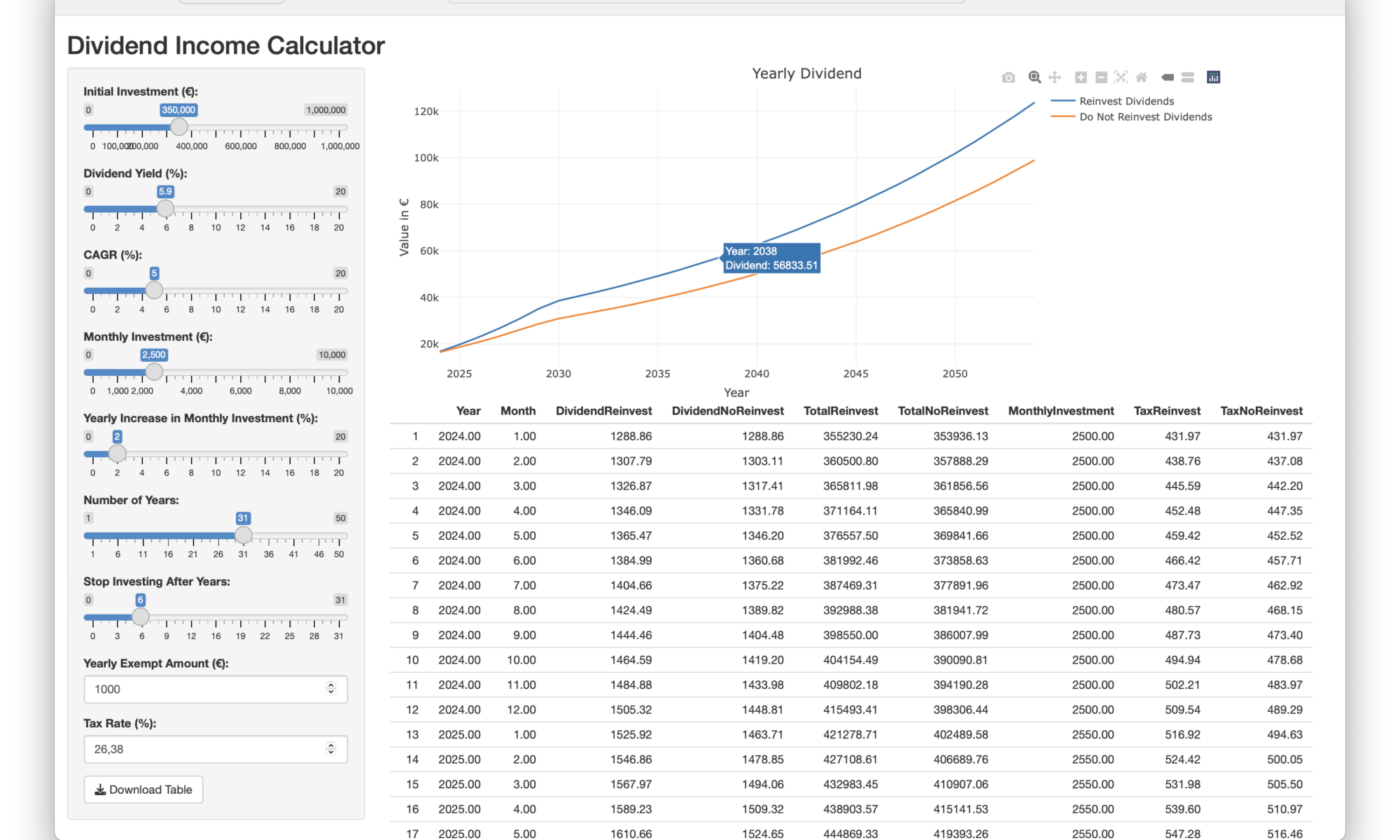
Einige Tools im Netz bieten die Möglichkeit, dass man sieht, wie viele Dividenden wohl auf einen zukommen werden. extraETF bietet zum Beispiel ein Tool, bei dem man sehen kann, wie die Dividenden aussehen könnten bei einer angenommenen Wachstumsrate (CAGR) und einer bestimmten Anzahl von Jahren und Vermögenszuwächsen.
Was ich bisher nicht gesehen habe, ist ein Tool, das von einem Portfolio ausgehend mit einer angenommenen CAGR und Dividendenrendite sowie einer weiteren Bespannung das Dividendenwachstum berechnet und auch noch die Steuern inkludiert. Genau so ein Tool habe ich geschrieben.
Das Problem mit dem oben genannten Code liegt in der Verwendung des Pipe-Operators (|>), direkt vor ggplot. ggplot2 wird nicht nativ mit der R-spezifischen Pipe (|>) unterstützt, wie hier verwendet. Allerdings funktioniert ggplot2 nahtlos mit dem Magrittr-Pipe (%>%) aus dem dplyr-Paket. Hier ist die korrekte Verwendung:
Hier stellt der Punkt (.) die Daten dar, die von mtcars in ggplot gepiped werden, und Sie müssen ihn als data-Argument in der ggplot-Funktion spezifizieren.
Vor 3 Jahren, zum 15. Geburtstag dieses Blogs, war ich umgezogen von WordPress zu Hugo. Superschnelle Seiten, alles in R, eigentlich eine coole Sache. Aber in der Realität war es nicht so cool. Ich brauchte immer eine R-Umgebung, die ich nicht immer hatte. Git machte mich manchmal wahnsinnig. Und manche Probleme waren einfach nicht nachzuvollziehen. Und so bin ich jetzt wieder umgezogen. Vielleicht kommen nun auch die Rankings wieder zurück, die ich auch verloren hatte nach dem Umzug.
