Letzten Monat hatte ich noch positiv über Scalable Capital geschrieben, der November hat allerdings dafür gesorgt, dass ich vom Scalable Capital-Promoter zum Detractor geworden bin, um den NPS-Jargon zu verwenden.
Künstliche Intelligenz bezieht sich auf das breite Feld der Informatik, das Maschinen die Fähigkeit gibt, Aufgaben auszuführen, die menschliche Intelligenz erfordern. Ein Beispiel im Marketing ist die Entwicklung von intelligenten Chatbots, die Kundenanfragen automatisch beantworten.
Machine Learning
Machine Learning ist ein Teilbereich der KI, der Maschinen befähigt, aus Daten zu lernen und sich anzupassen, ohne explizit programmiert zu werden. In der Marketingwelt wird Machine Learning beispielsweise genutzt, um Kundentrends vorherzusagen und personalisierte Werbeinhalte zu erstellen.
Data Mining
Data Mining ist der Prozess des Entdeckens von Mustern in großen Datensätzen. Es ist ein wichtiger Teil der Data Science und wird im Marketing eingesetzt, um beispielsweise Kundensegmente zu identifizieren und Zielgruppen besser zu verstehen.
Data Science
Data Science ist das Feld, das Techniken aus Statistik, Machine Learning und Datenanalyse kombiniert, um Erkenntnisse aus Daten zu gewinnen.
Statistik
Statistik ist die Grundlage für Data Science und Machine Learning. Sie befasst sich mit Methoden zur Analyse und Interpretation von Daten. Im Marketingkontext wird Statistik verwendet, um Kundentrends zu analysieren und Hypothesen zu testen, wie z.B. bei A/B-Tests. Böse Zungen behaupten, dass Data Science einfach nur Statistik im neuen Gewand sei. Allerdings ist Data Science eher eine Kreuzung von Statistik und Informatik, da hier auch große Datenmengen bearbeitet werden.
Überlappungen und Unterschiede
Überlappungen: Machine Learning ist ein Teilbereich der KI und wird in der Data Science angewendet. Sowohl Data Mining als auch Machine Learning nutzen statistische Methoden.
Unterschiede: Während KI ein breites Feld mit verschiedenen Anwendungen ist, konzentriert sich Machine Learning spezifisch auf das Lernen aus Daten. Data Science vereint diese Techniken, um datengetriebene Erkenntnisse zu gewinnen.
Ich bin seit sieben Jahren Kunde bei Scalable Capital, zunächst bei dem für mich eher enttäuschenden RoboAdvisor, seit zwei Jahren aber zufriedener Kunde des Prime Brokers.
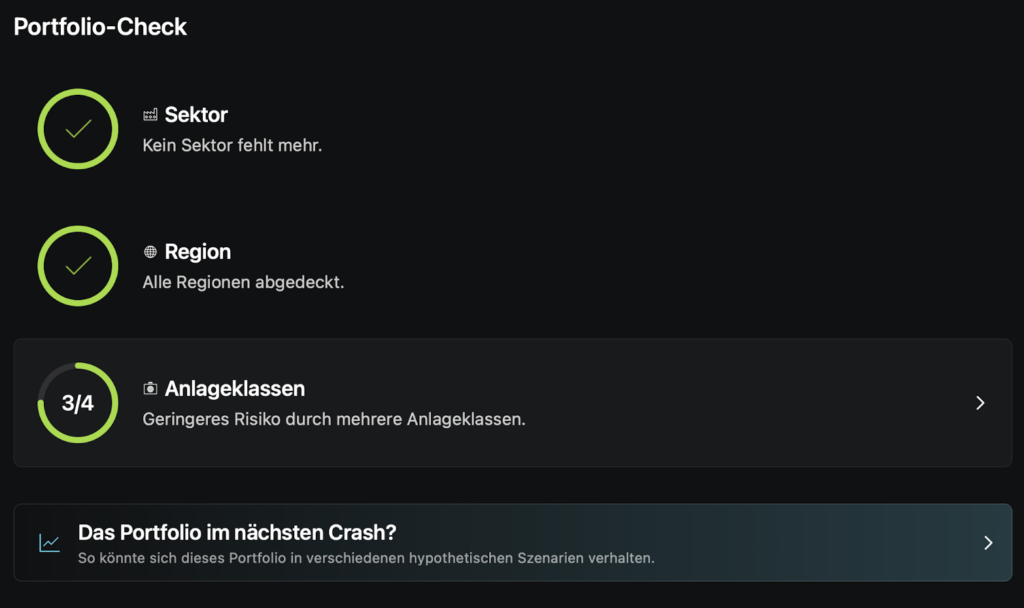
Diese Woche habe ich neue Funktionen entdeckt, zunächst ein Teil davon in der Desktop App, in der Web App sieht man aber schon alles, was Neues angeboten wird. Die neue Funktion nennt sich Insights und basiert auf Daten von BlackRock. Damit das funktioniert werden die Portfoliodaten anonymisiert zu BlackRock geschickt. Zunächst einmal gibt es einen Portfolio Check, wo geprüft wird, wie stark das Portfolio diversifiziert wird.
