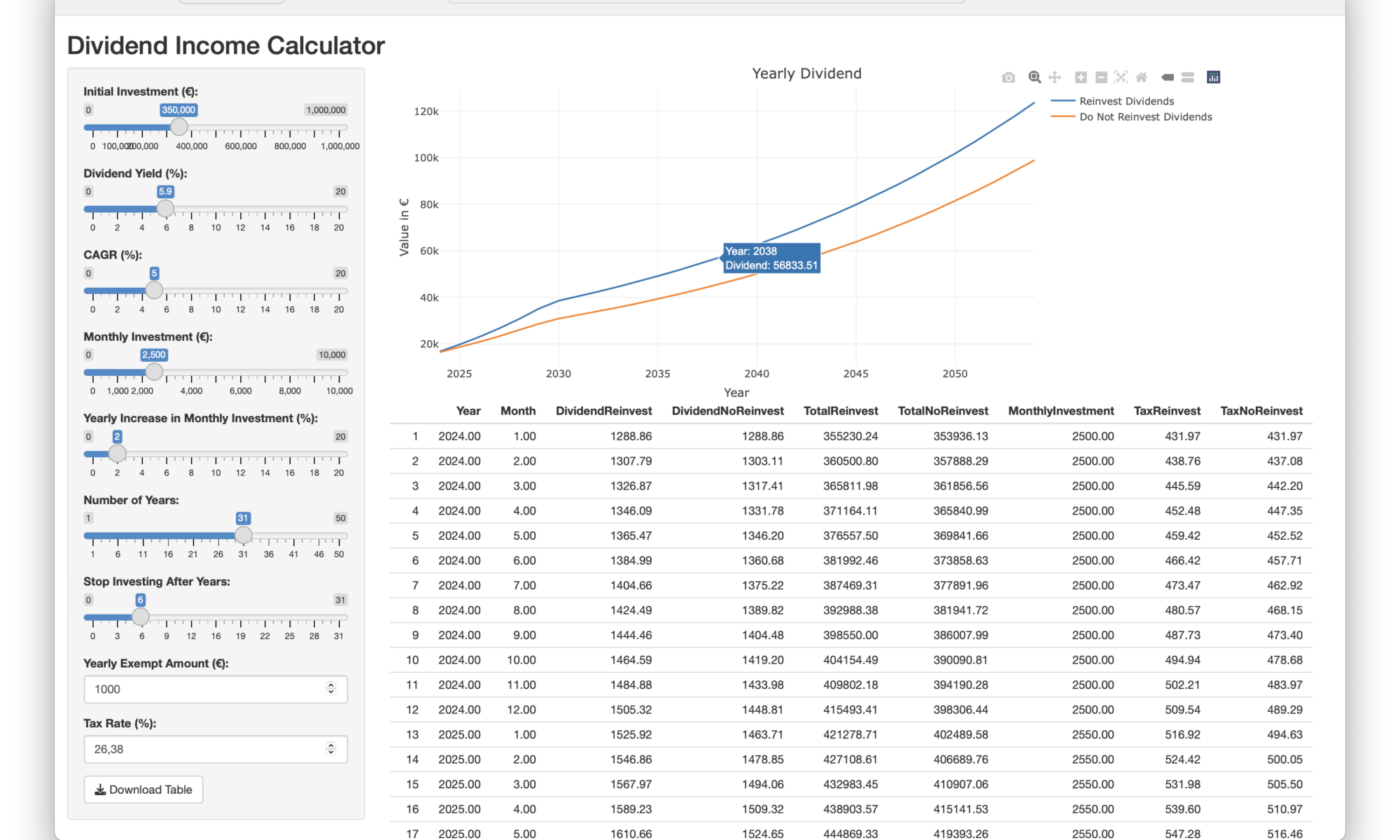
Künstliche Intelligenz (KI)
Künstliche Intelligenz bezieht sich auf das breite Feld der Informatik, das Maschinen die Fähigkeit gibt, Aufgaben auszuführen, die menschliche Intelligenz erfordern. Ein Beispiel im Marketing ist die Entwicklung von intelligenten Chatbots, die Kundenanfragen automatisch beantworten.
Machine Learning
Machine Learning ist ein Teilbereich der KI, der Maschinen befähigt, aus Daten zu lernen und sich anzupassen, ohne explizit programmiert zu werden. In der Marketingwelt wird Machine Learning beispielsweise genutzt, um Kundentrends vorherzusagen und personalisierte Werbeinhalte zu erstellen.
Data Mining
Data Mining ist der Prozess des Entdeckens von Mustern in großen Datensätzen. Es ist ein wichtiger Teil der Data Science und wird im Marketing eingesetzt, um beispielsweise Kundensegmente zu identifizieren und Zielgruppen besser zu verstehen.
Data Science
Data Science ist das Feld, das Techniken aus Statistik, Machine Learning und Datenanalyse kombiniert, um Erkenntnisse aus Daten zu gewinnen.
Statistik
Statistik ist die Grundlage für Data Science und Machine Learning. Sie befasst sich mit Methoden zur Analyse und Interpretation von Daten. Im Marketingkontext wird Statistik verwendet, um Kundentrends zu analysieren und Hypothesen zu testen, wie z.B. bei A/B-Tests. Böse Zungen behaupten, dass Data Science einfach nur Statistik im neuen Gewand sei. Allerdings ist Data Science eher eine Kreuzung von Statistik und Informatik, da hier auch große Datenmengen bearbeitet werden.
Überlappungen und Unterschiede
- Überlappungen: Machine Learning ist ein Teilbereich der KI und wird in der Data Science angewendet. Sowohl Data Mining als auch Machine Learning nutzen statistische Methoden.
- Unterschiede: Während KI ein breites Feld mit verschiedenen Anwendungen ist, konzentriert sich Machine Learning spezifisch auf das Lernen aus Daten. Data Science vereint diese Techniken, um datengetriebene Erkenntnisse zu gewinnen.