Schon wieder ein neues MacBook? War das Air nicht gerade erst neu gekauft? Ja, es hat sogar noch Garantie, und dann lohnt es sich umso mehr, das Ding zu verkaufen. Ich bin ein großer Fan des Air-Formfaktors, und mit den Pro-Modellen habe ich mich nie anfreunden können. Aber die Limitierung auf 16GB Arbeitsspeicher des MacBook Air war damals schon schwer zu akzeptieren, nur Alternativen gab es nicht. Und so habe ich an dem Abend, an dem die neuen MacBook Pros mit M1 Pro und M1 Max vorgestellt wurden, auch gleich ein Gerät bestellt, ein MacBook Pro 14“ M1 Max mit 10 Kernen, 24 GPU-Kernen, 16-Kern Neutral Engine, 64 GB Arbeitsspeicher (!!!) und einer 2 TB Platte. Mein MacBook Air hat 16 GB RAM und halt den ersten M1-Prozessor mit 8 Kernen.
Warum ein Rechner mit 64 GB Arbeitsspeicher?
Ich arbeite regelmäßig mit großen Datensätzen, 10, 20, auch mal 50GB große Dateien. Aber auch eine 2GB große Datei kann Ärger machen, je nachdem was man alles für Datentransformationen und Berechnungen anstellt. Das macht auf die Dauer keinen Spaß mit einem Rechner mit wenig Arbeitsspeicher. Zwar hilft mir eine lokale Installation von Apache Spark dabei, mehrere Kerne gleichzeitig zu nutzen, aber der fehlende Arbeitsspeicher ist immer wieder ein limitierender Faktor. Für die weniger technisch Versierten unter meinen Lesern: Daten werden von der Festplatte in den Arbeitsspeicher geladen, und hier bestimmt die Geschwindigkeit der Festplatte, wie schnell das geht, denn eine Festplatte, selbst wenn es eine SSD ist, ist langsamer als der Arbeitsspeicher.
Wenn aber der Arbeitsspeicher nicht ausreicht, ich also zum Beispiel versuche, eine 20 GB große Datei in die 16 GB Arbeitsspeicher zu laden, dann fängt das Betriebssystem an, Objekte aus dem Arbeitsspeicher auf die Festplatte zu verlagern. Also von der Festplatte in den Arbeitsspeicher und wieder zurück, nur dass das auf der Festplatte nun als langsamer Arbeitsspeicher gilt. Gleichzeitig Daten auf die Festplatte zu schreiben und zu lesen macht den Rechner auch nicht schneller. Und dazu kommt der Overhead, denn das Programm, das den Arbeitsspeicher benötigt, verlagert die Objekte nicht selbst, sondern das Betriebssystem. Das Betriebssystem benötigt natürlich auch Arbeitsspeicher. Und wenn das Betriebssystem die ganze Zeit auch noch Objekte hin- und her schiebt, dann verbraucht es auch noch CPU-Zeit. Also, zu wenig Arbeitsspeicher bedeutet, dass alles ausgebremst wird.
Zwischendurch hatte ich überlegt, mir selbst ein Cluster zu bauen. Es gibt einige gute Anleitungen im Netz, wie sowas geht mit günstigen Raspberry Pis. Cool aussehen kann das auch. Aber, ich hab wenig Zeit. Ich mache das sogar vielleicht noch mal irgendwann, allein schon weil ich es ausprobieren will. Nur mal zum Nachrechnen: 8 Raspberry Pis mit 8 GB RAM plus Zubehör, da wäre ich wahrscheinlich bei knapp 1.000€ für alles. Plus jede Menge Neues lernen. Aufgeschoben ist nicht aufgehoben.
Ein R-Skript, das auf einem Kern läuft, also nicht parallelisiert wird
Ein R-Skript, dass parallelisiert werden und daher auf einem Cluster laufen kann.
Als Cluster nutze ich Apache Spark, das sich hervorragend lokal nutzen lässt. Für die weniger technisch Versierten: Mit Spark kann ich ein Cluster erstellen, in dem die Rechenaufgaben aufgeteilt und an die einzelnen Nodes zur Verarbeitung geschickt werden. Dadurch werden Aufgaben parallel bearbeitet. Ich kann entweder ein Cluster mit vielen Computern aufbauen, muss die Daten dann über das Netzwerk schicken, oder ich installiere das Cluster lokal und nutze die Kerne meiner CPU als Nodes. Eine lokale Installation hat den großen Vorteil, dass ich keine Netzwerklatenz habe.
Für den ersten Test, ein Skript ohne Parallelisierung, nutze ich einen berühmten Datensatz aus der Suchmaschinengeschichte, die AOL-Daten. 36.389.575 Zeilen, knapp 2 GB groß. Viele Generationen meiner Studierenden haben diesen Datensatz schon bearbeitet. In diesem Skript werden die Suchanfragen auseinander genommen, die Anzahl der Terme pro Suchanfrage bestimmt und Korrelationen berechnet. Natürlich könnte man das auch alles parallelisieren, aber hier nutzen wir eben nur einen Kern.
Für den zweiten Test nutze ich einen knapp 20GB großen Datensatz von Common Crawl (150 Millionen Zeilen und 4 Spalten) und vergleiche ihn mit Daten aus Wikipedia, knapp 2GB. Hier nutze ich dann das oben erwähnte Apache Spark. In meinem M1 Max habe ich 10 Kerne, und auch wenn ich alle nutzen könnte, sollte das Betriebssystem auch noch einen Kern haben, so dass wir hier nur 9 Kerne nutzen. Um es mit dem M1 in meinem MB Air vergleichen zu können, fahren wir auch eine Testvariante, in der das MBP Max dieselbe Anzahl von Kernen nutzt wie das Air.
Wie messe ich? Es existieren mehrere Möglichkeiten, von denen ich die simpelste wähle: Ich schaue mir an, um wie viel Uhr mein Skript startet und wann es endet und berechne die Differenz. Das ist nicht sauber, das ist nicht gut, aber wir werden später sehen, dass die Messfehler hier nicht so die große Rolle spielen.
Ergebnisse: Lohnt es sich?