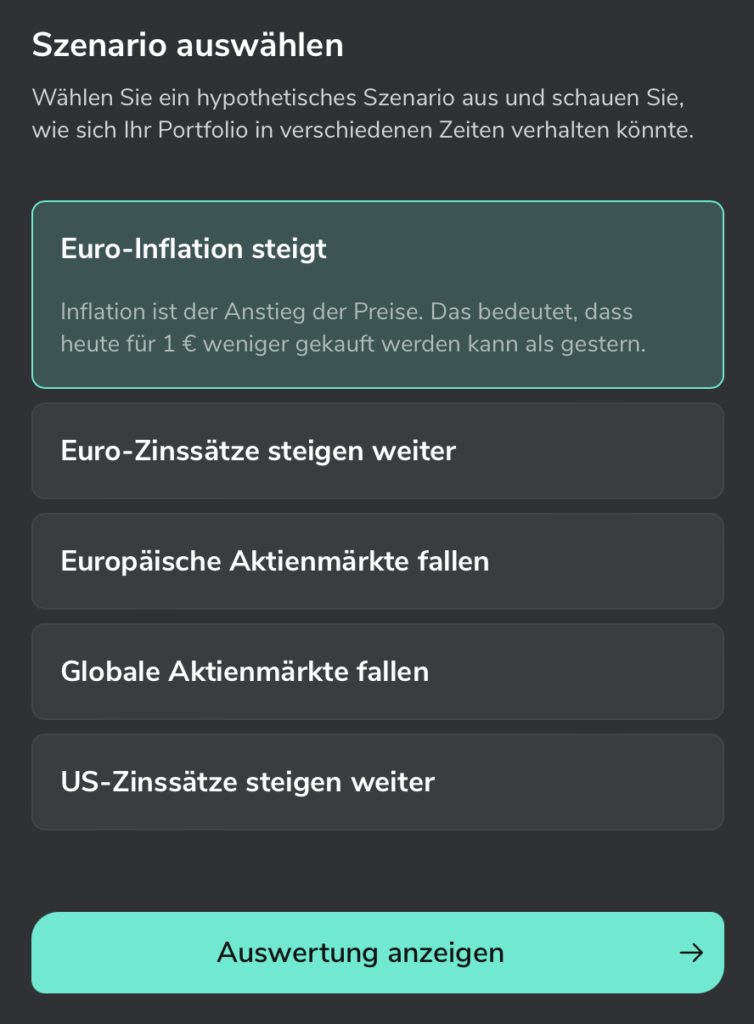
Allerdings wird hier nicht geprüft, wie die Gewichtung ist. Ich habe, nachdem ich diese Grafik gesehen hatte, ein bisschen in eine Anleihe investiert, und schon war der Ring voll. Als nächstes ist eine Crash-Simulation zu sehen, wo man mehrere Szenarien auswählen kann. Die globalen Aktienmärkte fallen in dieser Simulation z.B. um 10%, wobei ich bisher dachte, dass man erst ab 30% von einem Crash sprechen würde.
