Estateguru: Erstes Projekt teileingeholt + Explorative Datenanalyse
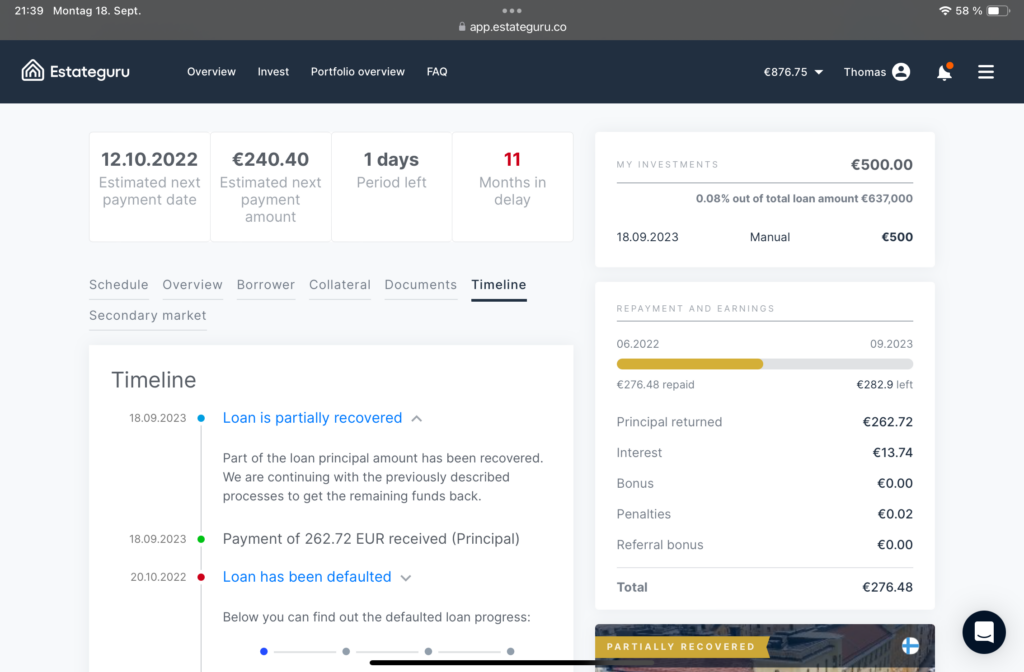
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
repaid <- filter(data, Status == "Repaid")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
Interest Rate`
in_default <- filter(data, Status == "In Default")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
cat("P-value for Repaid group:", shapiro_test_repaid$p.value, "\n")
## P-value for Repaid group: 1.143358e-08
cat("P-value for In Default group:", shapiro_test_in_default$p.value, "\n")
## P-value for In Default group: 6.078673e-05
Die p-Werte sind signifikant (unter 0,05), was darauf hinweist, dass die Daten nicht normalverteilt sind. Darum der Mann-Whitney-U-Test verwendet, ein nichtparametrischer Test, um die Zinssätze der beiden Gruppen zu vergleichen.
wilcox_test <- wilcox.test(repaid, in_default, alternative = "two.sided")
cat("P-value for Mann-Whitney U test:", wilcox_test$p.value, "\n")
## P-value for Mann-Whitney U test: 6.66547e-08
Der p-Wert ist signifikant, also unter 0,05, was darauf hinweist, dass es einen signifikanten Unterschied in den Zinssätzen zwischen den zurückgezahlten und den in Verzug geratenen Darlehen gibt. Dies ist nun über das ganze Portfolio geschehen. Wie sieht das pro Land aus?
countries <- unique(data$Country)
# Function to analyze each country
analyze_country <- function(country) {
cat("Analyse für", country, ":\n")
# Filter data by country and status
data_df <- data %>% filter(Country == country) %>% filter(Status %in% c("Repaid", "In Default"))
# Check if there is enough data for both categories
if (nrow(data_df) > 0 & length(unique(data_df$Status)) > 1) {
repaid <- data_df %>% filter(Status == "Repaid") %>% select(`Interest Rate`) %>% unlist()
in_default <- data_df %>% filter(Status == "In Default") %>% select(`Interest Rate`) %>% unlist()
test <- wilcox.test(repaid, in_default, exact = FALSE)
cat("Mann-Whitney U Test-Ergebnis: W =", test$statistic, ", p-value =", test$p.value, "\n\n")
} else {
cat("Nicht genug Daten für die Analyse.\n\n")
}
}
# Analyze each country
for (country in countries) {
analyze_country(country)
}
## Analyse für Estonia :
## Mann-Whitney U Test-Ergebnis: W = 77 , p-value = 0.02871484
##
## Analyse für Germany :
## Mann-Whitney U Test-Ergebnis: W = 101 , p-value = 0.5058534
##
## Analyse für Lithuania :
## Mann-Whitney U Test-Ergebnis: W = 224.5 , p-value = 3.126943e-06
##
## Analyse für Finland :
## Mann-Whitney U Test-Ergebnis: W = 54 , p-value = 0.8649381
##
## Analyse für Spain :
## Nicht genug Daten für die Analyse.
##
## Analyse für Portugal :
## Nicht genug Daten für die Analyse.
##
## Analyse für Latvia :
## Mann-Whitney U Test-Ergebnis: W = 12 , p-value = 0.04383209
Tatsächlich ist der Unterschied in Deutschland nicht signifikant. Ich war hier also doch nicht so gierig, wie ich dachte 🙂
Was, wenn ich in alle Kredite nur 50 Euro investiert hätte und nicht manchmal sehr viel mehr? Wie stünde ich heute da?
Hier sieht man schon sehr deutlich, dass ich mit meiner Strategie, bei einigen Projekten mehr auszugeben, auf die Nase geknallt bin. Es wäre besser gewesen, ausgewogener und diversifizierter zu investieren. Genau das mache ich nun anders.
 Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht. Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
 Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