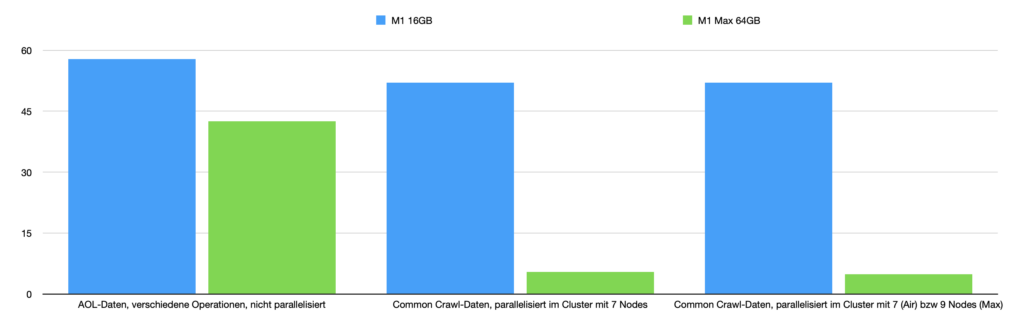
Es kommt drauf an. Der erste Test ist etwas ernüchternd. Denn der größere Arbeitsspeicher scheint hier wenig zu bringen, auch wenn Mutationen des AOL-Datensatzes erstellt und in den Arbeitsbereich geladen werden. Das alte M1 schafft das Skript in 57,8 Minuten, das M1 Max benötigt 42,5 Minuten. Die Daten werden wahrscheinlich durch die schnelleren SSDs zügiger in den Arbeitsspeicher geladen, aber das sind vielleicht ein paar Sekunden Unterschied. Der Rest scheint von der CPU zu kommen. Aber dafür ist der Preis des M1 Max nicht gerechtfertigt (doppelt so viel wie das MacBook Air).
Spannender wird es, wenn ich auf beiden Seiten dieselbe Anzahl von Kernen für ein Cluster verwende und dann ein Spark nutze. Die Unterschiede sind brutal: 52 Minuten für den alten M1 mit 16GB RAM, 5,4 Minuten beim neuen M1 Max mit 64GB RAM. Tatsächlich benötigt der “alte” M1 mit seinem wenigen Arbeitsspeicher viele Minuten, um den großen Datensatz laden zu können, der neue M1 Max mit den 64 GB schafft das in unter 1 Minute. Übrigens lade ich hier keine einfache CSV-Datei, sondern habe bereits einen Ordner mit ganz vielen kleinen Partitionen, so dass die Nodes unabhängig voneinander Daten einlesen können. Es liegt also nicht daran, dass sich die Nodes gegenseitig im Weg stehen beim Einlesen der großen Datei.
Nehme ich dann noch 2 Kerne mehr, also 9, dann bin ich sogar bei unter 5 Minuten. Um es mal anders auszudrücken: Vorher habe ich eine knappe Stunde auf das Ergebnis gewartet, nun bekomme ich es in ca. 5 Minuten. Das ermöglicht mir ein ganz anderes Arbeiten. Denn in der Regel brauche ich diese Ergebnisse wirklich, und es hat einfach genervt, wenn man so lange gewartet und dann die Verbindung zum Spark-Cluster abgerissen ist und man mit leeren Händen da stand. Und ja, dann lohnt sich dieser Rechner.
Einige Dinge habe ich noch nicht hinbekommen. So kann man mit RAPDIS die GPUs nutzen, und da habe ich ausreichend Kerne. Hab ich nicht zum laufen bekommen, vielleicht benötigt man dafür eben eine NVIDIA-Grafikkarte. Auch stellt Apple selbst mit ML Compute die Möglichkeit zur Verfügung, Tensorflow auf GPUs zu nutzen. Momentan habe ich keine Anwendung dafür, aber ausprobieren will ich das auf jeden Fall noch.
Und sonst so?
Ich mag den Formfaktor des MacBook Pros nicht. Der Rechner, den ich am längsten hatte, war ein MacBook Air. Als ich dann eine kurze Affäre mit einem MacBook Pro 16“ hatte, war mir klar, dass ich sofort wechseln würde, wenn es ein neues MacBook Air mit mehr Power gibt. Ich mag die Tastatur nicht. Sie fühlt sich für mich zu groß an, vielleicht auch nur, weil meine Hände anders auf dem Rechner liegen. Das 14“ MacBook Pro ist kaum größer als das 13“er MacBook Air, aber es ist viel dicker, klobiger, schwerer. Es ist nicht so elegant wie ein Air. Das 16“er mochte ich schon kaum irgendwo mit hinnehmen, ich weiß noch nicht, wie es mit diesem Rechner ist.
Der Rechner wird wärmer als mein MacBook Air, das scheint auch eher den Prozessor runterzuschalten, wenn es heiß zu werden droht. Beim MBP kann man den Rechner gerade noch so auf dem Schoß haben, wenn ich 9 von 10 Kernen im Cluster nutze, so heiß wie mein altes i9 MacBook Pro wird es aber nicht. Bei dem Intel 16er konnte ich ohne Witz die Heizung im Raum ausschalten, so viel Hitze kam da raus, und der Lüfter ging ständig. Der Lüfter des 14“er ist leiser, auch wenn er die ganze Zeit an ist.
Der Sound der Lautsprecher ist super. Das Display ist super.
Wäre ich mit einem Linux-Rechner nicht viel günstiger dabei gewesen? Ja, auf jeden Fall. Aber ich denke auch immer mehr darüber nach, wie viel Lebenszeit ich dafür aufbringen muss, mit einer Lösung zu arbeiten, die weitere Konfiguration erfordert und meine Prozesse nicht so gut unterstützt. Siehe oben, die Idee mit dem Cluster will ich immer noch verfolgen, nur fehlt mir momentan einfach die Zeit dafür.
Übrigens, mein erstes MacBook 1996 hieß noch PowerBook und hatte 4 MB RAM. Das war damals schon gigantisch viel. Und das PowerBook 5300 mit seinem 640×480 Graustufendisplay kostete damals auch um die 4.000 DM, wenn ich mich recht erinnere.