In so einem Szenario würde mein Portfolio stärker leiden als der Benchmark:
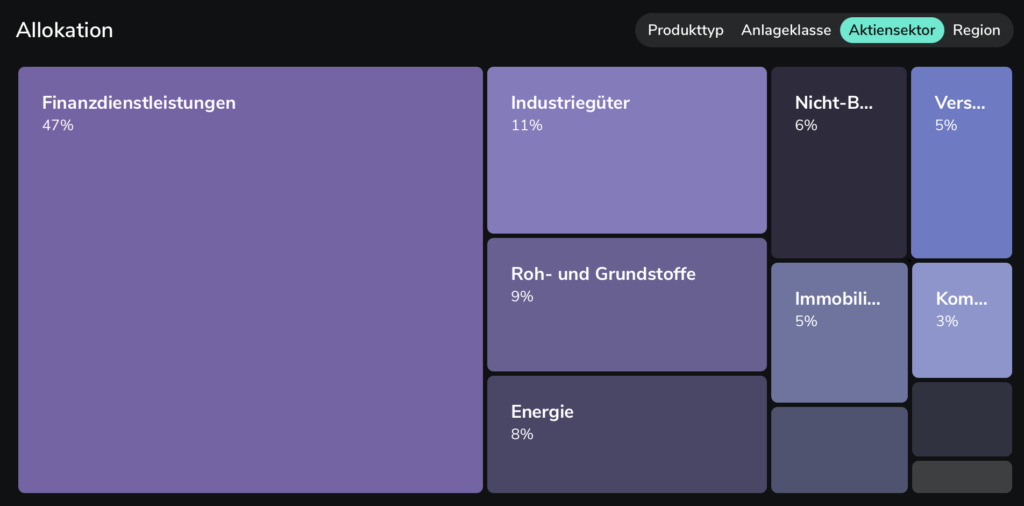
Die nächste neue Funktion ist die Analyse der Allokation des Portfolios in Bezug auf Branchen, Regionen etc:
Bei mir sieht das so aus, als ob ich Finanzdienstleistungen generell übergewichtet hätte, aber tatsächlich ist das nur auf den ersten Blick so. Durch die Dividenden-Treiber Hercules und Ares Capital sieht das größer aus als es eigentlich sein sollte. Dann gibt es noch diese wunderbare Analyse der Unternehmensarten:
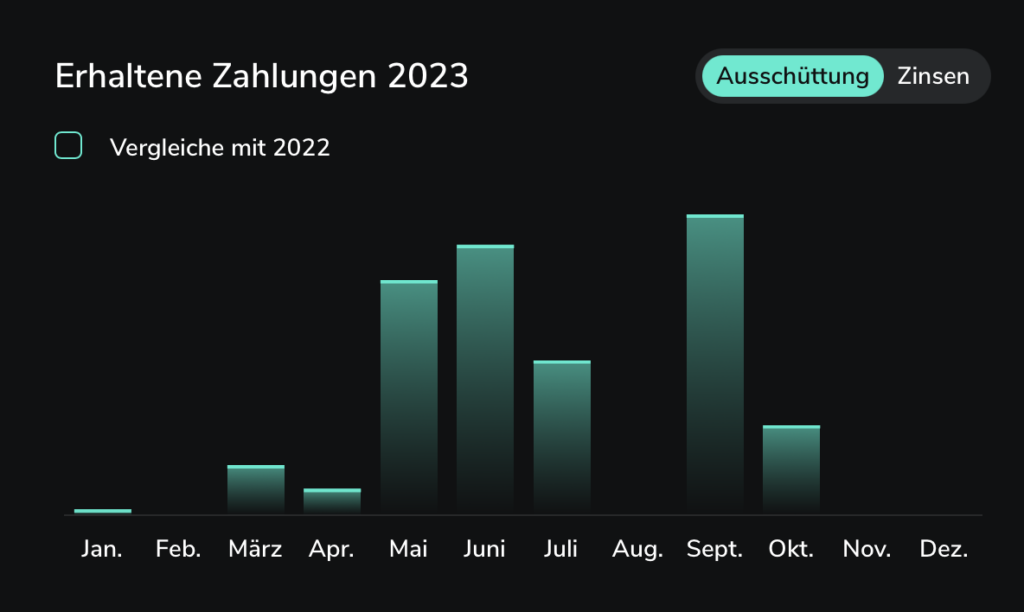
Sowas habe ich bisher vor allem bei ExtraETF gesehen. Und dann, für mich eigentlich am Spannendsten, die Dividenden, denn ich verfolge eine Dividendenstrategie:
Hier würde ich mir wünschen, dass man auch eine Projektion in die Zukunft sehen könnte wie bei ExtraETF, wenngleich man dort auch nur die nächsten Monate im gleichen Kalenderjahr sieht. Aber so sehe ich halt besser, ob ich mich gerade auf dem richtigen Weg befinde oder nicht. Was mir halt an extraETF nicht gefällt ist die wacklige Verbindung zu Scalable. Manchmal geht sie, manchmal nicht. Deswegen bin ich dort auch kein Abonnent mehr.
Scalable nimmt solchen Tools wie ExtraETF, getQuin und DivvyDiary das Marktpotential, wenn sie weiter solche Funktionen einbauen. Für mich aber noch mehr ein Grund, bei Scalable zu bleiben. Sicherlich könnten diese Funktionen noch intelligenter werden und Anleger wie mich, die keinen teuren Roboadvisor nutzen wollen, noch stärker unterstützen bei der Auswahl der Anlagen.
