppen von ungefähr gleicher Größe, die eine Gruppe wird einem “Treatment” ausgesetzt, und dann wird beobachtet, ob sich der definierte KPI in der Testgruppe “signifikant” ändert. Für Signifikanz wird meistens auf den p-Wert geschaut; sofern dieser unter 0,05 liegt oder wie auch immer das Signifikanz-Niveau definiert wurde, wird die Null-Hypothese abgelehnt. Zwar sieht man auf den Tool-Oberflächen nichts von Null-Hypothesen etc, wahrscheinlich um die Nutzer nicht zu verwirren, aber das Denkkonstrukt dahinter geht davon aus. Wird zum Beispiel getestet, ob ein roter Button häufiger angeklickt wird als ein blauer, so würde die Null-Hypothese lauten, dass beide gleich häufig angeklickt werden. Der Hintergrund davon ist, dass sich eine Hypothese nicht immer belegen lässt. Wenn aber das Gegenteil der Hypothese eher unwahrscheinlich ist, so kann angenommen werden, dass eine Hypothese eher wahrscheinlich ist. Von nichts anderem handelt der p-Wert.
Nun ist der p-Wert keine einfache Geschichte, nicht einmal Wissenschaftler schaffen es, den p-Wert so zu erklären, dass es verständlich ist, und es wird diskutiert, ob er überhaupt sinnvoll ist. Der p-Wert sagt nichts darüber aus, wie “wahr” ein Testergebnis ist. Er sagt lediglich etwas darüber aus, wie wahrscheinlich es ist, dass dieses Ergebnis auftritt, wenn die Null-Hypothese wahr ist. Bei einem p-Wert von 0,03 bedeutet das also, dass die Wahrscheinlichkeit, dass ein Ergebnis auftritt bei einer wahren Null-Hypothese, bei 3% liegt. Das bedeutet umgekehrt nicht, wie “wahr” die Alternative Hypothese ist. Der umgekehrte p-Wert (97%) bedeutet also nicht eine Wahrscheinlichkeit, dass eine Variante eine andere Variante schlägt.
Ein häufiges Problem mit a/b-Tests ist zudem, dass die Sample-Größe nicht vorher definiert wird. Der p-Wert kann sich über die Laufzeit eines Experiments ändern, und so können statistisch signifikante Ergebnisse nach ein paar Tagen schon nicht mehr signifikant sein, da sich die Anzahl der Fälle geändert hat. Außerdem interessiert nicht nur die Signifikanz, sondern auch die Stärke/Trennschärfe/Power eines Tests, die nur in den wenigsten Test-Tools angezeigt wird.
Das sind aber vor allem Probleme der Tools, nicht des Frequentists-Ansatzes, der von den meisten Tools genutzt wird. Das “Problem” des Frequentists-Ansatzes ist, dass sich ein Modell nicht ändert, wenn neue Daten hereinkommen. So kann bei wiederkehrenden Besuchern eine Änderung auf der Seite irgendwann gelernt werden, so dass ein anfänglicher a/b-Test zwar große Wirkung prophezeit, die tatsächliche Wirkung aber viel geringer ist, weil im Frequentists-Ansatz einfach nur die Gesamtzahl von Conversions gezählt wird, nicht die Entwicklung. In der Bayesschen Inferenz werden neu hereinkommende Daten aber berücksichtigt, um das Modell zu verfeinern; geringer werdende Conversion-Raten würden das Modell beeinflussen. Daten, die sozusagen “vorher” vorhanden sind und die Annahmen über den Einfluss in einem Experiment beeinflussen, werden Anfangswahrscheinlichkeit oder “Priors” genannt (ich schreibe Priors, weils schneller geht). Das Beispiel in der Google-Hilfe (das auch anderswo gerne bemüht wird), ist, dass, wenn man sein Handy im Haus verlegt, nach der Bayesschen Inferenz das Wissen, dass man sein Handy gerne mal im Schlafzimmer vergisst, verwenden und auch einem Klingeln “hinterherlaufen” darf. Bei den Frequentists darf man das nicht.
Und hier genau tut sich das Problem auf: Woher wissen wir, dass die “Priors” relevant sind für unsere aktuelle Fragestellung? Oder, wie es im Optimizely-Blog gesagt wird:
The prior information you have today may not be equally applicable in the future.
Die spannende Frage ist nun, wie Google in Optimize auf die Priors kommt? Dazu wird folgende Aussage gemacht:
Despite the nomenclature, however, priors don’t necessarily come from previous data; they’re simply used as logical inputs into our modeling.