Ein allgemeines Buch über die Grundlagen der Datenanalyse mit R+; ein dicker Brocken, eher als allgemeine Einführung gedacht. Ich würde aber immer eher das Buch von Hadley empfehlen
Als generelle Einführung in die Statistik empfehle ich The Art of Statistics+ oder Naked Statistics+, beides sehr gute und unterhaltsame Bücher (nicht nur für Statistiker)
Zum 15. Geburtstag dieses Blogs gibt es nicht nur ein Redesign, sondern auch neue Technik unter der Motorhaube:
Blogdown ermöglicht es, mit R eine Website auf Basis von Hugo zu erstellen. So kann ich mit meiner Lieblingssprache mein Blog gestalten und muss nicht jedes Mal überlegen, wie ich meinen R-Code oder die Grafiken in WordPress kriege.
Der Output ist pures HTML, was die Abhängigkeit von Datenbanken, WordPress-Plugins etc zum einen abschafft und zum andern, und das ist für mich extrem wichtig, eine superschnelle Auslieferung von Inhalten ermöglicht (siehe Screenshot von den Google PageSpeed Insights unten bei den Tests mit meinem Preview-Server). Ich bekomme nun auch keine Mails mehr, weil irgendjemand versucht hat, in meinen Server einzudringen, oder weil der Datenbankserver zu viel Arbeitsspeicher benötigt.
Der Workflow ist fast vollautomatisch: Ich schreibe meine Texte in RStudio, committe einen Stand auf GitHub, und von da aus wird automatisch auf meinen Webserver deployed. Wenn mir was misslingt, gehe ich halt auf einen früheren Commit zurück. Continuous Deployment heißt das auf wohl auf Neudeutsch.
2005 hatte ich die erste Version des Blogs mit Movable Type realisiert. Damals wurden auch schon HTML-Seiten produziert, die dann nicht mehr in Echtzeit bei einem Seitenaufruf generiert werden mussten. Ich weiß nicht mehr, wann und warum ich auf WordPress wechselte. Vielleicht weil es dort mehr Erweiterungen gab. 10 Jahre war ich dann mindestens auf WordPress und mehr als einmal enorm genervt.
Der Wechsel auf Hugo lief nicht vollautomatisch. Der WordPress to Hugo Exporter war die einzige von den populären Optionen, die bei mir halbwegs funktioniert hat. Es ist notwendig, den Platz, den ein Blog heute auf der Disk und in der DB beansprucht, noch mal auf der Disk frei zu haben, denn alles wird darauf als Flatfiles repliziert. Die Fehlermeldungen, die das Skript ausspuckt, sind nicht hilfreich bei der Identifikation dieses zu erwartenden Fehlers. Gleichzeitig wurden nicht alle Seiten korrekt konvertiert, so dass ich fast alle Seiten noch mal anfassen musste.
Dabei ist mir zum einen aufgefallen, was sich alles seit 2005 geändert hat:
Menschen und Blogs, die ich vermisse, gefühlt gibt es kaum noch richtige Blogs,
Themen, die mich entweder heute noch interessieren oder bei denen ich mich frage, wie sie mich überhaupt interessieren konnten,
und jede Menge Links zu externen Seiten, die einfach tot sind, obwohl es die Seiten noch gibt.
Das Web ist genau so wenig statisch wie wir es sind, und die 15 Jahre sind für mich eine schöne Dokumentation meiner unterschiedlichen Etappen.
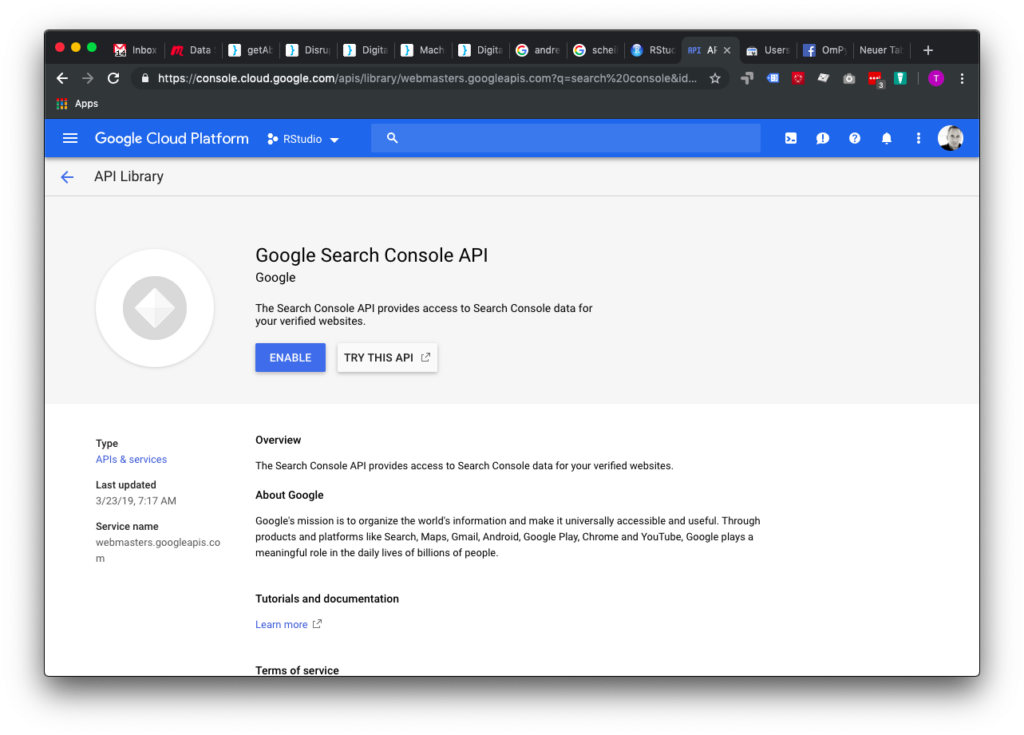
Wenn man mit R automatisiert auf APIs zugreifen will, dann ist die Authoritisierung via Browser keine Option. Die Lösung nennt sich Service User: Mit einem Service User und dem dazu gehörenden JSON-File kann ein R-Programm auf die Google Analytics API, die Google Search Console API, aber auch all die anderen wunderbaren Machine Learning APIs zugreifen Dieses kurze Tutorial zeigt, was für die Anbindung an die Google Search Console getan werden muss.