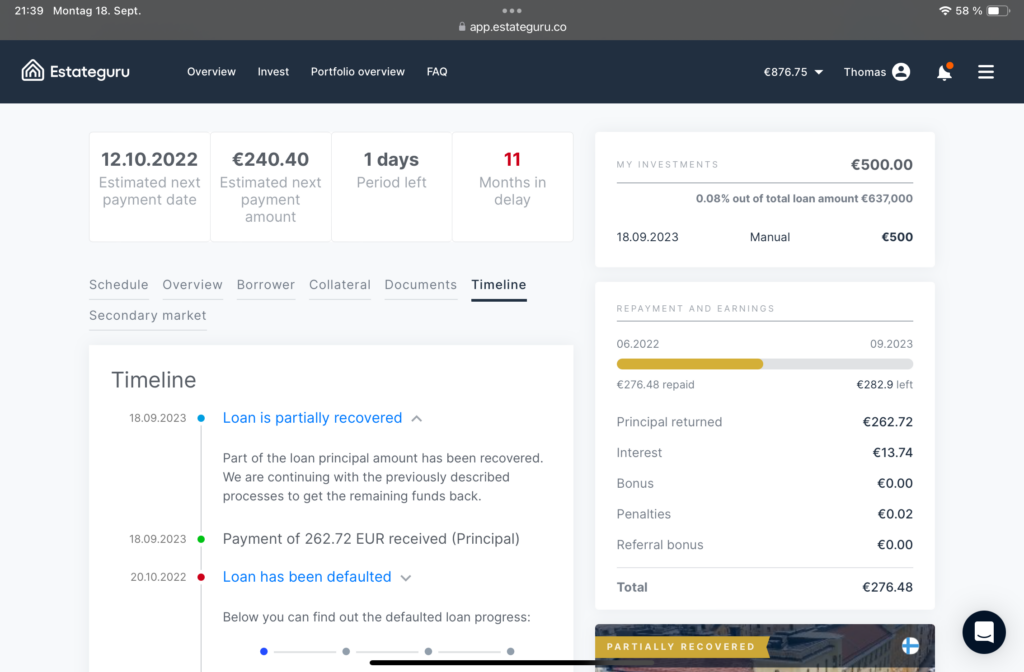
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
repaid <- filter(data, Status == "Repaid")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
Interest Rate`
in_default <- filter(data, Status == "In Default")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
cat("P-value for Repaid group:", shapiro_test_repaid$p.value, "\n")
## P-value for Repaid group: 1.143358e-08
cat("P-value for In Default group:", shapiro_test_in_default$p.value, "\n")
## P-value for In Default group: 6.078673e-05
Die p-Werte sind signifikant (unter 0,05), was darauf hinweist, dass die Daten nicht normalverteilt sind. Darum der Mann-Whitney-U-Test verwendet, ein nichtparametrischer Test, um die Zinssätze der beiden Gruppen zu vergleichen.
wilcox_test <- wilcox.test(repaid, in_default, alternative = "two.sided")
cat("P-value for Mann-Whitney U test:", wilcox_test$p.value, "\n")
## P-value for Mann-Whitney U test: 6.66547e-08
Der p-Wert ist signifikant, also unter 0,05, was darauf hinweist, dass es einen signifikanten Unterschied in den Zinssätzen zwischen den zurückgezahlten und den in Verzug geratenen Darlehen gibt. Dies ist nun über das ganze Portfolio geschehen. Wie sieht das pro Land aus?
countries <- unique(data$Country)
# Function to analyze each country
analyze_country <- function(country) {
cat("Analyse für", country, ":\n")
# Filter data by country and status
data_df <- data %>% filter(Country == country) %>% filter(Status %in% c("Repaid", "In Default"))
# Check if there is enough data for both categories
if (nrow(data_df) > 0 & length(unique(data_df$Status)) > 1) {
repaid <- data_df %>% filter(Status == "Repaid") %>% select(`Interest Rate`) %>% unlist()
in_default <- data_df %>% filter(Status == "In Default") %>% select(`Interest Rate`) %>% unlist()
test <- wilcox.test(repaid, in_default, exact = FALSE)
cat("Mann-Whitney U Test-Ergebnis: W =", test$statistic, ", p-value =", test$p.value, "\n\n")
} else {
cat("Nicht genug Daten für die Analyse.\n\n")
}
}
# Analyze each country
for (country in countries) {
analyze_country(country)
}
## Analyse für Estonia :
## Mann-Whitney U Test-Ergebnis: W = 77 , p-value = 0.02871484
##
## Analyse für Germany :
## Mann-Whitney U Test-Ergebnis: W = 101 , p-value = 0.5058534
##
## Analyse für Lithuania :
## Mann-Whitney U Test-Ergebnis: W = 224.5 , p-value = 3.126943e-06
##
## Analyse für Finland :
## Mann-Whitney U Test-Ergebnis: W = 54 , p-value = 0.8649381
##
## Analyse für Spain :
## Nicht genug Daten für die Analyse.
##
## Analyse für Portugal :
## Nicht genug Daten für die Analyse.
##
## Analyse für Latvia :
## Mann-Whitney U Test-Ergebnis: W = 12 , p-value = 0.04383209
Tatsächlich ist der Unterschied in Deutschland nicht signifikant. Ich war hier also doch nicht so gierig, wie ich dachte 🙂
Was, wenn ich in alle Kredite nur 50 Euro investiert hätte und nicht manchmal sehr viel mehr? Wie stünde ich heute da?