Many of the priors we use are uninformative – in other words, they don’t affect the results much. We use uninformative priors for conversion rates, for example, because we don’t assume that we know how a new variant is going to perform before we’ve seen any data for it.
An diesen beiden Blogauszügen wird schon deutlich, wie unterschiedlich das Verständnis von der Nützlichkeit der Bayesschen Inferenz ist Gleichzeitig ist offensichtlich, dass uns wie in jedem anderen Tool auch Transparenz darüber fehlt, wie genau die Berechnungen zustande gekommen sind. Ein weiterer Grund, dass man, wenn man auf Nummer sicher gehen will, die Rohdaten benötigt, um eigene Tests durchzuführen.
Der Bayes-Ansatz erfordert mehr Rechenzeit, was wahrscheinlich der Grund dafür ist, dass die meisten Tools nicht diesen Ansatz nutzen. Es existiert auch Kritik an der Bayes-Inferenz. Das Hauptproblem aber ist, dass die meisten Nutzer viel zu wenig wissen von dem, was genau die a/b-Test-Tools tun und wie belastbar die Ergebnisse sind.
Warum ein A/A-Test auch heilsam sein kann
Nun stellt sich die Frage, warum überhaupt ein Unterschied sichtbar war bei der Session Duration, wenn doch kaum jemand gesucht hat. Hier kann ein A/A-Test helfen. A/A-Test? Richtig gelesen. Auch sowas gibt es. Und ein solcher Test hilft dabei, die Varianz der eigenen Seite zu identifizieren. So hatte ich einen wunderbaren Test, bei dem ich die AdSense-Klickrate nach einer Design-Änderung getestet hatte. Die Änderung war sehr erfolgreich. Um ganz sicher zu gehen habe ich noch mal getestet; dieses Mal hatte die Änderung schlechtere Werte. Nun kann es natürlich sein, dass einfach schlechtere Ads geschaltet wurden und sich deswegen die Klickrate verschlechtert hatte. Es könnte aber auch einfach sein, dass die Seite selber eine Varianz hat. Und diese kann man herausfinden, indem man einen A/A-Test fährt (oder die vergangenen Rohdaten für einen solchen Test nutzt). Bei so einem Test wird in der Test-Variante einfach nichts geändert und dann geschaut, ob sich einer der Haupt-KPIs ändert oder nicht. Rein theoretisch sollte sich nichts ändern. Aber wenn doch? Dann habe wir eine Varianz identifiziert, die in der Seite und dem Traffic selbst liegt. Und die wir in zukünftigen Tests berücksichtigen sollten.
Fazit
Unterschiede in Test-Ergebnissen können durch eine bereits bestehende Varianz einer Seite zustande kommen. Hier hilft ein A/A-Test, um die Varianz kennen zu lernen.
Die Ergebnisse können sich unterscheiden, wenn unterschiedliche Tools eingesetzt werden, da die Tools unterschiedliche Herangehensweisen haben, wie sie die “Gewinner” ermitteln.
Rohdaten können helfen, eigene Test-Statistiken zu verwenden oder Test-Ergebnisse zu verifizieren, da die Tools wenig Transparenz darüber bieten, wie sie zu den jeweiligen Tests gekommen sind. So kann es zum Beispiel wie in meinem Beispiel sein, dass der Test gar nicht gleichmäßig ausgespielt wurde und daher die Ergebnisse nicht so eindeutig verwendbar sind.
Die Rohdaten unterscheiden sich zum Teil stark von den Werten in der GUI, was nicht erklärbar ist.
Der p-Wert ist nur ein Teil der Wahrheit und wird häufig missverstanden.
Bei a/b-Tests sollte man sich bei den Frequentists-Ansätzen vorher überlegen, wie groß die Sample-Größe sein sollte.
Das Zeitalter der sinnvollen Webanalyse hat gerade erst begonnen. Mehr und mehr Unternehmen verstehen, dass PageViews kein geeigneter KPI sind, um den Erfolg der Content-Investments zu überprüfen. Und dennoch naht das Ende dessen, was wir gerade liebgewinnen, bevor es zu schön werden kann.
Dies ist kein weiterer Click-Bait-Artikel darüber, wie Maschinen uns die Jobs wegnehmen werden. Natürlich wird Machine Learning die einfachen Analysten-Jobs eliminieren. Wir sehen heute schon, dass Google Analytics in der kostenlosen Variante selbständig Anomalien entdeckt. Fragen an die Daten können per gesprochener Sprache gestellt werden. Und da die Herausforderung meistens darin besteht, dass die richtigen Fragen an die Daten gestellt werden, wird auch das über die selbständige Analyse abgedeckt werden. In der 360er Variante bietet Analytics den neuen Analyze-Modus. Analysen werden mehr und mehr automatisiert erstellt werden können. Und das ist gut so. Denn auch wenn wir viel Erfahrung einbringen und wissen, welche Segmente zu untersuchen sich lohnt, eine Maschine kann einfach alle Kombinationen durchrechnen und auf Segmente kommen, die wir als Menschen niemals gefunden hätten. Das Stochern im Heuhaufen hat damit ein Ende. Und es ist effizienter, wenn Maschinen diese Suche unternehmen. Es bleibt schon jetzt nicht mehr dabei, dass nur Informationen aus Daten generiert werden – schon jetzt werden Handlungen abgeleitet. Das, was für die meisten Nutzer am schwierigsten ist, aus den Daten zu lernen, was man eigentlich tun müsste, wird auch von der Maschine interpretiert und artikuliert werden können.
So einfach ist es nicht, werden die Kutscher der Web Analyse sagen: Man kann nur dann etwas Sinnvolles aus den Daten ziehen, wenn diese sinnvoll erhoben wurden. Und in den meisten Fällen ist das nicht der Fall, dass sinnvolle Daten erhoben werden. Solange in vielen Fällen eine Standard-Installation eines Web Tracking-Tools Anwendung findet, gibt es noch viel zu tun. Doch wenn wir uns den heutigen Google Tag Manager einmal genauer ansehen, dann wird klar, dass viele Nutzerinteraktionen heute auch schon automatisch getracked werden können. Klicks auf Links. Scroll-Tiefe. Element-Visibilität. Was heute noch eingerichtet werden muss, könnte morgen schon automatisch erfolgen. Und es wäre der logische nächste Schritt. Gehen wir also davon aus, dass irgendwann in naher Zukunft das Einrichten eines Tag Management wegfallen wird. Je nachdem wie viel man zahlt, werden Events mehr oder weniger granular gemessen. Und zwar nur die, von der die Maschine gelernt hat, dass sie für ein definiertes Ziel wichtig sind.
Die Komplexität der Daten-Akquise wird wegfallen, und die Analyse wird wegfallen. Was wird dann noch überbleiben? Eine digitale Strategie auszuarbeiten, die auf Basis von Daten gestaltet ist? Das sehe ich nicht im Markenkern der Webanalysten. Die manuelle Webanalyse ist eine Brückenqualifikation, der Tankwart der Analytics-Lösungen. Denn in spätestens 5 Jahren, 2023, werden die großen Kunden schon mit der Webanalyse-KI arbeiten und nicht mehr mit einem teuren, eitlen Webanalysten.
Was sollen wir tun, wir “Web-Analyse-Helden”? Entweder qualifizieren wir uns weiter, vom Tankwart zum Modulhersteller. Oder wir verkaufen die Süßigkeiten drumherum. Die McJobs der Webanalyse. Und die können auch in Indien abgefackelt werden. Uns bleibt nur die Möglichkeit, mit Hilfe von Data Science Lösungen zu entwickeln, die für Google Analytics und Co zu nischig sind, um sie als erstes zu belegen. Wir werden noch wenige Jahre mit Implementierungen und Schulungen Geld verdienen können, aber spätestens 2023 ist Schluss damit.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Maik says
Mai 2018 at 13:22 Hallo Tom,
danke für deinen Beitrag, der eine für viele neue Sichtweise bietet. Aus unserem Gespräch im Rahmen unserer Podcastaufnahme weiß ich ja durchaus schon, dass du da einen sehr datengetriebenen Ansatz hast und auch die Zukunft der Webanalyse eher dem Machine Learning unterordnest.
Wie so viele Disziplinen, die aktuell im (Online-) Marketing existieren, so gehört auch die Webanalyse zu den – meine ich – immer noch aufsteigenden Trends. Denke mal an SEA, SEO, Affiliate Marketing, E-Mail-Marketing, … das alles boomt. Immer noch. Obwohl etwa SEO schon vor längerer Zeit ständig totgeredet wurde – und Google immer mehr Kompetenz zugeschrieben bekam, die Dinge schon „alleine“ zu können. Sicherlich, Google IST besser geworden. Doch die Menschen/Unternehmen mit ihren Websites sind es nicht. Und so ähnlich sehe ich das auch bei der Webanalyse.
So lange eine Disziplin noch nicht in der Breite (vor allem Mittelstand und kleine Unternehmen) angekommen ist, sind fünf Jahre ein, wie ich finde, zu kleiner Zeitraum, um Veränderungen in der Breite zu erzielen. In der Spitze (z. B. Konzerne) sehe ich das etwas anders, aber die Masse muss es mitbekommen – ansonsten ist die Veränderung eher eine der lokalen Maxima. Vielleicht bedeutet das aber auch, dass wir dann alle für Amazon arbeiten.