Zunächst legt man ein Projekt an, wenn man noch kein Passendes hat, und dann müssen die passenden APIs enabled werden. Nach einer kurzen Suche findet man die Google Search Console API, die nur noch aktiviert werden muss.
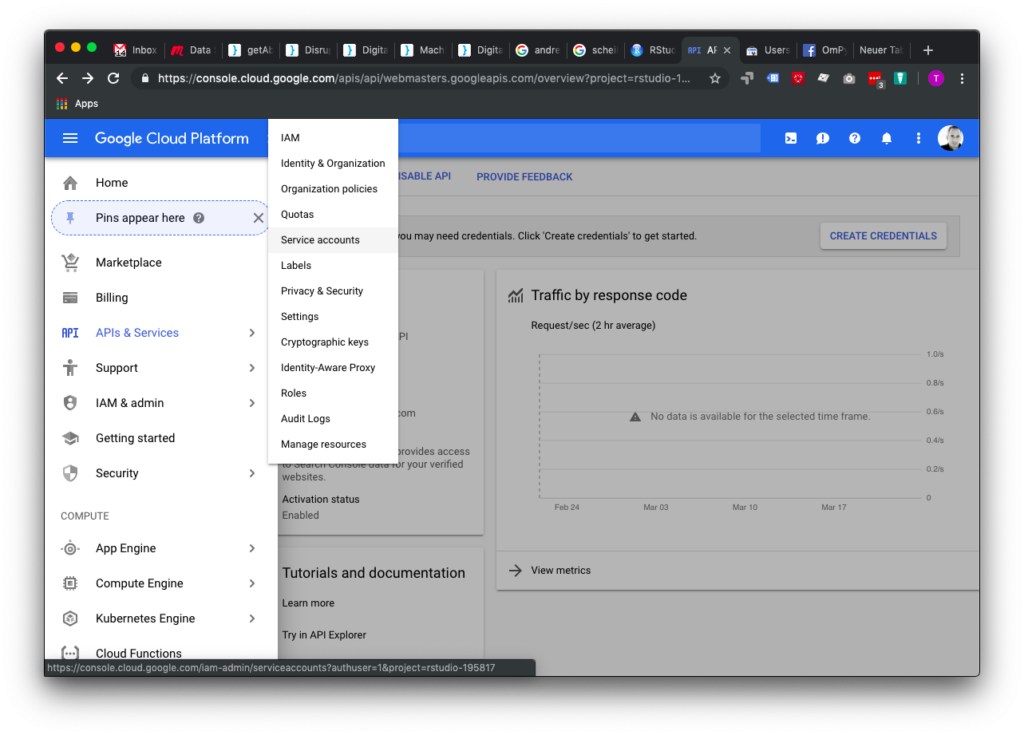
Auf IAM & admin klicken und dann auf Sevice accounts (ist irgendwie seltsam gehighlighted in diesem Screenshot:
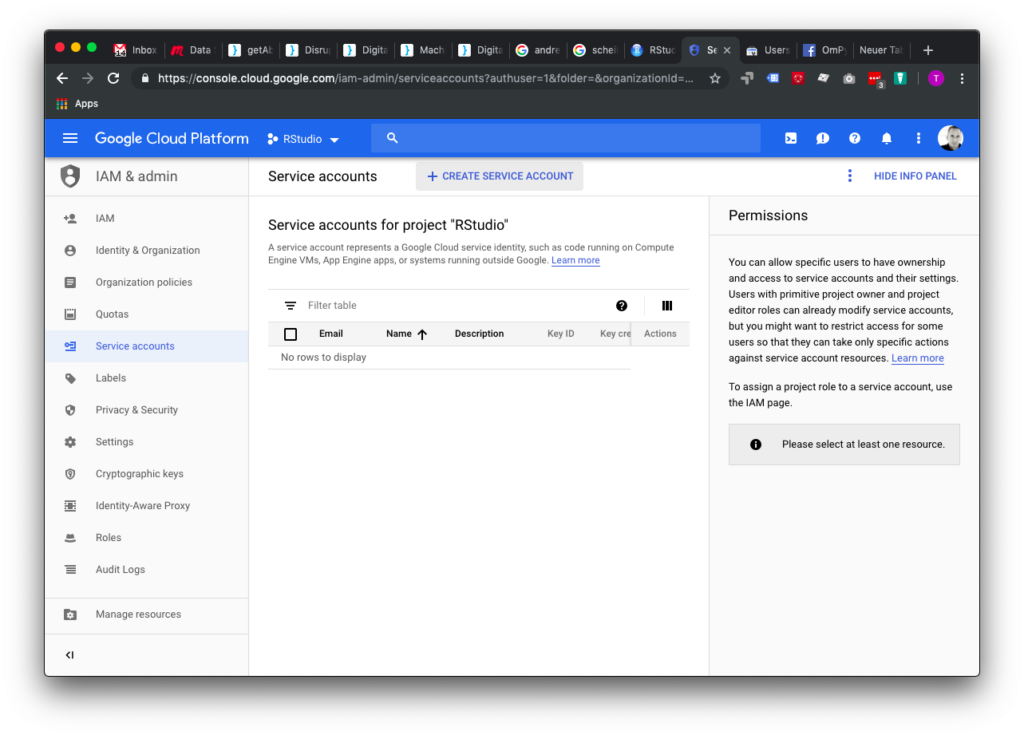
Auf Create Service Account klicken:
Wichtig: Einen sinnvollen Namen geben für die Mail-Adresse, damit man wenigstens etwas die Übersicht behält…
Browse Project reicht bei diesem Schritt:
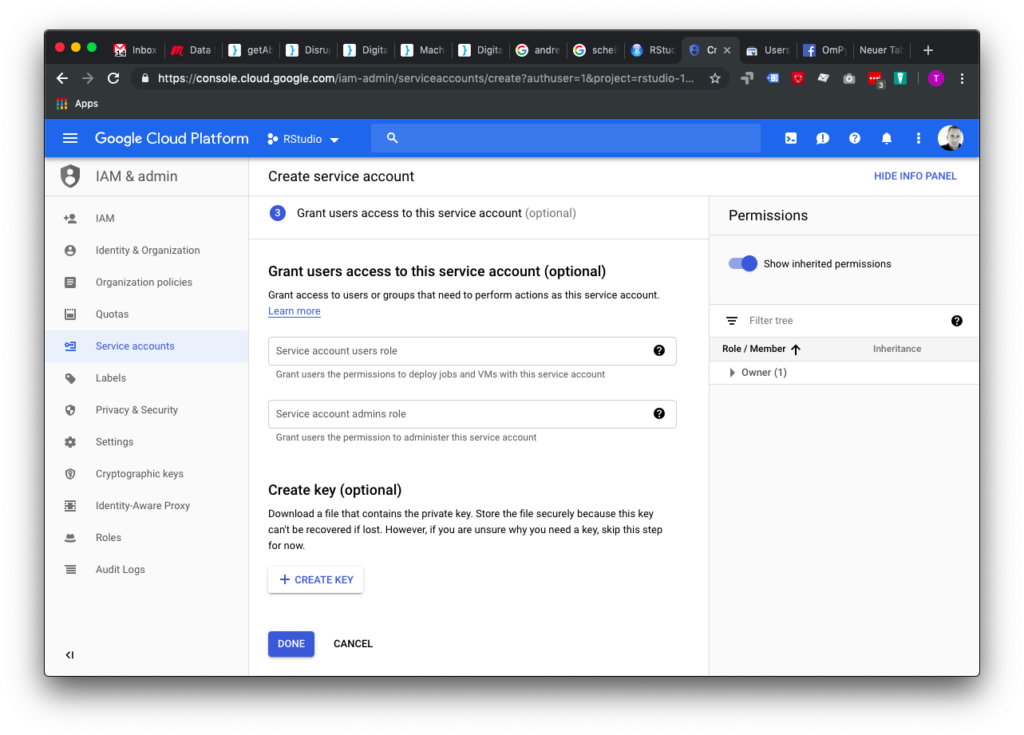
Hier auf “Create Key” klicken:
JSON-Key erstellen, runterladen und dann in das gewünschte RStudio-Verzeichnis legen.
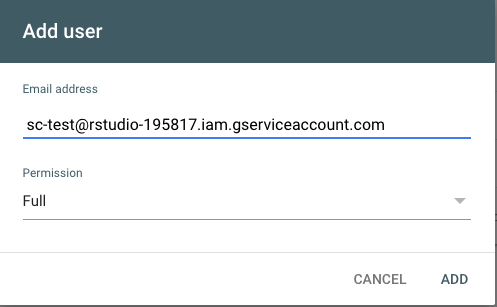
Nun muss der Service User noch als User in der Search Console hinzugefügt werden; wichtig ist, dass er alle Rechte erhält.
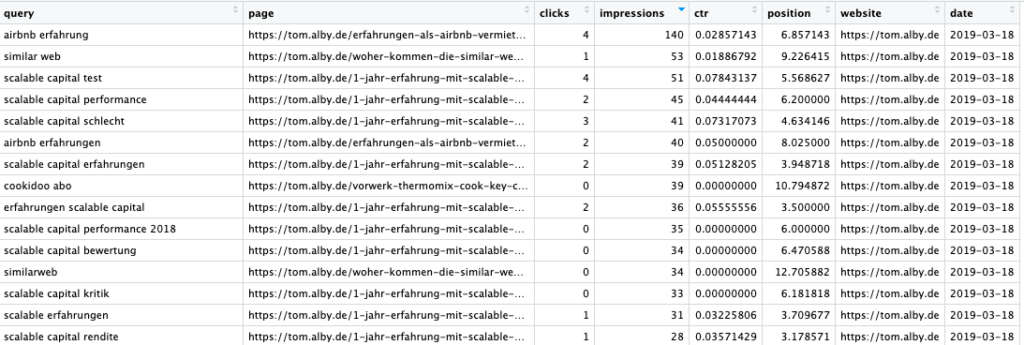