Hier sieht man schon sehr deutlich, dass ich mit meiner Strategie, bei einigen Projekten mehr auszugeben, auf die Nase geknallt bin. Es wäre besser gewesen, ausgewogener und diversifizierter zu investieren. Genau das mache ich nun anders.
Zunächst einmal: Es ist natürlich löblich, dass Estateguru kontinuierlich Updates an die Anleger gibt, die in deutsche Projekte investiert haben. Dass der Chief Risk Officer aber rund um die Uhr im Einsatz ist, verstößt sicherlich auch in Estland gegen Gesetze und ist wahrscheinlich auch nicht gesund für den Menschen.
Es ist wieder an der Zeit, ein Update zu meinen Erfahrungen mit Estateguru zu geben. Seit meinem letzten Beitrag, in dem ich berichtete, dass fast 38% meiner Anlagesumme ausgefallen waren, hat sich die Situation weiter verschlechtert. Mittlerweile sind 39,69% , also fast 40% meines Portfolios ausgefallen. Zu dieser Zahl ist natürlich anzumerken, dass ich momentan in keine neuen Projekte investiere, dementsprechend sinkt die Zahl der investierten Projekte durch abgeschlossene Projekte, während die Zahl der ausgefallenen Projekte zugenommen hat. Waren es im März noch 63 ausgefallene Kredite, so sind es jetzt 84. Trotz der Tatsache, dass einige Projekte erfolgreich wieder eingeholt wurden, bleibt die Anzahl der ausgefallenen Kredite hoch, da weitere Projekte ausgefallen sind.
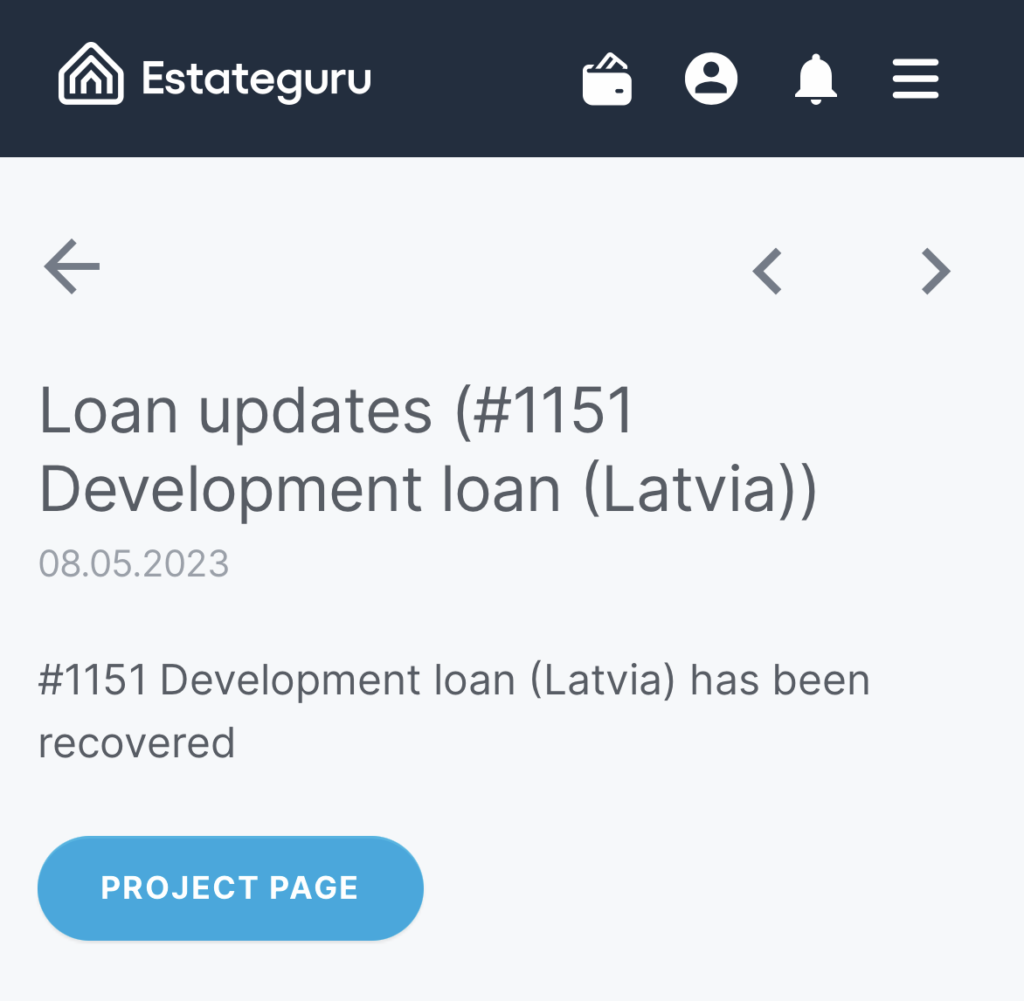
Estateguru hat kürzlich mitgeteilt, dass sie ein deutsches Projekt eingeholt haben. Dies ist eine positive Entwicklung, da es zeigt, dass Estateguru aktiv daran arbeitet, ausgefallene Kredite zurückzugewinnen. Allerdings bleibt abzuwarten, wie sich dies auf mein Portfolio auswirken wird. Und wenn sie für ein eingeholtes Projekt schon eine Mail schreiben, zeigt das für mich auch, dass es noch ungewöhnlich ist, oder?