Ich gebe dir Recht, wenn du sagst, dass Maschinen Anomalien oder Cluster in den Daten wesentlich besser erkennen können als jeder Mensch es je könnte. Doch die Frage ist: Was machen am Ende wir, die Menschen, damit? Und da braucht es nun mal – vermutlich deutlich länger als 2023 – nach wie vor Menschen, die das in ein „Tun“ übersetzen, nachdem sie es zuvor mit Ihrer Strategie abgeglichen haben.
Haken an der Sache: Maschinelles Lernen braucht Daten – möglichst viele sogar. Und IMHO haben wir am 25. Mai in der Hinsicht einen ordentlichen Schritt nach hinten gemacht. Vielleicht haben wir – bzw. diejenigen, die die DSGVO beschlossen haben – Europa damit sogar ziemlich ins Abseits gestellt. Und die Regelungen der Verordnung und die Ängste der Menschen vor Missbrauch der Daten sorgen dafür, dass es vorläufig so bleibt. Das ist für viele Unternehmen schon eine ziemliche Bremse.
Zudem, auch wenn sich das natürlich in den nächsten Jahren durchaus ändern kann und sicher auch wird: KI oder ML ist derzeit noch kein „Massenphänomen“. Jeder spricht zwar darüber und erahnt vielleicht die Möglichkeiten, aber tatsächlich ist da draußen noch nicht überall „Hurra“ zu hören. Es fehlt an Systemen, die mehr Daten erheben, (aktuell) Menschen, die sich damit auskennen und letztlich auch oftmals an Wissen, was man damit alles anfangen kann.
Du sagtest völlig zurecht: Es braucht die richtigen Fragen. Ohne die ist KI noch deutlich länger als 2023 hilflos. Doch um die richtigen Fragen zu stellen, braucht es Menschen mit Verständnis für Zahlen, Business, Strategien und Umsetzungskenntnis. OK, vielleicht heißen die irgendwann nicht mehr Webanalyst (genauso wie es dann keine reinen SEOs mehr geben mag und die SEAler, deren Job allesamt die Google KI übernommen hat), doch die Webanalyse selbst wird Teil eines vielleicht neuen Berufsbildes sein, das AUCH das Verständnis der Webanalyse voraussetzt – und dafür braucht es immer noch Menschen, die den ganzen Tag nichts anderes machen. Schulungen werden dann vielleicht eher auf Strategien abzielen.
Ich sehe Webanalysten und Data Scientists da auf mehr oder weniger getrennten Schienen unterwegs. Der Webanalyst ist für mich häufig näher am Business und dem, was aus Zahlen folgt. Das reine Daten-Aufbereiten und Co. – da bin ich mir sicher – wird sicher irgendwann einfach wegfallen.
Naja, und über allem, was du und ich sagen steht ja noch eine Sache: Vielleicht haben wir in 5-10 Jahren auch kein Internet mehr, sondern etwas noch Cooleres.
Danke, dass du das Thema hier mal in deinen Blog bringst. Und Doppel-Dank für die Analogie mit dem Tankwart. Love it. Volltanken, bitte. Maik
Tom Alby says
Mai 2018 at 23:33 Lieber Maik,
jeder Austausch mit Dir hilft mir, meine Gedanken zu sortieren und zu hinterfragen, und dafür bin ich Dir wie immer sehr dankbar.
Der Grund, warum ich das Ende des Web Analysten innerhalb weniger Jahre prophezeie, ist keine reine Effekthascherei. Ich glaube daran. Und das aus den folgenden Gründen:
Wenn wir von einer linearen Entwicklung ausgingen, dann würde ich eine solche Prophezeiung nicht formulieren. Aber wir haben nun mal keine lineare Entwicklung. Wir haben eine nicht-lineare Entwicklung. Eine exponentielle Entwicklung. Und es ist eine Eigenschaft des Menschen, exponentielle Entwicklungen zu unterschätzen. Eine alte Legende zeigt das in der Person Sissa ibn Dahir (https://de.wikipedia.org/wiki/Sissa_ibn_Dahir). 1996 schimpfte mein Vater noch mit mir, dass ich mir sowas Verrücktes wie ein Handy zugelegt hatte, 10 Jahre später hatten wir Internet auf dem Handy, noch mal 10 Jahre später haben wir Voice Assistants zuhause, und ein Internet unter 10 MBit ist zumindest in den Städten undenkbar. Genau diese exponentielle Entwicklung beschreibt auch Dein Artikel, oder?
Wir erschaffen nicht nur Technologie, sondern Technologie ändert auch uns. Technologie verändert unser Denken, und das führt immer wieder dazu, dass Technologie kritisiert wird. Die Schrift, so Ong, wurde von Plato kritisiert, weil sie das Denken externalisiert. Als die Taschenrechner aufkamen, wurde die gleiche Kritik laut, dass die Menschen das Rechnen verlernen. Und nun hören wir, dass die Künstliche Intelligenz uns das Denken abnimmt und das nicht gut sei. Tatsächlich aber hat uns jede Technologie weiter gebracht. Ob das immer gut war, das steht auf einem anderen Blatt. Aber selbst die Schrift als Technologie hat unser Denken verändert. Und so wird auch Machine Learning unser Denken verändern. Wir werden in wenigen Jahren in Machine Learning denken. Und wenn Du sagst, dass das momentan noch ganz weit weg sei, das glaube ich nicht aufgrund der exponentiellen Entwicklung.
SEO ist tot. Die meisten SEOs sind für mich die Heilpraktiker des Online Marketings. Wir glauben ihnen, weil es uns schwer fällt anzunehmen, dass wir nicht die Kontrolle haben. Aber ich habe, glaube ich, bereits genug Daten veröffentlicht, die belegen, dass wir es hier vor allem mit Snake Oil zu tun haben. Ich habe noch keinen SEO gesehen, der seine Zahlen so veröffentlicht wie ich.
Ja, vielleicht ist 2023 sportlich. Aber wenn Google irgendwas macht, dann etwas Skalierbares. Und auch wenn AdWords Express am Anfang nicht so toll funktioniert hat, mehr Daten werden dafür sorgen, dass es funktionieren wird.
Darf es zum Volltanken noch ein Snickers sein?
Tom
Maik says
Mai 2018 at 10:12 Hey Tom,
die Legende von Sissa ibn Dahir ist ein tolles Beispiel. Andererseits sind genau bei exponentiellen Steigungen gerade zu Beginn die Steigungen noch nicht so hoch, dass sie solche Umwerfungen provozieren. Aber du hast Recht: Wenn skalierbar, dann Google.
Und tatsächlich, der Beitrag, den ich verlinkt habe, beschreibt unter anderem genau dieses Wachstum – in mitunter erschreckenden, weil unglaublich riesigen, Dimensionen. Und natürlich hat jeder Mühe, der versucht, das zu verstehen. Wie ist es wohl, wenn es noch in diesem Jahrhundert Maschinen geben wird, die 1 Million Mal intelligenter sind als wir Menschen. I cannot imagine …
Das Gute ist ja, dass wir beide uns hier nicht wirklich darüber unterhalten OB es (die Ablösung bestimmter Jobs) passieren wird, sondern eigentlich nur WANN. Insofern bin ich in vielen Punkten bei dir. Letztlich zählt auch nicht, ob Webanalysten- oder Data-Scientist-Jobs eher wegfallen als andere, sondern eher, was unsere künftige Aufgabe sein wird. Ob es in Zukunft noch Menschen braucht, die „analytisch“ denken und mit „Kreativität“ an Lösungsansätze herangehen.
Und ja, ich sehe auch, dass SEO an vielen Stellen „überdenkbar“ (würde ich das mal wohlwollend nennen) geworden ist. Zumindest in der Art und Weise, wie es von vielen SEOs betrieben wird. (Dein Begriff „Heilpraktiker“ trifft es ganz gut, finde ich).
Auch in dieser Spezialdisziplin gilt für mich immer mehr: Es braucht Leute, die sich mit einer sinnvollen Informationsarchitektur (technisch und inhaltlich) im Hinblick auf ihre Nutzer auseinandersetzen und Verbesserungen tätigen. Dafür braucht es (derzeit noch) Verständnis für Menschen, Werte – und solide Daten, um Verbesserungen zu messen. Vielleicht werden Websites in 5 Jahren aber auch komplett von Maschinen gebaut. Vielleicht gibt es in 10 Jahren aber auch keine Websites mehr, sondern nur noch VR. Who knows?
Eine Sache noch: Ich hoffe, dass die Entwicklungen in den nächsten Jahren/Jahrzehnten nur so schnell vorangehen, dass wir Menschen eine Chance haben, unsere Rolle in der „neuen Welt“ zu finden – und nicht komplett überrollt werden. Denn wenn Maschinen irgendwann alles können, was wir Menschen können, und das auch noch viel besser, dann werden wir hier auf der Welt zwar sicherlich eine Menge Probleme lösen können – jedoch auch viele neue haben, was unsere Aufgaben angeht. Und gerade die Komponente „exponentiell“ ist da irgendwie – so lustig das klingen mag – unberechenbar.
Snickers? Ja, gerne. Zum Mitnehmen, bitte. Maik
Christian Hansch says
Juni 2018 at 16:09 Hallo Tom,
was meinst du am Ende deines Artikels genau mit der Qualifizierung zum Modulhersteller? Ich glaube auch, dass wir Web-Analysten in 5-10 Jahren abgelöst werden, aber eigentlich muss ich ja noch knapp 20-25 Jahre arbeiten. Hypothese: In Zukunft ist es noch wichtiger, die richtigen Fragen zu stellen mit ggf. den richtigen Nebenbedingungen, damit die Maschine die richtige Antwort „ausspucken“ kann.
Ich finde die GA – App mit dem aufzeigen der Anomalien auch super. Ich frage mich aber, wie die Maschine die diversen Ziele favorisieren soll und nicht immer wird nur der monetäre Output maximiert, manchmal auch die Kommunikation, die schwer messbar ist.
Beste Grüße Christian
P.S.: Schade, dass ich deinen Vortrag auf der Campixx nicht gesehen habe, dann könnte ich besser verstehen oder mit diskutieren, wieso SEO tot sein soll.
Im September 2017 hatte ich noch darüber geschrieben, dass die Scrolltiefe ein besserer Indikator dafür wäre, ob ein Inhalt gelesen wurde als die reine Sitzungsdauer, die eh Quatsch ist. Einen Monat später veröffentlichte Google dann eine neue Funktion im Google Tag Manager, einen Trigger für die Sichtbarkeit von Elementen (in der deutschen Version der Release Notes fehlte der Hinweis). Damit lassen sich einige Nachteile des Scrolltiefen-Ansatzes kompensieren, vor allem die Einschränkung, dass nicht jede Seite gleich lang ist und “75% gelesen” nicht immer bedeuten muss, dass der Inhalt auch bis zum Ende gelesen wurde (75% wurde deswegen gewählt, weil viele Seiten einen immensen Footer haben und die Nutzer daher nicht zu 100% runterscrollen). Eine Seite bei mir hat so viele Kommentare, dass sie mehr als die Hälfte des Inhalts ausmachen.
Was bedeutet die Sichtbarkeit von Elementen?
Ganz einfach erklärt bedeutet dieses Feature, dass ein Trigger ausgelöst wird, wenn ein Element der Seite auf dem Bildschirm des Benutzers sichtbar wird. Das Element muss nur eindeutig benannt werden können, so dass lediglich dieses eine Element mit diesem Namen den Trigger auslösen kann. Auf meiner Seite möchte ich zum Beispiel wissen, wie viele Nutzer so weit runtergescrollt haben, dass sie mit hoher Wahrscheinlichkeit den jeweiligen Text zuende gelesen haben. Wahrscheinlich ist das der Fall, wenn die Nutzer den Hinweis auf die ähnlichen Artikel sehen, die in meinem Blog durch das Plugin YARPP erstellt werden. In den meisten Browsern ist es möglich, ein Element mit der Maus zu markieren und dann mit einem Rechtsklick/CTRL-Klick darauf das Element zu untersuchen, so dass wir dann genau sehen können, wie dieses Element heißt.
Im Tag Manager kann nun dieser Trigger eingerichtet werden, das sieht zum Beispiel so aus:
Dazu wird dann noch ein Event eingerichtet, und schon haben wir ein Tracking auf Basis von der Sichtbarkeit eines Elements.
Macht das wirklich einen Unterschied aus?
Ja. Bei meinem Artikel über ein Jahr Erfahrung mit Scalable Capital haben knapp 30% mindestens 75% des Inhalts gelesen, aber knapp 70% haben das YARPP-Element gesehen. Die Seite besteht zu knapp 80% aus Kommentaren (es ist schon erschreckend genug, dass bei dem kurzen Artikel nur 70% das Element gesehen haben). Bei anderen Artikeln fällt die neue Messung der Sichtbarkeit von Elementen im Google Tag Manager nicht so dramatisch aus; so ist der Artikel über meine schlechten Erfahrungen mit dem Vorwerk Thermomix anscheinend zu lang für den Thermomix-Interessenten: 26,1% sehen die YARPP-Empfehlungen, 22,3% scrollen zu 75% runter.
Kann ich die Scrolltiefe jetzt abschalten?
Nein. Natürlich kannst Du tun, was Du willst, aber da die Sitzungsdauer durch das Auslösen von Events genauer wird, wollen wir nicht nur die Zeit derjenigen messen, die es bis zu dem definierten Element geschafft haben, sondern auch die Zeit derjenigen, die vorher, zum Beispiel bei 25% abgesprungen sind. Auch wenn es also auf den ersten Blick so aussieht als ob wir uns 4 Events sparen könnten, sollten wir zur Verbesserung der Datenqualität diese Events drin lassen.
Wie oft habe ich beim Thema Tracking-Konzept schon den Satz gehört “Lass uns einfach alles tracken, wir können uns doch später Gedanken machen, was wir eigentlich brauchen. Aber das Tracking-Konzept kann natürlich schon geschrieben werden!”
Stellen wir uns einmal vor, wir wollen mit einem Segelboot einen Törn unternehmen und wir sagten “Keine Ahnung wo wir hin wollen, lass uns doch einfach alles mitnehmen, was wir für alle Eventualitäten benötigen könnten”. Unser Boot würde sinken bevor der Törn begonnen hat. Wir wüssten nicht, ob wir Wasser und Konserven für einen Tag oder mehrere Wochen mitnehmen müssten, ob wir Winterkleidung oder Sommerkleidung benötigen und so weiter. Aber um auf Nummer Sicher zu gehen, kaufen wir einfach den ganzen Segelbedarfsladen leer, irgendwas davon werden wir schon brauchen. Und haben nun mehr, als das Schiff an Last ertragen kann. „Das optimale Tracking-Konzept oder Der Segeltörn ohne Ziel“ weiterlesen
Google Analytics hatte letztes Jahr seinen 10. Geburtstag, und in den letzten mehr als 10 Jahren durfte ich einiges an Erfahrung sammeln, was man beim Einsatz von Web Analytics-Systemen beachten muss. Hier sind meine 10 Basic-Tipps, angefangen mit den absoluten Basics, den Abschluss bilden dann die Basics für diejenigen, die auch wirklich was mit ihren Daten anfangen wollen
Nutze ein Tag Management System, vor allem bei komplexeren Konfigurationen (zum Beispiel Cross-Domain Tracking) ist das unabdingbar. Aber selbst wenn nur die hier beschriebenen Basics umgesetzt werden sollen, ist ein Tag Management System wichtig. Die meisten Systeme bieten eine Preview an, so dass nicht am offenen Herzen operiert werden muss. Und wenn Du Deinem Web Analytics-Menschen keinen Zugang zum Verändern des Analytics-Codes geben willst, dann ist ein Tag Management System sowieso Pflicht.
Wo wir gerade dabei sind: Der Google Tag Assistant ist eine gute Ergänzung, wenn Du den Tag Manager und/oder Google Analytics nutzt.
Teste alles, was Du tust, mit den Echtzeit-Berichten, sofern es nicht über den Tag Manager und den Tag Assistant getestet werden kann.
Nutze die Adjusted Bounce Rate. Hieran führt nichts vorbei. Die Absprungrate ist normalerweise so definiert, dass ein Absprung gezählt wird, wenn ein Benutzer auf die Seite kommt und sie “sofort” wieder verlässt. “Sofort” ist dann je nach Definition und System irgendetwas zwischen 5 und 10 Sekunden. Bei Google Analytics ist es so, dass ein Bounce als solcher gezählt wird, wenn ein Benutzer auf eine Seite kommt und sich keine weitere Seite anschaut, egal wie lange er darauf war. Er ist also vielleicht gar nicht wirklich gebounced/abgesprungen, sondern hat sich die ganze Seite durchgelesen, und nachdem sein Informationsbedürfnis befriedigt war, ist er wieder gegangen. Bei manchen Content-Seiten ist das ein ganz normales Verhalten. Aber es ist eben nicht wirklich ein Bounce. Ein Bounce bedeutet für mich, dass ein Benutzer die Landing Page als irrelevant betrachtet hat und deswegen sofort wieder gegangen ist. Und das ist eine Baustelle, die man erst dann erkennt, wenn man die richtige Bounce Rate konfiguriert hat.
Sei Dir darüber im Klaren, was der Sinn Deiner Seite ist. Da wärst Du auch alleine drauf gekommen? Ich habe zu oft erlebt, dass es in einer Firma sehr unterschiedliche Ansichten darüber gibt, warum eine Webseite existiert. Manchmal konnten sich die Teilnehmer eines Workshops in 2 Stunden nicht einigen. Warum existiert die Seite? Welche Rolle spielt sie in der gesamten Business-Strategie Deines Unternehmens? Ist es Abverkauf? Ist es Branding? Ist es Monetarisierung via Werbung? Wolltest Du einfach nur ein www auf dem Briefkopf haben? Hat Deine Seite mehrere Ziele? Auch ok. Schreib alle auf.
Wie kannst Du nun messen, ob die Geschäftsziele erfüllt werden? Dafür definierst Du die KPIs. Beispiel: Du willst etwas verkaufen, dann ist Dein Ziel die Anzahl der Conversions. Oder? Bei genauerem Hinschauen hast Du wahrscheinlich ein Umsatzziel (z.B. 1.000€ am Tag), und da hilft Dir die Anzahl der Conversions wenig, sofern Du nicht bei jeder Conversion den gleichen Betrag einnimmst. Für das Umsatzziel gibt es mehrere Stellschrauben, Traffic, Conversion Rate, Warenkorbwert, Retouren. Daraus ergeben sich Unterziele, wie zum Beispiel 2.000 tägliche Benutzer, eine Conversion Rate von mindestens 1% (was übrigens ein guter Standardwert ist), und ein durchschnittlicher Warenkorb von 50€ sowie eine Retourenrate von 0% (was sehr unrealistisch ist, sofern Du kein digitales Produkt verkaufst). Kommst Du nicht auf die 1.000€, so musst Du anhand der genannten KPIs analysieren, warum das so ist. Bei Branding-Seiten hingegen haben wir andere Metriken. Du willst Nutzer, die nicht sofort wieder gehen (siehe Adjusted Bounce Rate oben). Du willst Nutzer, die sich mit Deiner Seite auseinander setzen, also könnten Time on Site oder Pages per Visit gute Metriken sein. Wenn Du vor allem Nutzer erreichen möchtest, die Dich noch nicht kennen, so ist die Metrik Anzahl Neuer Nutzer interessant. Aber auch hier: Setze Dir Ziele. Wenn Du keine Ziele hast, dann ist jede Zahl egal. Sind 300.000 Besucher gut oder wenig? Ist ein Wachstum von 2% gut oder nicht so gut? Komplett egal, wenn Du keine Ziele hast.
Das Standard-Dashboard von Google Analytics ist relativ sinnfrei. Was sagt das Verhältnis von neuen zu wiederkehrenden Nutzern aus? Was machst Du mit dieser Information? Ganz ehrlich: Mit keiner der im Standard-Dashboard aufgeführten Informationen kannst Du tatsächlich etwas anfangen. Auf ein richtiges Dashboard gehören die tatsächlich wichtigen KPIs. Nutze die Galerie (in Google Analytics). Viele Probleme sind schon von anderen Nutzern gelöst worden.
Web Analytics (wie auch Datenanalyse generell) beginnt mit einer Frage. Die Antwort ist nur so gut wie Deine Frage. Beispiele für gute Fragen: Welcher Akquise-Kanal bringt mir am meisten Umsatz (und, viel wichtiger, lohnt es sich mehr davon haben)? Was ist mit den Kanälen los, die weniger Umsatz bringen? Welche demographischen Zielgruppen “funktionieren” (je nach Ziel) am besten, und welche Inhalte passen nicht für diese Zielgruppen? Liest meine Zielgruppe die Texte der Website bis zum Ende? Welche Elemente meiner Webseite erhöhen die Wahrscheinlichkeit, dass ein Benutzer bounced? An den Fragen sieht man schon, dass Web Analytics keine einmalige Angelegenheit ist, sondern kontinuierlich erfolgen muss.
Segmentierung ist das Killer-Feature in der Web-Analyse. Fast jede Fragestellung kann durch Segmentierung beantwortet werden. Beispiel: Segmentierung nach Mobil versus Desktop, Demographien, Akquise-Kanälen. Ohne Segmentierung ist Analytics ein zahnloser Tiger.
Und zum Abschluss das Killer-Basic: Du willst keine Daten. Was Du willst sind Informationen, mit deren Hilfe Du entscheiden kannst, was Du tun mußt. Analytics bietet Dir Daten, daraus ziehst Du Informationen, und daraus entstehen Aktionen. Daten -> Information -> Aktion, das ist das absolute Analytics-Mantra. Wenn es keine Aktion gibt, dann brauchst Du die Daten auch nicht. Mein ehemaliger Kollege Avinash nutzt dafür den So what-Test. Wenn Du nach dreimaligem Fragen von “Na und?” keine Aktion aus einem Datum hast, dann vergiss den KPI. Ich würde noch einen Schritt weiter gehen: Wenn Du keine Frage hast (siehe Punkt 8), aus deren Antwort eine Aktion erfolgt, dann war die initiale Frage falsch.
Diese Liste ist nicht unbedingt vollständig, aber mit diesen 10 Punkten kommt man schon verdammt weit. Feedback immer erwünscht.