Was wirklich toll ist an der Google Search Console API: Man sieht Query und Landing Page gleichzeitig, anders als in der GUI. Ich hole mir die Daten übrigens jeden Tag und schreibe sie in eine Datenbank, so dass ich eine schöne Historie habe, die über die paar Monate der Search Console hinausgehen.
Zu guter Letzt stelle ich auch noch das R Notebook zur Verfügung, mit dem ich die Daten abfrage; es ist grundsätzlich der Code, den der Autor der API, Mark Edmondson, geschrieben hat, aber nur der Vollständigkeit halber, wie die JSON-Datei eingebunden wird. Es gibt noch eine elegantere Variante mit R Environment Variablen, aber ich weiß nicht, ob die unter Windows funktioniert.
Über Personas habe ich mich ja schon an anderer Stelle ausgelassen, in diesem Artikel geht es um die datengetriebene Generierung von Personas. Ich halte mich an die Definition des Persona-Erfinders Cooper und sehe eine Persona als Prototyp für eine Gruppe von Nutzern. Dies kann auch fürs Marketing interessant sein, denn schließlich lässt dich damit eine bedürfnis- und erfahrungsorientierte Kommunikation zum Beispiel auf einer Webseite erstellen. Personas sind keine Zielgruppen, aber dazu an anderer Stelle mehr.
Wie erstellt man eine datengetriebene Persona?