Ich habe in der Vergangenheit bereits meine Bedenken hinsichtlich der langen Wartezeiten bei der Wiedererlangung von Krediten geäußert. Mein ältester Fall ist heute 600 Tage alt, und es scheint, als ob es hier immer noch keine konkreten Fortschritte gibt. Dies ist natürlich frustrierend und trägt zur Unsicherheit bei. Zwar ist klar, dass es gerade momentan schwierig ist, eine Forderung einzuholen, aber von dem Vertrauen in die Collections-Abteilung ist bei mir momentan wenig über geblieben. Ich investiere derzeit kein neues Geld in Estateguru und ziehe stattdessen Geld ab, wenn Kredite zurückgezahlt werden. Mittlerweile habe ich fast 1/4 des dort investierten Geldes umgeschichtet, allerdings halt nur die Summe, die bisher zurückgezahlt wurde.
Es ist wichtig zu betonen, dass P2P-Investitionen immer ein gewisses Risiko mit sich bringen. Obwohl Estateguru Maßnahmen ergreift, um das Risiko zu minimieren, wie z.B. die Durchführung von Due-Diligence-Prüfungen und die Verwendung von Immobilien als Sicherheiten, gibt es keine Garantie dafür, dass Kredite nicht ausfallen. Meine Strategie momentan ist zu schauen, ob sie es hinbekommen, dass sie die in Deutschland ausgefallenen Kredite schneller einholen, dann würde ich das zurückgezahlte Geld dort wieder investieren.
Nur zur Erinnerung, die 4%-Regel ist sowas wie das heilige Gesetz in der FIRE-Bewegung (Financial Indepence, Retire Early). Hat man eine Million Euro gespart und entnimmt man jedes Jahr 4%, also 40.000 Euro im ersten Jahr, dann wird davon ausgegangen, dass einem nie das Geld ausgeht, Inflation mit eingerechnet. Umgekehrt heißt es in der Community auch, dass man das 25-fache dessen angespart haben sollte, was man jährlich zum Leben braucht, wenn man davon leben will.
Was mich an der Regel stört: Wenn die Börse mal runter geht und ich dann 4% verkaufen muss, habe ich weniger als das, was ich jährlich brauche. Abgesehen davon basiert die 4%-Regel auf eine Studie von Bengen, die auf einem ganz speziellen Portfolio basiert und einem Zeitraum von 30 Jahren. Nur wenige Börsen kommen nah an die 4% dran, über 50 Jahre aber zum Beispiel gibt es kaum Daten (siehe auch das Video von Ben Felix). Will man mit 40 in Rente gehen und lebt bis 95, dann wären nur 2,2% eine sichere Regel. Basierend auf dem Buch von Fisker funktioniert das mit dem Early Retirement auch nur dann, wenn man relativ sparsam lebt. Aber das ist eine andere Geschichte. Manche vertrauen auf thesaurierende MSCI-ETFs, was wahrscheinlich in jungen Jahren viel Sinn ergibt. Ich hatte mein Glück eine Zeit lang in RoboAdvisorn gesucht, davon bin ich mittlerweile ab. Growney hatte mir sogar eine falsche Steuerbescheinigung ausgestellt und erst nach mehrmaligem Insistieren bei der Bank habe ich eine korrekte Bescheinigung erhalten. Auch von meinem Finanzberater habe ich mich mittlerweile getrennt. Egal wo, eine Gebühr wird immer kassiert, auch wenn Verlust gemacht wird. Mittlerweile habe ich mich auf den Broker bei Scalable fokussiert, die Monatsgebühr wird leicht durch die Tagesgeldzinsen kompensiert.