Den perfekten allgemeingültigen Weg für datengetriebene Personas habe ich auch noch nicht gefunden. Externe Daten sind nicht für alle Themen vorhanden, der ursprüngliche Ansatz von 10-12 Interviews schwierig, und interne Daten haben den Nachteil, dass sie ja nur die Daten derjenigen beinhalten, die man schon kennt, nicht derjenigen, die man vielleicht noch erreichen möchte. Die Wahrheit liegt im Zusammenlegen verschiedener Datenquellen.
Datengetriebene Persona meets Webanalyse
Webanalyse-Daten bieten einiges an Nutzungsverhalten, und je nachdem wie eine Seite aufgebaut ist (zum Beispiel ob sie schon auf die verschiedenen Bedürfnisse unterschiedlicher Personas ausgerichtet ist), lässt sich nachvollziehen, inwieweit sich die verschiedenen Nutzergruppen tatsächlich wie erwartet verhalten. Oder man versucht daten-getriebene Personas aus dem Nutzungsverhalten auf der Webseite zu generieren. Alles unter der Einschränkung, dass die Nutzer die Seite ja erst einmal finden müssen, es ist also nicht sicher, dass wirklich alle Personengruppen tatsächlich auf diese Seite zugreifen und deswegen wichtige Personas übersehen werden. In diesem Artikel geht es um einen Spezialfall dieser automatisierten Persona-Generierung aus Webanalyse-Daten, der aus algorithmischer Sicht und der dazugehörigen Visualisierung spannend ist. Über Erfolge berichtet bekanntlich jeder gerne, hier mal ein Fall, wo der Misserfolg zeigt, in welche Richtung weitere Arbeit gehen könnte.
Die Erfahrungen aus dem Web Mining werden nur selten mit Personas in Verbindung gebracht, obwohl schon vor mehr als 10 Jahren einiges an Forschung dazu betrieben worden ist; für eine Übersicht siehe zum Beispiel Facca und Lanzi, Minining interesting knowledge from weblogs: a survey, aus dem Jahr 2004 (2005 veröffentlicht). Wurden früher vor allem Weblogs (nicht Web-Blogs!) verwendet, also vom Server geschriebene Logdateien, so haben wir heute durch Google Analytics & Co die Möglichkeit, viel “bessere” Daten verwenden zu können.
Reintroducing: Assoziations-Regeln
Aber was genau ist besser? Wir können in GA & Co besser Menschen von Bots unterscheiden (von denen es mehr gibt als man denkt), Wiederkehrer werden zuverlässiger erkannt, Geräte etc. Die Frage ist, ob man die zusätzlichen Daten unbedingt verwenden muss für grundlegende datengetriebene Personas. Denn Assoziationsregeln, über die ich schon mal in einem Beitrag über das Clustering mit Google Analytics und R geschrieben habe und die auch von Facca und Lanzi erwähnt werden, können bereits grundlegende Gruppen von Nutzer identifizieren (ich hatte in dem anderen Artikel bereits erwähnt, dass ich für einen der Schöpfer des Algos, Tomasz Imilinski, mal gearbeitet hatte, aber eine Anekdote mit ihm muss ich noch loswerden: In einem Meeting sagte er mal zu mir, dass man oft denke, etwas sei eine low hanging fruit, ein schneller Erfolg, aber, “Tom, often enough, the low hanging fruits are rotten”. Er hat damit so oft Recht behalten.). Die Gruppen identifizieren sich durch ein gemeinsames Verhalten, die Co-Occurence von Seitenaufrufen zum Beispiel. In R funktioniert das wunderbar mit dem Package arules und dem darin enthaltenen Algo apriori.
Datengetriebene Personas mit Google Analytics & Co.
Wie bereits in dem früheren Artikel erwähnt: Eine Standard-Installation von Google Analytics ist nicht ausreichend (ist sie sowieso nie). Entweder hat man die 360-Variante oder “hackt” die kostenlose Version (“hacken” in Bezug auf “tüftlen”, nicht “kriminell sein”) und zieht sich die Daten via API. Bei Adobe Analytics können die Daten aus dem Data Warehouse gezogen werden oder auch über eine API. Einfach Google Analytics verwenden und daraus Personas ziehen ist also nicht möglich bei diesem Ansatz. Man muss außerdem nachdenken, welches Datum aus GA am besten verwendet wird neben der Client ID, um Transaktionen zu repräsentieren. Das kann von Website zu Website ganz unterschiedlich sein. Und wenn man ganz geschickt sein will, dann ist ein PageView allein vielleicht nicht Signal genug.
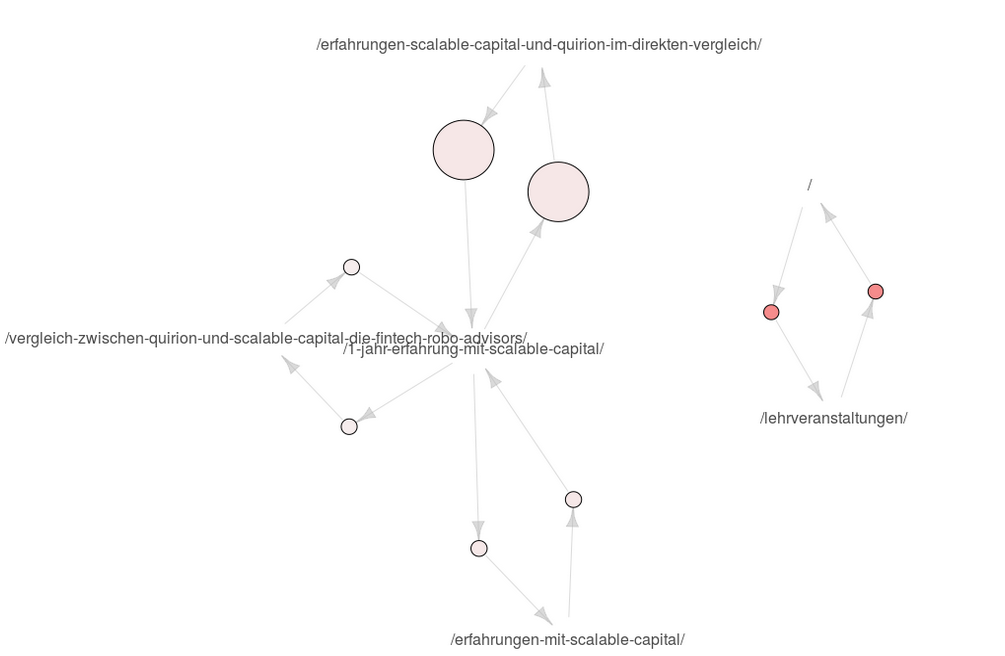
Hier geht es aber zunächst um die Visualisierung und welche Einschränkung der apriori-Ansatz hat für die automatisierte Generierung von datengetriebenen Personas. Für die Visualisierung arbeite ich mit dem Package arulesViz. Die daraus entstehenden Grafiken sind nicht ganz einfach zu interpretieren, wie ich an der HAW, aber auch mit Kollegen erlebt habe. Wir sehen hier unten die Visualisierung von Assoziationsregeln, die aus den Daten dieser Seite gewonnen werden, und zwar mit dem GA-Datum pagePathLevel1 (der bei mir leider gleichzeitig ein Artikel-Titel ist). Hier fällt bereits eines auf: Ich kann hier eigentlich nur zwei Gruppen identifizieren, und das ist ganz schön dürftig.
Was sehen wir hier genau? Wir sehen, dass Nutzer, die auf der Homepage sind, auch in den Bereich Lehrveranstaltungen gehen und umgekehrt. Der Lift ist hier hoch, der Support nicht so. Und dann sehen wir, dass sich Nutzer zwischen meinen vier Artikeln über Scalable Capital bewegen, mit ungefähr gleichem niedrigen Lift, aber unterschiedlich hohem Support. Lift ist der Faktor, um den die Co-Occurence von zwei Items höher ist als deren wahrscheinliches Auftreten, wenn sie unabhängig voneinander wären. Support ist die Häufigkeit. Der Support war beim Erstellen der Assoziationsregeln auf 0.01 definiert worden, die Konfidenz ebenso auf 0.01. Für Details siehe meinen ersten Artikel.
Warum aber sehe ich hier keine anderen Seiten? Mein Artikel über Google Trends ist ein sehr häufig gelesener Artikel, ebenso der über den Thermomix oder AirBnB. Es liegt also nicht daran, dass es nicht mehr Nutzergruppen gäbe. Der Nachteil dieses Ansatzes ist einfach, dass Nutzer mehr als eine Seite besucht haben müssen, damit überhaupt eine Regel hier entstehen kann. Und da einige Nutzer über eine Google-Suche kommen und anscheinend kein Interesse an einem zweiten Artikel haben, weil ihr Informationsbedürfnis vielleicht schon befriedigt ist oder weil ich diese nicht gut genug anpreise, sind hier in diesen Regeln anscheinend nur Studierende sowie Scalable Capital-Interessierte zu identifizieren.
Auswege aus dem apriori-Dilemma?
Bisher habe ich drei Lösungswege für dieses Dilemma identifiziert, und alle erfordern Mehrarbeit:
Ich teste, ob ich Nutzer durch ein besseres relevantes Angebot dazu bekomme, dass sie sich mehr als eine Seite ansehen, zum Beispiel mit Google Optimize, und erhalte im Erfolgsfall bessere Daten.
Ich nutze die apriori-Daten nur als Basis und merge sie mit anderen Daten (auch sehr schön, werde ich aber nicht hier behandeln)
Ich setze den Support und die Konfidenz herunter.
Am schönsten ist der erste Ansatz, meiner Meinung nach, aber dieser erfordert Zeit und Gehirn. Und dass etwas herauskommt ist nicht gesagt. Der letzte Ansatz ist unschön, da wir hier halt mit Fällen zu tun haben, die seltener vorkommen und daher nicht unbedingt belastbar. Bei einem Support von 0.005 sieht die Visualisierung zwar anders aus:
Aber wieder habe ich das Problem, dass die Einzelseiten nicht auftauchen. Es ist also anscheinend extrem selten, dass sich jemand von dem Google Trends-Artikel zu einem anderen Artikel hinbewegt, so dass das Herabsenken des Support-Werts nix gebracht hat. Aus der Erfahrung kann ich sagen, dass dieses Problem mehr oder weniger stark auftaucht auf den meisten Seiten, die ich ansonsten sehe, aber es taucht immer irgendwie auf. Das Dumme ist, wenn man schon gute Personas ablesen kann, dann ist man eher geneigt, sich den Rest nicht mehr anzusehen, auch wenn der vom Umfang her sehr groß sein könnte.
Wir sehen in der Grafik außerdem ein weiteres Problem, denn die Nutzer im rechten Strang müssen von Pfeil zu Pfeil nicht dieselben sein. Anders ausgedrückt: Es ist nicht gesagt, dass sich Besucher, die Fotografie-Seiten und Lehrveranstaltungen ansehen, auch die Veröffentlichungen ansehen, auch wenn das in der Visualisierung so aussieht. Wenn A und B sowie B und C, dann gilt hier nicht A und C! Um dies zu lösen, müssten die Assoziationsregeln in der Visualisierung noch eine ausschließende Kennzeichnung haben. Die existiert nicht und wäre eine Aufgabe für die Zukunft.
Fazit
Der Weg über Assoziationsregeln ist spannend für die Erstellung Daten-getriebener Personas mit Google Analytics oder anderen Webanalyse-Tools. Er wird momentan in der Regel aber nicht ausreichend sein, da a) das Problem von Eine-Seite-Besuchern hier nicht gelöst wird, b) die Regeln nicht ausreichend über unterschiedliche Gruppen informieren, die nur Überschneidungen haben und c) er eh nur über diejenigen Gruppen etwas aussagen kann, die bereits auf der Seite sind. An a) und b) arbeite ich momentan nebenbei, über Gedanken von außen freue ich mich dabei immer



 onsole API, die nur noch aktiviert werden muss.
onsole API, die nur noch aktiviert werden muss.