Auf den ersten Blick sah für mich anstatt der 4%-Regel eine Dividenden-Strategie attraktiv aus: ETFs mit Dividenden-Aristokraten, die in den letzten X Jahren die Dividende konsequent bezahlt oder sogar gesteigert haben. Auf den zweiten Blick hat diese Strategie aber auch Nachteile: Firmen, die eine Dividende zahlen, mindern im Prinzip ihren Unternehmenswert; Firmen wie Google, die keine Dividende zahlen, können die nicht gezahlte Dividende in Wachstum investieren, was wiederum den Börsenkurs ankurbelt. Theoretisch. Ernst zu nehmen ist in diesem Fall auf jeden Fall das Argument, dass eine Dividende versteuert werden muss, Anleger mit Nicht-Dividenden-Aktien das aber erst tun müssen, wenn sie verkaufen (Anmerkung: Bei thesaurierenden ETFs, die Dividende-zahlende Unternehmen enthalten, ist das etwas anders, hier gibt es eine Vorabpauschale). Sehr gut erklärt das Ben Felix:
Hinzu kommt, dass auch Dividenden nicht sicher sind, selbst bei Dividenden-Aristokraten. Der VanEck Morningstar Developed Markets Dividend Leaders kommt momentan auf eine Dividenden-Rendite von 4.87%. Anders gesagt: Legt man 100.000 Euro an, dann bekommt man 4.870 Euro pro Jahr. Vor Steuern. Die gibts ja auch noch. Nach Steuern wäre man dann bei 3.586 Euro, je nachdem ob man in der Kirche ist oder nicht. Hätte man also durchschnittlich gerne 2.000 Euro an Dividenden im Monat (wobei die ja nicht garantiert sind), dann müsste man mehr als 660.000 Euro investieren, um nach Steuern dieses Dividendeneinkommen zu erhalten. Will man auf diese Summe kommen, so muss man viele Jahre sehr diszipliniert die eingenommenen Dividenden auch wieder investieren 🙂
Vergleichen wir das noch mal mit der 4%-Regel: Hier hätte man bei 1 Million Euro Ersparten 40.000 Euro Auszahlung, nach Steuern sind das 29.450 Euro im Jahr oder 2.454 Euro monatlich. Bei dem oben genannten Fonds müsste man etwas weniger sparen, mit 821.355 Euro wäre man bei derselben Summe. Geht man davon aus, dass man mit verschiedenen Dividenden-Aktien und Fonds auf 5% kommt, wird die Summe noch niedriger, wobei man niemals den Grundstock anfassen muss. Das klingt ja zunächst besser. Aber wenn man Ben Felix folgt, dann hat man vorher nicht von dem ganzen Wachstum des Aktienmarkts profitiert. Anders gesagt, das Portfolio des am ganzen Aktienmarkt teilnehmenden Investors wäre schneller gewachsen, weil auch andere, nicht Dividende zahlende Unternehmen, im Portfolio enthalten gewesen wären.
Wie gewohnt ein Update zu meinen Erfahrungen bei Estateguru. Im März waren noch 30% der Anlagesumme ausgefallen, mittlerweile bin ich bei knapp 38%. Ich weiß nicht ganz, wie Estateguru das rechnet, ich rechne Summe der ausgefallenen Kreditsumme durch die momentan angelegte Kreditsumme.
Allerdings ist auch meine Zahl mit etwas Vorsicht zu genießen, denn momentan investiere ich ja kein Geld in estateguru, d.h. die investierte Summe wird immer weniger, wohingegen die Anzahl der ausgefallenen Kredite immer mehr wird. Waren es im März noch 63 ausgefallene Kredite, so waren es zwischenzeitlich schon 83. Aber, und das ist die erste gute Nachricht seit langer Zeit, es wurden nun auch erste Projekte recovered, so dass ich momentan bei 79 Krediten in Einholung bin. Allerdings sind die ausgefallenen Kredite, die schon etwas länger da liegen, lange nicht mehr aktualisiert worden. Mein ältester Fall ist heute 542 Tage alt. Mehrmals wurde es angeblich zur Auktion angesetzt. Passiert ist ansonsten nix.
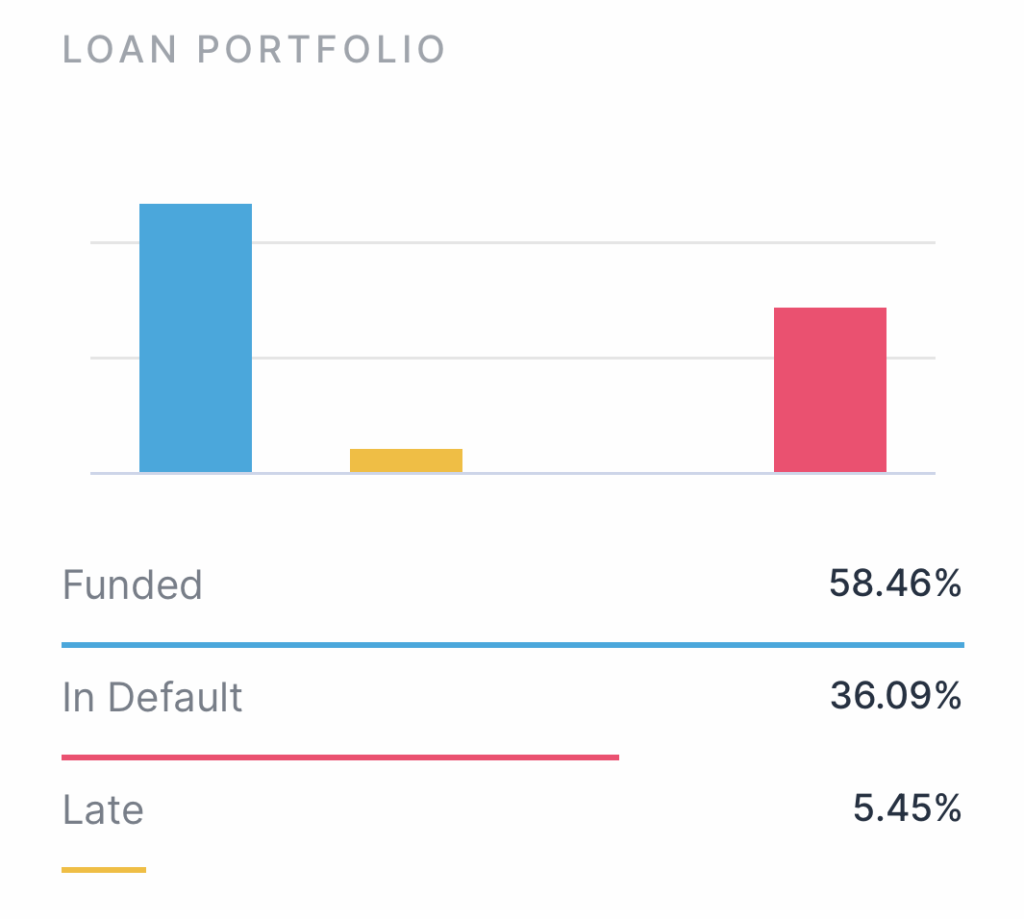
Schaue ich nur auf die Anzahl der ausgefallen Kredite in Bezug auf die gerade aktiven Kredite, so komme ich auf 27,5% ausgefallene Kredite. Dass die ausgefallene Kreditsumme höher ist, liegt daran, dass dort Kredite sind, in die ich mehr investiert hatte. Das sieht man auch an der folgenden Tabelle, die ich aus den Daten von Estateguru generiert habe (cool, dass man sich da fast jeden Bericht als CSV-Datei herunterladen kann):
Wenn ich mir den gegenwärtigen Immobilienmarkt in Deutschland ansehe, dann mache ich mir etwas Sorgen, dass die in Deutschland investierten Summen schnell wieder eingeholt werden können. Allerdings ist die LTV (Loan to Value, Kredit versus Wert-Ratio) bei den meisten Projekten sehr niedrig, also selbst wenn es bei Versteigerungen nur die Hälfte gäbe, wäre ich noch im grünen Bereich. Aber wahrscheinlich gibt es in den nächsten Monaten genug Zwangsversteigerungen. Estateguru beschreiben den Prozess sehr genau, auch differenziert nach Land. Gerade in Deutschland kann mehr als ein Jahr vergehen, bis irgendwas passiert. Investoren auf der Estateguru-Plattform müssen sich also immer darauf einstellen, dass sie nicht kurzfristig an ihr Geld kommen können.
Ich nutze seit Mitte der 90er Jahre fast ausschließlich Apple-Produkte. Hin und wieder habe ich Debatten über die Vor- und Nachteile von Apple-Produkten im Vergleich zu ihren Konkurrenten, insbesondere in Bezug auf den Preisunterschied. Und natürlich stellt sich die Frage, ob das überhaupt zusammenpasst, Minimalismus und die Nutzung von Apple-Produkten. Ambivalenz zwischen Designkult und Konsumwiderspruch.


 Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht. Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
 Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an: