Manchmal zeigt R Ergebnisse in wissenschaftlicher Notation an, was nicht schlimm wäre, wenn die Exponentenbasis sich nicht unterschiede:

Verhindern lässt sich das ganz einfach, indem man format(x, scientific=FALSE) hinzufügt:

Tom Alby
Manchmal zeigt R Ergebnisse in wissenschaftlicher Notation an, was nicht schlimm wäre, wenn die Exponentenbasis sich nicht unterschiede:
Verhindern lässt sich das ganz einfach, indem man format(x, scientific=FALSE) hinzufügt:
Die AMIs von Louis Aslett sind nützlich, um kurz mal einen RStudio-Server auf einer AWS EC2-Instanz zu starten. Allerdings enthalten diese AMIs nicht immer die aktuelle Version von R oder RStudio. Diese beiden Befehle helfen, sowohl R als auch RStudio upzudaten:
sudo apt-get install gdebi-core<br /> wget https://download2.rstudio.org/rstudio-server-1.1.442-amd64.deb<br /> sudo gdebi rstudio-server-1.1.442-amd64.deb
echo "deb http://cran.stat.ucla.edu/bin/linux/ubuntu `lsb_release -sc`/" | sudo tee --append /etc/apt/sources.list.d/cran.list<br /> sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9<br /> sudo apt update<br /> apt list --upgradable
Wer hier öfter mitliest, der weiß, dass Sistrix eines meiner absoluten Lieblings-Tools ist (ich verlinke mal ganz dreist als bestes SEO Tool), allein schon wegen der schlanken API, dem absolut liebenswürdigen Johannes mit seinen wirklich schlauen Blog-Posts sowie der Unaufgeregtheit, mit der die Toolbox immer wieder überzeugt. Natürlich sind auch alle anderen Tools klasse, aber Sistrix ist sowas wie meine erste große Tool-Liebe, die man nicht aus seinem SEO-Gedächtnis verbannen kann oder will. Und auch wenn die folgenden Daten eventuell am Lack kratzen könnten, eine richtige Delle haben sie in meiner Sistrix-Präferenz nicht verursacht.
Aber genug der Lobhudelei. Worum gehts? Wie schon in dem Post über keywordtools.io oder den am Rande erwähnten Ungenauigkeiten in den Google AdWords Keyword Planner-Daten beschrieben, ist es eine Herausforderung, verlässliche Daten über das Suchvolumen von Keywords zu bekommen. Und wer immer noch glaubt, dass Google Trends absolute Zahlen liefert, nun ja… Sistrix bietet hierfür einen Traffic-Index von 0-100, der auf Basis von verschiedenen Datenquellen berechnet wird, womit eine höhere Genauigkeit entstehen soll. Doch wie genau sind die Zahlen hier? Nebenbei will ich außerdem zeigen, warum Boxplot ein wunderbarer Weg sind, Daten zu visualisieren.
Als Datenbasis dienen hier 4.491 Suchanfragen aus einem Sample, wo ich sowohl die Sistrix- als auch die Google AdWords Keyword Planner-Daten habe. Es ist übrigens nicht das erste Sample, was ich gezogen habe, und die Daten sehen überall ungefähr gleich aus. Es liegt also nicht an meinem Sample. Schauen wir uns also zunächst einmal die reinen Daten an:

Wie wir sehen, könnte man eine Kurve in diesen Plot hineinzeichnen, die Relation scheint schon mal nicht linear zu sein. Aber vielleicht haben wir es hier nur wegen des Ausreißers ein verzerrtes Bild? Schauen wir uns den Plot ohne den Riesen-Ausreißer an:

Vielleicht haben wir hier immer noch zu viele Ausreißer, wir nehmen mal nur die unter einem Suchvolumen von 100.000 pro Monat:

Tatsächlich sehen wir hier eine Tendenz, dass es rechts weiter nach oben geht, zwar keine deutliche Linie (ich habe auf eine Regressionsanalyse verzichtet), aber wir sehen auch, dass wir bei einem Traffic-Wert von 5 Werte haben, die über die Indexwerte von 10,15,20,25 und 30 hinausgehen, sogar bei 50. Schauen wir uns das arithmetische Mittel der Suchvolumina an (mit Ausreißern), so sehen wir wieder die Kurve:

Der Median ignoriert die Ausreißer innerhalb der kleineren Werte:

Sehen wir uns die Daten also im Median an, so sehen wir zumindest bei den höheren Werten eine korrekte Tendenz mit Ausnahme des Wertes bei dem Sistrix-Traffic-Wert von 65 oder 70. Allerdings ist die Streuung um diese Werte sehr unterschiedlich, wenn man die Standardabweichungen für jeden Sistrix-Traffic-Wert plottet:

In der Streuung sehen wir kein Muster. Es ist nicht so, dass die Streuung mit einem höheren Index-Wert zunimmt (was zu erwarten wäre), tatsächlich ist sie bei dem Index-Wert von 5 schon höher als bei 10 etc. Die höchste Streuung sehen wir bei dem Wert von 60.
Weil Boxplots einfach eine wunderbare Angelegenheit sind, schieße ich den auch noch hinterher:

Hier sind die Daten einmal umgedreht (weil sie mit den Sistrix-Daten auf der X-Achse nicht wirklich gut erkennbar waren). Die Box zeigt jeweils an, wo 50% der Daten liegen, also bei einem Suchvolumen von 390 zum Beispiel liegen 50% der Daten zwischen dem Sistrix-Wert von 5 und 25 zu liegen, der Median wird durch den Strich in der Box gekennzeichnet und liegt bei 15. Die Größen der Boxen nehmen am Anfang zu, danach sind sie wieder unterschiedlich groß, was auf eine geringere Streuung hinweist. Bei manchen Datenpunkten sehen wir kleine Kreise, die R als Ausreißer berechnet hat. Wir sehen also gerade bei den geringen Suchvolumina Ausreißer. Fast alles, was wir oben geplottet hatten, kriegen wir hier in einem Plot visualisiert. Boxplots sind einfach wunderbar.
Bedeutet das nun, dass die Traffic-Daten in Sistrix unbrauchbar sind? Nein, das bedeutet es nicht. Denn wie in der Einleitung beschrieben sind auch die Keyword Planner-Daten nicht immer korrekt. Nichts Genaues weiß man also nicht. Wer die Keyword Planner-Daten als Nonplus-Ultra sieht, der wird sich mit den Sistrix-Daten nicht zufrieden geben können. Hilfreich wäre, wenn es mehr Transparenz gäbe, wo die Daten genau herkommen. Offensichtlich wären angebundene GSC-Daten sehr hilfreich, da sie echte Impressions zeigen. Meine Handlungsempfehlung ist, sich mehrere Datenquellen anzusehen und die Overlaps sowie die Abweichungen getrennt anzusehen. Das ist unbefriedigend, da es kein Automatismus ist. Aber “a fool with a tool is still a fool”.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Hanns says
Tom Alby says
martin says
Ich verstehe tatsächlich auch nicht, wie das technisch funktionieren soll. Wie soll Sistrix an die Suchanfragen kommen, die pro Keyword über Google laufen? Ist ja nicht so, als würde Google Sistrix bei jedem Request kurz informieren.
Das einzige was ich mir vorstellen kann ist, dass sie sich die Daten für jedes Keyword aus dem AdsPlanner ziehen. Aber … das als „eigenes Suchvolumen“ darzustellen, ohne Hinweis woher die Daten kommen, fände ich schon grob fahrlässig.
Woher könnten sie noch Daten bekommen?
Tom says
die Antwort ist halt nicht 1 oder 0, das kommt auch in dem Artikel heraus. Du kannst Dich auch nicht auf die AdPlanner-Daten verlassen. Sistrix bekommt auch noch Daten von Kunden, die die Search Console-Daten dort verknüpft haben, da Du ja die Impressions Deiner Seite für ein Keyword sehen kannst. Aber all das natürlich nicht für jedes Keyword. Und daher kommen Ungenauigkeiten zustande.
BG
Tom
Der letzte Teil dieser Serie über Suchmaschinenoptimierung/SEO und Data Science auf Basis meines Vortrags bei der SEO Campixx. Die Daten und den Code habe ich via Knit in ein HTML-Dokument überführt, das mein Notebook inklusive Daten nachvollziehbar macht. In dem Notebook sind auch ein paar mehr Untersuchungen drin, allerdings habe ich alles auf Englisch dokumentiert, da dies nicht nur für Deutsche interessant ist. Wer also alle Ergebnisse in einem Dokument lesen möchte (ohne die TF/IDF, WDF/IDF oder Stemming-Beispiele), schaut sich bitte das Data Science & SEO Notebook an. Speed und andere Faktoren sind in den vorherigen Teilen zu lesen.

Zunächst einmal ein Nachtrag: Uns fehlte ja das Alter für einige Domains, und diese Daten habe ich nun aus einer anderen Quelle bekommen. In unserem Sample waren die meisten Domains ja älter, und meine Sorge war, dass die fehlenden Domains eventuell sehr viel jünger waren und daher das Durchschnittsalter fälschlicherweise nach unten gezogen würde. Fast 20% der Domains fehlten.
Tatsächlich ist es so, dass die fehlenden Domains jünger sind. Lag der Median bei unserem löchrigen Datensatz bei 2001, liegt er bei den fehlenden Domains bei 2011. Führt man die Daten zusammen, liegt er aber dennoch wieder bei 2001, nur der Mean hat sich von 2002 auf 2003 geändert. Somit war die Anzahl der fehlenden Daten nicht so hoch, dass diese gegenläufige Tendenz einen großen Einfluss gehabt hätte. Natürlich könnte man nun entgegenhalten, dass diese andere Quelle einfach ganz andere Zahlen hat, aber bei einer Stichprobe der Domains, für die bereits ein Alter vorhanden war, konnte das nicht verifiziert werden. Und schaut man sich nun den Plot für die Beziehung zwischen Position auf der Suchergebnisseite und Alter einer Domain an, so haben wir also auch nichts Neues herausgefunden:

Boxplots sind eine wunderbare Angelegenheit, denn sie zeigen auf einen Blick unglaublich viel über die Daten. Die Box zeigt an, wo sich 50% der Daten befinden, der dicke Strich in der Mitte den Median, und die Breite der Box die Wurzel aus der Sample-Menge. Selbst nach mehreren Bier ist hier kein Muster zu erkennen, außer dass die Boxen alle ungefähr auf der gleichen Höhe sind. Google hatte ja bereits gesagt, dass das Alter einer Domain keine Rolle spielt.
Ein weiterer Mythos, und an diesem ist toll, dass wir ihn relativ einfach aufklären können, denn die Daten können wir uns selber crawlen. Übrigens eignet sich R nicht soooo super zum Crawlen; zwar gibt es das Paket rvest, aber wenn man wirklich nur den Content haben will, dann kommt nix an Pythons Beautiful Soup dran. Netterweise kann man in den RStudio-Notebooks auch Python ausführen Als Text wird hier also nur der tatsächliche Text genommen, nicht der Quellcode. Navigationselemente und Footer zählen allerdings mit rein, wobei wir bei Google davon ausgehen können, dass der tatsächliche Content extrahiert werden kann. Der folgende Plot zeigt das Verhältnis zwischen Content-Länge und Position:

Wie wir sehen, sehen wir nix, bis auf einen interessanten Ausreißer mit mehr als 140.000 Wörtern in einem Dokument (http://katalog.premio-tuning.de/), der auf Platz 3 für das Keyword “tuning kataloge” rankte. Ansonsten ist keine Korrelation zu beobachten. Eine allgemeingültige Aussage wie “mehr Text = bessere Position” lässt sich somit nicht ableiten. Der Median für die Anzahl Wörter liegt bei 273, der Mean bei 690. Nur zur Erinnerung, wir befinden uns hier in den Top 10. Wie die Kollegen von Backlinko auf 1.890 Wörter für das durchschnittliche 1. Platz-Dokument gekommen sind, würde mich tatsächlich sehr interessieren. Zwar haben sie weit mehr Suchergebnisse angesehen (was bedeutet “1 million search results”? Genau das, also ungefähr 100.000 Suchergebnisseiten, also die Ergebnisse für ungefähr 100.000 Suchanfragen?), aber welchen Durchschnitt sie verwendet haben, verraten sie nicht. Wie man schon in meinen Zahlen sehen kann, gibt es einen großen Unterschied zwischen dem Median und dem Mean, also dem arithmetischen Mittel, das die meisten Menschen als Durchschnitt bezeichnen. Nicht umsonst sage ich immer, dass der Durchschnitt der Feind der Statistik ist Vielleicht sind Texte in den USA aber auch länger? Aber da uns die Zahlen nicht zur Verfügung gestellt werden… und auch nicht die Methoden… nun ja, irgendwann habe ich mal gelernt, dass man zu seinen Ergebnissen sowohl die Daten als auch die Software zur Auswertung beifügen muss, damit wirklich alles nachvollziehbar ist.

In diesem abschließenden Teil habe ich noch weitere Signale hinzugefügt, u.a. TF/IDF und WDF/IDF. Und wie man in der Korrelationsmatrix schön sehen kann, haben wir nirgendwo eine Korrelation. Im letzten Teil hatten wir aber auch schon gesehen, dass das nicht über alle Keywords gilt. In dem Histogramm der Korrelationskoeffizienten sahen wir sowohl positive als auch negative Korrelationen, aber keinen p-Wert. Schaut man sich nur die Korrelationskoeffizienten an, bei denen p < 0.05 ist, sieht das Bild wieder anders aus:

Wir haben also Keywords, wo die Backlinks eine Rolle spielen, und wir haben auch Keywords, wo die anderen Signale eine Rolle spielen. Wenn wir aus dem Keyword-Set eine Schlussfolgerung ziehen können, dann die, dass es keine allgemeingültige Regel gibt. Wie schon beim letzten Teil geäußert, benötigen wir die obige Korrelationsmatrix für jedes Keyword. Und genau das ist spannend, denn wir können für jedes Keyword einzeln oder vielleicht auch ein Thema schauen, wie sich die Ranking-Signale dort verhalten.

Und so sieht man für das Keyword “player update” (als Hash 002849692a74103fa4f867b43ac3b088 in den Daten im Notebook), dass einige Signale doch stärker hervortreten, siehe die Abbildung auf der linken Seite. Kann man nun sicher sein, dass man jetzt für dieses Keyword genau weiß, wie das Ranking funktioniert? Nein, kann man nicht (zumal wir hier noch nicht die p-Werte ausgerechnet haben). Aber wenn wir uns mehrere Keywords aus der gleichen “Region” (also ähnliche Werte in diesem Signal) anschauen, dann könnte tatsächlich etwas darin zu finden sein.
Leider auch nix. Und das war wohl der größte Streitpunkt auf der SEO Campixx. Ich nutze in diesem Beispiel erst einmal nur den Exact Match, also finde ich genau das eingegebene Keyword so im Text. Natürlich könnten wir jetzt weiter gehen und stemmen und auseinander gepflückte Keywords matchen lassen, aber um die Komplexität zu verringern, schauen wir und halt nur den Exact Match an. Schauen wir einmal hier:

Hier ist kein eindeutiges Muster zu sehen, und es gibt auch keine Korrelationen. Nur sehr wenige Beobachtungen schaffen überhaupt einen p-Wert unterhalb 0,05 sowie einen Korrelationskoeffizienten von mehr als 0.1. In diesem Keywordset kann nicht nachvollzogen werden, dass WDF/IDF etwas bringt, zumindest nicht für Exact Match. Ebenso wenig TF/IDF. Keyword Density hab ich nicht mal nachgeschaut.
Der letzte Teil meiner Präsentation von der SEO Campixx war eine Kurzzusammenfassung meiner Artikelserie über ein SEO-Reporting mit R und AWS (insbesondere der Teil über das handlungsrelevante Analysen und ein Reporting).
Noch einmal die wichtigsten Punkte:
Die emotionalen Reaktionen mancher Kollegen sind nicht unverständlich, denn schließlich werden manche Tools teuer bezahlt (es saßen ja auch Tool-Betreiber in meinem Vortrag, von denen einer sich zu der Aussage hinreißen ließ, dass man merke, dass ich lange nicht mehr als SEO gearbeitet hätte). Es ist ungefähr so als ob ich zu einem Christen gehe und sage, dass sein Jesus leider nie existiert hat. Das habe ich nicht gesagt. Ich habe lediglich gesagt, dass ich die Wirkung gängiger Praktiken anhand meines Datensatzes nicht nachvollziehen kann. Aber viele SEOs, die ich sehr schätze, haben mir gesagt, dass z.B. WDF/IDF für sie funktioniere. In der Medizin heißt es “Wer heilt hat Recht”, und am Ende des Tages kommt es auf das Ergebnis an, auch wenn nachgewiesen ist, dass Homöopathie nicht hilft.nUnd vielleicht kommen die guten Resultate dieser SEOs auch nur dadurch zustande, dass sie auch viele andere Dinge richtig machen, es dann aber auf WDF/IDF schieben.
Was mich als Daten-Mensch aber interessiert ist die Reproduzierbarkeit. In welchen Fällen funktioniert WDF/IDF und wann nicht? Hinzufügen möchte ich, dass ich keinerlei kommerzielles Interesse daran habe, irgendeinen Weg als gut oder schlecht zu bezeichnen, denn ich verkaufe kein Tool (mal sehen, vielleicht baue ich ja mal irgendwann eines) und ich verdiene mein Geld nicht mit SEO. Mit anderen Worten: Mir ist es so ziemlich sch***egal, was hier rauskommt. Die Wahrscheinlichkeit, dass ich einem Bestätigungsfehler unterliege, weil ich nur noch Fakten suche, die meine Meinung unterstützen, ist äußerst gering. Mich interessiert nur die Wahrheit in einer post-faktischen Welt. Und anders als zum Beispiel die Untersuchung von Backlinko stelle ich meine Daten und meinen Code zur Verfügung, damit das jeder nachvollziehen kann. Das ist Komplexität, und viele versuchen Komplexität zu vermeiden und suchen einfache Antworten. Aber auf schwierige Fragen gibt es nun mal keine einfachen Antworten, auch wenn das für Menschen viel attraktiver ist. Meine Empfehlung: Keiner Statistik glauben, die nicht die Daten und Methoden nachvollziehbar macht. Ich wünsche mir von allen Kritikern, dass sie auch die Daten und ihre Software offenlegen mögen. Hier geht es nicht um Eitelkeit.
Die Donohue–Levitt-Hypothese ist für mich ein gutes Beispiel: So wurde die Zero Tolerance-Vorgehensweise der New Yorker Polizei in den 90er Jahren dafür gelobt, dass die Kriminalität daraufhin signifikant zurück ging. Das ist bis heute eine weit verbreitete Meinung. Donohue und Levitt hatten die Zahlen untersucht, kamen aber auf eine andere Schlussfolgerung, nämlich dass dies eine Scheinkorrelation sei. In Wirklichkeit sei die Verbreitung der Babypille dafür verantwortlich gewesen, dass die jungen Straftäter erst gar nicht geboren werden, was sich dann in den 90er Jahren bemerkbar machte. Natürlich wurde auch das wieder angegriffen, dann wieder bestätigt, und dann fand auch noch jemand heraus, dass das Verschwinden des Blei-Anteils aus Benzin für die Verringerung der Jugendkriminalität verantwortlich sei (Lead-Crime-Hypothese). Allerdings sind das komplexere Modelle. Mehr Polizeiknüppel gleich weniger Kriminalität ist einfacher zu verstehen und wird deswegen auch immer noch verteidigt (und vielleicht ist ja auch ein bisschen was dran?). Aber auch hier, wer ein Modell sympathischer findet, der wird sich vor allem die Daten anschauen, die diese Meinung bestätigen.
Ich hätte noch viel mehr untersuchen können. Aber wie gesagt, ich mache das nebenbei. Lust auf mehr Daten zu dem Thema habe ich schon. Aber jetzt liegen erst mal wieder andere Datenberge hier Und dann wäre der nächste Schritt ein größerer Datensatz sowie Machine Learning, um Muster genauer zu identifizieren.
Jetzt ist der Vortrag schon wieder einen Monat her, und ich hab immer noch nicht alles runtergeschrieben. Das liegt allerdings auch daran, dass ich die letzten Wochen noch mehr Daten akquiriert habe, damit ich einen Datensatz habe, den ich teilen kann und der nicht kundenspezifisch ist.
80% der Zeit geht für das Validieren und Bereinigen der Daten drauf, so die Faustregel, und ich würde noch einen Punkt hinzufügen, nämlich das Transformieren der Daten. Daten liegen selten so vor, dass man sie gleich verwenden kann.
Aber eines nach dem anderen. Für diesen Teil wollte ich Backlink-Daten sowie Crawl-Daten hinzufügen, nur gibt es die Backlink-Daten bei Google nur noch für die eigene Domain, und wenn man Tools wie Sistrix nutzt, dann kosten die API-Abfragen nun mal Geld bzw. Credits. Am Beispiel von Sistrix erläutert: Für die Abfrage nach Backlinks (links.overview) bezahlt man 25 Credits, mit 50.000 Credits pro Woche kann mal also für 2.000 URLs die Links abfragen. Allerdings kann ich nur die Credits verwenden, die am Ende der Woche nicht für andere Tools verbraten wurden, so dass ich also für 14.099 unique Hosts, die ich im letzten Teil mit den 5.000 Suchanfragen generiert habe, mehr als 7 Wochen benötigen würde. Bis dahin habe ich 1.000 andere Projekte und vergessen, was ich hier an Code geschrieben habe Also habe ich ein Sample genommen auf Basis von 500 Suchanfragen, die ich zufällig aus meinen 5.000 Suchanfragen gezogen habe. Leider war die Ratio unique Hosts/alle URLs hier nicht so schön wie bei dem Gesamtset, 2.597 unique Hosts waren abzufragen.
Dummerweise hatte mir die Sistrix API hier auch noch einen kleinen Strich durch die Rechnung gemacht, denn für über 250 URLs bekam ich Antworten, die mein Skript nicht richtig abgefangen hatte, z.B.
`{“method”:[[“links.overview”]], “answer”:[{“total”:[{“num”:903634.75}], “hosts”:[{“num”:21491.504628108}], “domains”:[{“num”:16439.602383232}], “networks”:[{“num”:5979.5586911669}], “class_c”:[{“num”:9905.3625179945}]}], “credits”:[{“used”:25}]}

Mein Skript hatte Integer-Werte erwartet (Bruchteile eines Backlinks gibt es meiner Meinung nach nicht) und dann einfach gar nix in den Dataframe geschrieben, wenn eine Zahl von Sistrix kam, die kein Integer war. Aber selbst wenn es das abgefangen hätte, die Zahl, die ich hier sehe, hat nichts mit der Zahl zu tun, die ich im Webinterface sehe, wobei es auch hier ab und zu komische Zahlen gibt (siehe Screenshot). Sind das nun 197.520 Backlinks oder 19.752.000? Bitte nicht falsch verstehen, Sistrix ist eines meiner Lieblingstools, aber solche Sachen machen mich wahnsinnig, und R ist da auch nicht ganz einfach Es half nix, ich musste erst mal die Daten durchsehen und zum Teil manuell (!!!) ergänzen. Und wie schwierig R manchmal sein kann, zeigt sich dann, wenn man bestehende Daten ergänzen möchte, aber die vorhandenen Daten in einer Spalte nicht auf NA setzen will. Meine unelegante Lösung der Transformation (die mich 2 Stunden gekostet hat):
test <- merge(sample_2018_04_02,backlinks_2, by = “host”, all.x = TRUE) test <- cbind(test, “backlinks_raw”=with(test, ifelse(is.na(total.y), total.x, total.y))) `
Für das Alter einer Domain hatten wir ja letztes Mal schon gesehen, dass uns Daten fehlen, aber hier existiert ja auch die offizielle Aussage von Google, dass das Alter einer Domain keinen Einfluss auf das Ranking hat. Allerdings waren die alten Domains in der Mehrzahl, so dass man eventuell davon ausgehen könnte, dass neuere Domains geringere Chancen haben, in den Index zu kommen oder in die Top 10, es dann aber egal ist für die jeweilige Position in den Top 10. Die Aussage haben wir aber explizit nicht getroffen, denn es könnte ja sein, dass die fehlenden Alters-Werte in meinem Datensatz genau die jüngeren Domains sind. Das gilt es also noch herauszufinden, allerdings nicht mehr als Teil dieser Serie. Dann könnte ich auch gleich mal die Top 100 untersuchen
Zusammengefasst: Es sieht alles immer ganz einfach aus, aber das Sammeln, Transformieren und Bereinigen der Daten kostet einfach sehr viel Zeit und Energie.

Wir wollen uns zunächst einmal anschauen, ob wir allein durch das Plotten der einzelnen Variablen in Bezug zueinander etwas erkennen können. Die Variablen, die wir hier jetzt haben, sind:
Da fehlen noch ein paar Variablen, aber wir fangen erst einmal hiermit an. Wie wir schön sehen können, sehen wir so gut wie nix Also schauen wir uns noch mal die nackten Zahlen an:

Hier sehen wir schon etwas mehr. Zum Beispiel eine (z.T. sehr schwache) Korrelation zwischen http und backlinks_log, year und backlinks_log, Speed und year, backlinks_raw und ip usw. Aber warum überhaupt die Logarithmisierung der Backlinks? Das wird an dem folgenden Beispiel deutlich:

Schauen wir uns im Histogram die Verteilung der Häufigkeiten der Backlinks an, so sehen wir ganz links einen hohen Balken und ansonsten nicht viel. Kein Wunder, denn in den Suchergebnissen haben wir Hosts wie Youtube, die eine neunstellige Anzahl von Backlinks haben, aber die meisten Hosts haben viel viel weniger Backlinks. Nutzen wir stattdessen einen Logarithmus, also “stauchen” wir das etwas zusammen, dann sieht das Histogram schon ganz anders aus:

Wir sehen hier halt, dass viele Hosts irgendwo in der Mitte sind, einige mit wenigen Links rausstechen (das ist der Balken bei der 0) und wenige Hosts sehr viele Backlinks haben. Spannend ist dann auch die Frage, ob bei jeder Suchanfrage die Anzahl der Backlinks der einzelnen Suchtreffer vergleichbar ist. Die Antwort hier ist nein, wie das folgende Histogram zeigt (auch logarithmisiert):

Ich habe hier für jedes Keyword die durchschnittliche Anzahl der Backlinks berechnet und dann logarithmisiert auf das Histogram gepackt (ohne Logarithmus sähe das Histogram aus wie das unlogarithmisierte davor). Und wie wir schön sehen, haben wir auch hier Bereiche, wo die Suchergebnisse von Hosts kommen, die wenig Backlinks haben, die meisten Suchergebnisse tummeln sich in der Mitte, und bei ganz wenigen Suchergebnissen haben wir eine enorme Anzahl von Backlinks. Dazu muss immer gesagt werden, dass der Durchschnitt keine wirklich tolle Geschichte ist. Aber wir sehen zumindest, dass wir verschiedene “Regionen” haben.
Nachdem wir geklärt haben, warum bestimmte Daten logarithmisiert werden, schauen wir uns jetzt mal genauer an, wie die Korrelationen aussehen, angefangen mit Alter und Backlinks:

Wenn wir ein wenig die Augen zukneifen, dann sehen wir eine Anmutung einer Linie, es sieht fast so aus, als gäbe es eine Korrelation zwischen Alter einer Domain und ihren Backlinks. Einmal getestet:
Pearson’s product-moment correlation
data: dataset$year and dataset$backlinks_log
t = -24.146, df = 4286, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.3721183 -0.3194161
sample estimates:
cor
-0.3460401
Das sieht gut aus. Und es ist auch nicht komplett überraschend. Denn je länger eine Domain existiert, desto mehr Zeit hatte sie, Links zu sammeln. Zwar wissen wir bei einer Korrelation nicht, in welche Richtung sie geht, aber es ist unwahrscheinlich, dass eine Domain älter wird, je mehr Backlinks sie bekommt.
Schauen wir uns das auch noch mal an für die Kombination Alter und Geschwindigkeit:
Pearson’s product-moment correlation
data: dataset$year and dataset$SPEED
t = 13.129, df = 4356, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.1663720 0.2234958
sample estimates:
cor
0.1950994
Interessant ist hier, dass der Korrelationskoeffizient positiv ist, d.h., je älter eine Domain ist, desto langsamer ist sie Womit wir wieder bei den Hygienefaktoren wären.
Gute Frage. Denn wie schon im letzten Teil besprochen gilt das nicht für jedes Keyword. Schauen wir uns mal die Korrelation zwischen Backlinks und Position pro Keyword an und werfen die ausgegebenen Korrelationskoeffizienten dann auf ein Histogram:

Ganz deutlich haben wir hier einige Keywords, deren rankende Hosts eine mindestens schwache wenn nicht sogar moderate Korrelation mit der Anzahl der Backlinks aufweisen. Das heißt, wir müssten also für jedes Keyword einzeln schauen, wie sich das Ranking zusammen setzt. Und da wir eh schon wissen, dass das Ranking dynamisch ist, sehen wir das hier noch etwas klarer.

Leider ist es nicht so, dass ein Zusammenhang zwischen der durchschnittlichen Anzahl von Backlinks der gerankten Seiten sowie der Korrelation zwischen Backlinks der Fundstellen sowie Position gibt. Wir sehen in dem Screenshot auf der linken Seite, dass das sehr bunt gemischt ist.
Woran kann das liegen? Zum Beispiel daran, dass ich hier nur die Daten für die Backlinks für die Hosts habe, nicht für die jeweilige Landing Page. Das wäre natürlich noch schöner, und am idealsten wäre es, wenn ich mir dann noch anschauen könnte, wie die Zusammensetzung der einzelnen Faktoren der Backlinks aussähe. Angesichts meiner Credit-Armut ist das momentan aber nicht möglich. Und hier haben wir wieder ein typisches Problem im Bereich der Data Science: Wir wissen, dass die Daten da draußen sind, aber wir kommen nicht dran. Dennoch bietet diese Vorgehensweise schon enorme Vorteile: Ich kann nämlich jetzt für jedes Keyword einzeln anschauen, wie sich das gegenwärtige Ranking zusammensetzt und dementsprechend agieren. In dem Beispiel links sehe ich, dass ich bei “Datenschutz” viele Backlinks für den Host benötige, in meinem Datensatz (nicht auf dem Screenshot) benötigt mein Host aber wenig Backlinks für Suchanfragen wie “gedichte vorruhestand”. Wir benötigen also für jedes Keyword genau dieses Korrelationsmatrix anstatt einer Gesamtsicht wie oben.
Im [nächsten Teil][10] holen wir uns dann weitere Daten dazu (wir fingen ja mal mit TF/IDF und WDF/IDF an).
[1]: Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Steffen Blankenbach says
http://tom.alby.de/wp-content/uploads/2018/04/Bildschirmfoto-2018-04-02-um-12.09.07.png [2]: http://tom.alby.de/wp-content/uploads/2018/04/matrix.png [3]: http://tom.alby.de/wp-content/uploads/2018/04/Bildschirmfoto-2018-04-03-um-01.14.04.png [4]: http://tom.alby.de/wp-content/uploads/2018/04/hist.png [5]: http://tom.alby.de/wp-content/uploads/2018/04/hist_log.png [6]: http://tom.alby.de/wp-content/uploads/2018/04/00000b.png [7]: http://tom.alby.de/wp-content/uploads/2018/04/data-science-seo-age-backlinks.png [8]: http://tom.alby.de/wp-content/uploads/2018/04/plot_zoom_png.png [9]: http://tom.alby.de/wp-content/uploads/2018/04/Bildschirmfoto-2018-04-03-um-02.17.36.png [10]: http://tom.alby.de/data-science-meets-seo-teil-5/
In their 2017 book “R for Data Science“, Grolemund and Wickham state that data.table is recommended instead of dplyr when working with larger datasets (10 to 100 Gb) on a regular basis. Having started with Wickhams sparklyr (R’s interface to Spark using the dplyr dialect), I was wondering how much faster data.table actually is. This is not the most professional benchmark given that I just compare system time before and after the script ran but it gives an indication of the advantages and disadvantages of each approach.
My work includes dealing with larger files almost every day, and for this test, I have used a 16 GB CSV file with 88.956.866 rows and 7 columns. After reading the file, I will do a few simple operations with that data and then write the result back to disk. The test is performed on an AWS EC2 m4.2xlarge instance with 32 GB of RAM and 8 vCPUs of which we will use 4. Let’s start with data.table:
`
library(data.table)
overallStart_time <- Sys.time()
start_time <- Sys.time()
userDataSetDT <- fread(„/home/tom/huge-file.csv“)
Read 88956065 rows and 7 (of 7) columns from 15.969 GB file in 00:02:52
end_time <- Sys.time()
end_time – start_time
Time difference of 6.507585 mins
`
I have no idea why fread says it only needed 2:52 minutes; there were no other CPU-hungry processes running or processes that had a huge impact on IO.
`> start_time <- Sys.time()
userDataSetDT <- userDataSetDT[!is.na(Timestamp)]
end_time <- Sys.time()
end_time – start_time
Time difference of 39.44712 secsstart_time <- Sys.time()
userDataSetDT <- userDataSetDT[!is.na(URL)]
end_time <- Sys.time()
end_time – start_time
Time difference of 38.62926 secsstart_time <- Sys.time()
configs <- userDataSetDT[configSection == “Select Engine”]
end_time <- Sys.time()
end_time – start_time
Time difference of 2.412425 secsstart_time <- Sys.time()
fwrite(configs,file=“configsDT.csv”, row.names = FALSE)
end_time <- Sys.time()
end_time – start_time
Time difference of 0.07708573 secsoverallEnd_time <- Sys.time()
overallEnd_time – overallStart_time
Time difference of 8.341271 mins`
data.table uses only one vCPU or one core respectively by default but consumes more virtual memory (43GB instead of 13GB being used by the R/sparklyr combination). We could use packages such as the parallel one but in fact, data.table is a bit more complex with respect to parallelization.
Now, let’s look at sparklyr:
„> overallStart_time <- Sys.time()
conf <- spark_config()
conf$sparklyr.defaultPackages <- “org.apache.hadoop:hadoop-aws:2.7.3”
conf$sparklyr.cores.local<- 4
conf$sparklyr.shell.driver-memory<- “8G”
conf$sparklyr.shell.executor-memory<- “16G”
conf$spark.yarn.executor.memoryOverhead <- “4g”
conf$spark.memory.fraction <- 0.9
conf$spark.driver.maxResultSize <- “8G”
sc <- spark_connect(master = “local”,
start_time <- Sys.time()
userDataSet <- spark_read_csv(sc, “country”, “/home/tom/huge-file.csv”, memory = FALSE)
end_time <- Sys.time()
end_time – start_time
Time difference of 2.432772 minsstart_time <- Sys.time()
userDataSet <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.01466608 secsstart_time <- Sys.time()
userDataSet <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.001867533 secsstart_time <- Sys.time()
configs <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.001763344 secsstart_time <- Sys.time()
collected <- collect(configs)
end_time <- Sys.time()
end_time – start_time
Time difference of 1.333298 minsstart_time <- Sys.time()
write.csv(collected, file=“configs.csv”, row.names = FALSE)
end_time <- Sys.time()
end_time – start_time
Time difference of 0.01505065 secsoverallEnd_time <- Sys.time()
overallEnd_time – overallStart_time
Time difference of 3.878917 mins
„
We have saved more than 50% here! However, looking at the details, we see that collecting the data has cost us a lot of time. Having said that, doing the selects is faster on sparklyr compared to data.table. We have used 4 vCPUs for this, so there seems to be an advantage in parallelizing computing the data, there is almost no difference in writing the data, also given that data.table’s fread has been highly optimized. Edit: As one commenter said below, you would probably not collect the whole dataset and rather let Spark write the CSV but I have not done to make the approach more comparable.
If we used only one core for sparklyr (which doesn’t make any sense because even every Macbook today has 4 cores), how long would it take then?
`> start_time <- Sys.time()
userDataSet <- spark_read_csv(sc, “country”, “/home/tom/huge-file.csv”, memory = FALSE)
end_time <- Sys.time()
end_time – start_time
Time difference of 4.651707 minsstart_time <- Sys.time()
userDataSet <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.003172636 secsstart_time <- Sys.time()
userDataSet <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.002816916 secsstart_time <- Sys.time()
configs <- userDataSet %>%
end_time <- Sys.time()
end_time – start_time
Time difference of 0.002915621 secsstart_time <- Sys.time()
collected <- collect(configs)
end_time <- Sys.time()
end_time – start_time
Time difference of 4.487081 minsstart_time <- Sys.time()
write.csv(collected, file=“configs.csv”, row.names = FALSE)
end_time <- Sys.time()
end_time – start_time
Time difference of 0.01447606 secsoverallEnd_time <- Sys.time()
overallEnd_time – overallStart_time
Time difference of 8.345677 mins`
The selects are a bit slower albeit not noticable. sparklyr is much slower though when it comes to reading large files and collectiong data with only one core. Having said that, as mentioned above, there is no reason to use only one core.
However, there is still a good reason to use data.table: As you can see in the config file of the sparklyr code, a huge chunk of memory had to be assigned to the collector and the driver, simply because the computation or the collection will throw errors if there is not enough memory available. Finding out how much memory should be allocated to what component is difficult, and not allocating the right amount of memory will result in restarting R and running the code again and again, making data.table the better choice since no configuration is required whatsoever. In addition, it is amazing how fast data.table still is using one core only compared to sparklyr using 4 cores. On the contrary, running the same code on my Macbook Air with 8 GB RAM and 4 cores, data.table had not managed to read the file in 30 minutes whilst sparkly (using 3 of the 4 cores) managed to get everything processed in less than 8 minutes.
While I personally find dplyr a bit more easy to learn, data.table has caught me, too.
“Using R is a bit akin to smoking. The beginning is difficult, one may get headaches and even gag the first few times. But in the long run,it becomes pleasurable and even addictive. Yet, deep down, for those willing to be honest, there is something not fully healthy in it.”
In den ersten beiden Teilen ging es darum, was Data Science überhaupt ist und warum WDF/IDF-Werte sehr wahrscheinlich wenig mit dem zu tun haben, was bei Google unter der Motorhaube passiert. In diesem Teil geht es einen Schritt weiter, wir schauen nämlich, ob es Korrelationen zwischen Ranking Signalen und der Position gibt. Im Vortrag hatte ich das am Beispiel einer Suchanfrage gezeigt und angesichts der zur Verfügung stehenden Zeit auch eher kurz abgehandelt. Hier kann ich in die Tiefe gehen. Wir schauen uns hierbei allerdings erst einmal nur jedes einzelne Rankingsignal in Bezug auf die Positon an, nicht die eventuell vorhandene Wirkung der Rankingsignale untereinander.
Da mein Vortrag bei manchen Kollegen für Schnappatmung und zum Teil “interessante” Äußerungen gesorgt hat, war ein Punkt wahrscheinlich untergegangen. Denn ich hatte ausdrücklich gesagt, und das wiederhole ich hier, dass ich nicht die Aussage treffe, dass man von diesen Daten davon ausgehen kann, dass das Ranking so funktioniert. Wer einmal mit Rechtsanwälten oder Statistikern zu tun hatte weiß, dass diese sich nur ungern auf belastbare Aussagen festnageln lassen wollen. Schließlich kennen wir in der Regel nicht die Gesamtpopulation und müssen daher von einem kleinen Sample auf die Grundgesamtheit schließen; wer ist denn so verrückt und lässt sich darauf festnageln? Daher all die Komplexität mit Konfidenzniveau, Konfidenzintervallen etc…
Die folgenden Aussagen beziehen sich auf ein Sample von 5.000 Suchanfragen. Das klingt nach viel, aber wir wissen nicht, ob diese Suchanfragen der Gesamtpopulation aller Suchanfragen entsprechen. Die Ergebnisse gelten also für das Sample, und ich bin jederzeit bereit, dass für andere Suchanfragen zu wiederholen, wenn mir diese Suchanfragen zur Verfügung gestellt werden.
Weitere Probleme in diesem Ansatz: Wir haben Zugriff auf ein paar Ranking-Signale, aber nicht alle, und die wenigen Signale, die wir haben, sind zum Teil auch noch ungenau. Wir haben von den über 200 Ranking-Signalen:
Uns fehlen also Signale wie
Zusammengefasst haben wir nur einen Bruchteil der Daten, und von denen sind einige auch nicht mal genau. Und meine Berechnungen basieren zudem auf Suchanfragen, von denen wir nicht wissen, ob sie repräsentativ sind.
Mein Lieblingsbeispiel für den verhängnisvollen Glauben an Korrelationen ist der statistische Zusammenhang zwischen den Marktanteilen des Microsoft Internet Explorers und der Mordrate in den USA zwischen 2006 und 2011. Zwar mag es witzig sein zu behaupten, dass hier ein Zusammenhang besteht (und das führt auch regelmäßig zu einem Lacher in Vorträgen), aber Tatsache ist, dass hier ein statistischer Zusammenhang, den wir als Korrelation bezeichnen, kein wirklicher Zusammenhang sein muss. Korrelation bedeutet nicht Ursache und Wirkung. Schlimmer noch, in der Statistik wissen wir nicht mal, in welche Richtung der statistische Zusammenhang läuft. In diesem Beispiel also, ob die Marktanteile des Internet Explorers zu mehr Morden geführt haben, oder ob die Morde dazu geführt haben, dass man danach den Internet Explorer benutzt hat, um seine Spuren zu verwischen.
Natürlich sind die Zusammenhänge in manchen Situationen klar: Wenn ich mehr Geld ausgebe bei AdWords, dann bekomme ich evtl. mehr Conversions. Und wenn wir den statistischen Zusammenhang zwischen Ranking-Signalen untersuchen, dann ist es wahrscheinlich, dass mehr Backlinks zu einer besseren Position führen, auch wenn natürlich eine bessere Position dafür sorgen kann, dass mehr Webseitenbetreiber interessante Inhalte finden und diese verlinken… Wir wissen aber nicht, ob zum Beispiel die einzelnen Signale sich untereinander beeinflussen können, und wir schauen uns in der Regel ja auch nur die Top 10 an. Wie im vorherigen Teil beschrieben ist das eine Art Jurassic Park, wo wir nicht das ganze Bild haben.
Jede Analyse beginnt mit einer Beschreibung der Daten. Für die 5.000 Suchanfragen haben wir mehr als 50.000 Suchergebnisse bekommen, aber die Ergebnisse, die auf Google-Dienste zeigen, nehmen wir erst einmal raus, da wir nicht wissen, ob diese nach den normalen Ranking-Faktoren gerankt werden. Es bleiben 48.837 URLs über, die sich auf 14.099 Hosts verteilen.
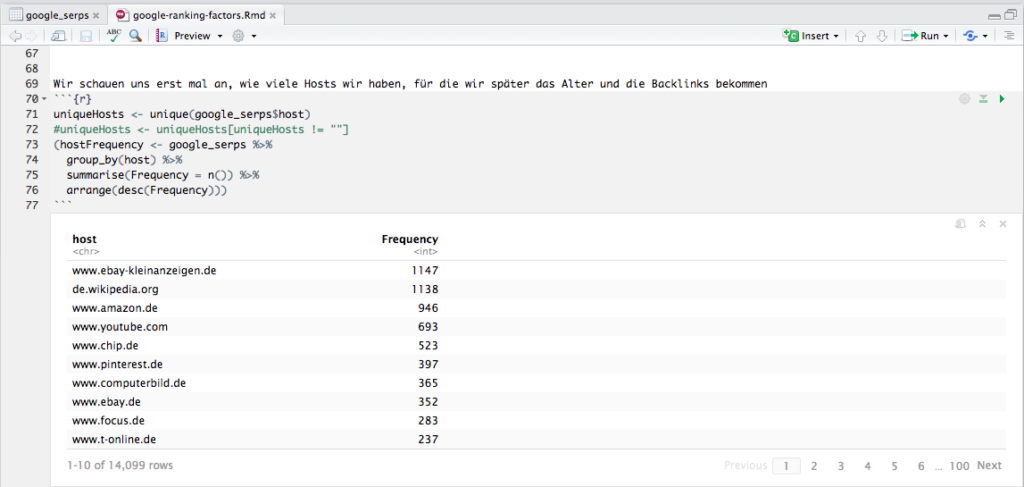
In letzter Zeit arbeite ich vermehrt mit dplyr, das ein Piping ermöglicht wie unter Linux/UNIX; diese Funktionalität wurde dem magrittr-Package entliehen, und sie macht den Code unglaublich übersichtlich. In dem Beispiel in der Abbildung werfe ich nach der auskommentierten Zeile meinen Dataframe google_serps auf group_by(), das nach host gruppiert, und das Ergebnis dieses Schritts werfe ich auf summarise(), das mir dann die Häufigkeiten pro Host berechnet, und das werfe ich zum Schluß noch auf arrange(), was das Ergebnis absteigend sortiert. Das Ergebnis schreibe ich in hostFrequency, und weil ich das Ergebnis in meinem R Notebook sofort sehen will, setze ich den ganzen Ausdruck in Klammern, damit das Ergebnis nicht nur in den Dataframe hostFrequency geschrieben wird, sondern auch gleich ausgegeben. Jedes Mal, wenn ich sowas mit dplyr mache, freue ich mich einen Ast. Und wenn man richtig große Datensätze hat, dann macht man das gleiche mit sparklyr :).
Aber zurück zum Thema: Wir sehen hier also, dass wenige Hosts sehr häufig ranken, und das heißt umgekehrt, dass viele Hosts nur einmal ranken. Keine Überraschung hier.
Die Speed-Daten für jeden Host sind sehr einfach zu bekommen, denn Google bietet dafür die PageSpeed Insights API an, und netterweise gibt es hierfür auch ein R Package. Bei über 10.000 Hosts dauert die Abfrage etwas, und mehr als 25.000 Anfragen pro Tag darf man nicht stellen sowie nicht mehr als 100 (?) Anfragen pro 100 Sekunden. Ich hab das einfach laufen lassen, und nach 1 Tag war mein R abgestürzt und alle Daten verloren. Nicht schön, aber ein Workaround: Nach jedem Request den Dataframe auf die Festplatte schreiben.
Aber schauen wir uns die Daten jetzt einmal genauer an. Hier ist ein Histogramm der Verteilung der Speed-Werte von 14.008 Hosts (ich hab also für 99,4% der Hosts einen PageSpeed-Wert erhalten):

Wir sehen, dass die meisten Hosts es über die 50 Punkte schaffen, und summary gibt uns folgende Zahlen:
Min. 1st Qu. Median Mean 3rd Qu. Max. 0.00 55.00 70.00 66.69 82.00 100.00
Schön ist hier zu sehen, wie irreführend der Durchschnitt sein kann Und nun plotten wir einmal Positionen versus Speed:

Wie wir sehen, sehen wir nix. Das prüfen wir noch einmal genauer:
cor.test(google_serps$position,google_serps$SPEED) Pearson’s product-moment correlation data: google_serps$position and google_serps$SPEED t = -5.6294, df = 48675, p-value = 1.818e-08 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.03438350 -0.01662789 sample estimates: cor -0.02550771
Sieht so aus als ob es keine Korrelation zwischen PageSpeed und Position in den Top 10 gäbe (wir wissen nicht, ob es vielleicht eine gäbe in den Top 100, könnte ja sein, dass die Plätze 11 bis 100 schlechtere PageSpeed-Werte haben). Aber es ist auch nicht unwahrscheinlich, dass wir es mit einem Hygiene-Faktor zu tun haben: Wenn man gut rankt, dann hat man keinen Vorteil, wenn man schlecht rankt, dann wird man bestraft. Das ist ungefähr so als ob man duscht, dann merkt es keiner, aber wenn man nicht geduscht hat, dann fällt es auf. Oder, kurz gefasst (so soll ich es auf der SEO Campixx gesagt haben), eine langsame Webseite ist wie nicht geduscht zu haben Allerdings sehen wir auch Hosts, die trotz einer gruseligen Speed ranken. Aber wenn man nach “ganter schuhe” sucht, dann ist http://ganter-shoes.com/de-at/ wohl das beste Ergebnis, auch wenn die Seite bei mir 30 Sekunden zum Laden benötigt.
Bedenken sollten wir auch, dass die PageSpeed API eine Echtzeit-Messung durchführt… vielleicht haben wir nur einen schlechten Moment erwischt? Man müsste eigentlich mehrmals die PageSpeed messen und daraus einen Durchschnitt erstellen.
Was wir auch sehr einfach bekommen an Daten, ist die Unterscheidung, ob ein Host https verwendet oder nicht. Während manche die Verwendung sicherer Protokolle als einen gewichtigen Rankingfaktor ansehen, sehen gemäßigtere Stimmen wie Sistrix die Verwendung von SSL eher als schwachen Rankingfaktor. In diesem Datensatz haben 70% aller URLs ein https. Aber bedeutet das auch, dass diese Seiten besser ranken?
Wir haben es hier mit einer besonderen Form der Berechnung zu tun, denn wir versuchen den Zusammenhang zwischen einer kontinuierlichen Variable (der Position) und einer dichotomen Variable (SSL ja/nein) zu ermitteln. Die beiden Varianten des Protokolls wandeln wir um in Zahlen, http wird zu einer 0, https zu einer 1 (siehe Screenshot unten in den Spalten secure und secure2).
Die Ermittlung des Point-Biserial Koeffizienten ist ein Sonderfall des Pearson Korrelation Koeffizients; normalerweise würden wir in R einfach cor.test(x,y) eingeben, aber hierfür wird ein zusätzliches Paket geladen, was diese Sonderform unterstützt. Tatsächlich unterscheiden sich die Werte der beiden Tests aber kaum, und cor.test liefert mir zudem noch den p-Wert.

Wie wir sehen, sehen wir nix oder fast nix: Mit einem Korrelations-Koeffizienten von -0,045067 können wir ausschließen, dass https einen Einfluss auf das Ranking in den Top 10 gehabt hat. Bedeutet das, dass wir alle wieder auf https verzichten sollten? Nein, denn für den Nutzer ist es besser. Und sobald Browser noch deutlicher zeigen, dass eine Verbindung nicht sicher ist, werden sich die Nutzer eher schneller von einer Seite verabschieden. Ganz abgesehen davon, dass wir uns hier ja nur die Top 10 angesehen haben. Es könnte ja sein, dass die Plätze 11 bis 1000 vor allem von Seiten ohne SSL belegt waren. Und dann könnten die Ergebnisse schon wieder anders aussehen.
Vielleicht haben wir es bei SSL als Ranking-Faktor aber auch mit einem umgekehrten Hygienefaktor zu tun. Google hätte zwar gerne SSL, aber da manche wichtige Seite evtl noch kejn SSL hat, verzichtet man darauf. So wie man vielleicht gerne hätte, dass der Traumpartner geduscht ist, aber wenn die oder der dann plötzlich vor einem steht, dann ist es doch egal, weil man halt so verliebt ist. Auf Dauer geht das natürlich nicht gut. Und so wird das bei SSL auch sein
Gehen wir zu dem nächsten Ranking-Signal, dem Alter einer Domain, auch wenn es heißt, dass das Alter einer Domain keine Rolle spielt. Hier stehen wir vor einer ersten Herausforderung: Wie bekomme ich möglichst automatisch und vor allem zuverlässig das Alter einer Domain heraus? Sistrix bietet das Alter einer Domain an, aber nicht die eines Hosts (der Unterschied wird im Skript zu meinem SEO-Seminar an der HAW erklärt). Trotzdem hat Sistrix den Vorteil, dass die API sehr schlank und schnell ist. Allerdings findet Sistrix für 2.912 der Domains (nicht Hosts) kein Alter, bei 13.226 unique Domains sind das dann 22% ohne Domain-Alter. Jurassic Park lässt grüßen (wer diese Anspielung nicht versteht, bitte den zweiten Teil über Data Science und SEO lesen). Schauen wir uns dennoch einmal die Verteilung an:

Wir sehen eine leicht rechtsschiefe Verteilung, d.h. dass wir links bei den älteren Domains eine höhere Frequenz sehen (nein, ich sehe nicht spiegelverkehrt, so bezeichnet man das halt). Jüngere Domains scheinen hier geringere Chancen zu haben. Allerdings kann es auch sein, dass Sistrix gerade jüngere Domains nicht in der Datenbank hat und die knapp 3.000 fehlenden Domains eher rechts anzusiedeln wären.
Können wir wenigstens hier eine Korrelation sehen? Wir plotten die Daten erst einmal:
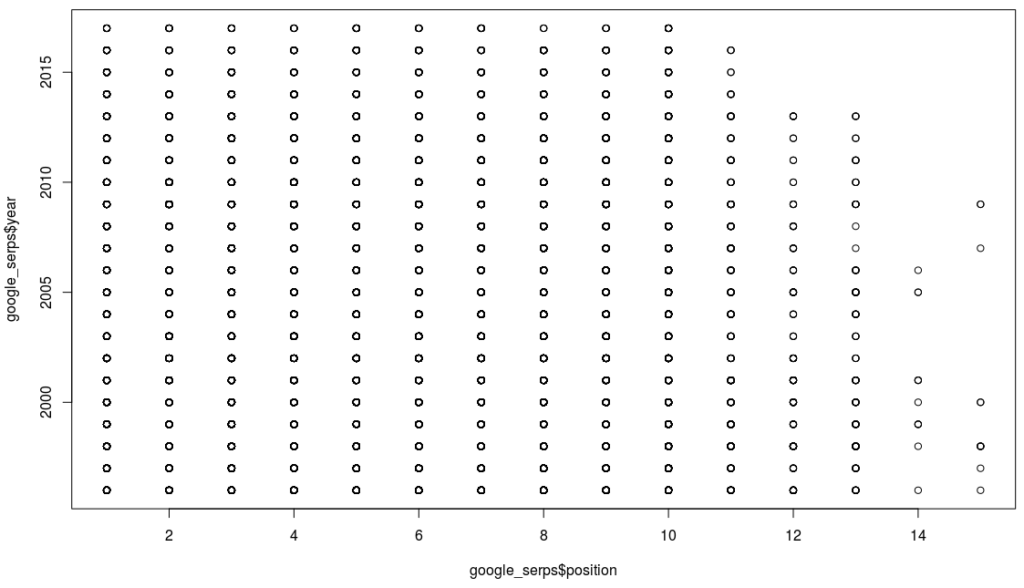
Auch hier sehen wir nix, und wenn wir uns die Korrelation berechnen lassen, dann bestätigt sich das:
cor.test(google_serps$position,as.numeric(google_serps$year)) Pearson’s product-moment correlation data: google_serps$position and as.numeric(google_serps$year) t = 1.1235, df = 44386, p-value = 0.2612 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.003970486 0.014634746 sample estimates: cor 0.005332591
Ich habe nicht nur keine Korrelation, sondern liege auch außerhalb des Konfidenzniveaus. Das Ergebnis ist aber mit viel Vorsicht zu genießen, denn wie oben schon erwähnt kann es sein, dass unsere Auswahl einfach nicht repräsentativ ist, denn vermutlich wird nicht jede Domain die gleiche Chance gehabt haben in die Domain-Alter-Datenbank von Sistrix zu kommen. Wir müssten diese Daten also ergänzen und eventuell auch die Daten von Sistrix überprüfen (ich habe nicht herausfinden können, woher Sistrix die Daten hat); leider habe ich auch kein Muster identifizieren können, denn manchmal zeigt die eine Quelle ältere Daten an, manchmal eine andere Quelle. Im Prinzip müsste man alle Datenquellen nehmen und dann immer das älteste Datum nehmen. Nur leider lassen sich die meisten Quellen auch nicht so einfach scrapen Und somit haben wir nicht nur fehlende, sondern auch zum Teil fehlerhafte Daten. Und das ist kein untypisches Problem im Data Science Bereich.
Da ich schon bald die 2.000 Wörter zusammen habe (und ich die Korrelation Wörter/”bis zum Ende des Artikels gelesen” für mein Blog kenne), werde ich die nächsten Ranking-Faktoren im nächsten Blogpost begutachten. Wichtig: Wir sehen hier zwar, dass wir für angeblich sehr wichtige Ranking-Faktoren keine Evidenz finden, dass sie tatsächlich einen Einfluss haben. Aber das bedeutet nicht, dass das wirklich stimmt:
Beispiel:
cor.test(google_serps$position[google_serps$keyword==“akne vitamin a”],google_serps$secure2[google_serps$keyword==“akne vitamin a”]) Pearon’s product-moment correlation data: google_serps$position[google_serps$keyword == “akne vitamin a”] and google_serps$secure2[google_serps$keyword == “akne vitamin a”] t = -4.6188, df = 8, p-value = 0.001713 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.9645284 -0.4819678 sample estimates: cor -0.8528029
Auch wenn das Konfidenzintervall hier sehr groß ist, es bewegt sich für diese Suchanfrage “akne vitamin a” immer noch im Bereich einer mittleren bis starken Korrelation (es korreliert negativ, weil die Positionen von 1 bis 10 oder weiter hoch gehen). Es gilt also auch die Segmente oder “Regionen” zu identifizieren, wo bestimmte Signale eine Wirkung haben. Dazu mehr im nächsten Teil über Data Science und SEO.
Nachdem ich im ersten Teil erklärt habe, was Data Science ist und was es in diesem Bereich schon zum Thema SEO gibt, nun der zweite Teil, wo wir uns etwas genauer damit beschäftigen, was die linguistische Verarbeitung eines Dokuments durch eine Suchmaschine für eine Auswirkung auf SEO-Konzepte wie Keyword Density, TF/IDF und WDF/IDF hat. Da ich auf der SEO Campixx live Code gezeigt habe, biete ich hier alles zum Download an, was das Nachvollziehen der Beispiele noch erlebnisreicher macht Das geht übrigens auch ohne die Installation von R, hier ist der komplette Code mit Erklärungen und Ergebnissen zu finden.
(Bitte überspringen, wenn Du das nicht in R selber nachbauen möchtest)
Ich empfehle die Nutzung von RStudio zusätzlich zu R, weil der Umgang mit den Daten damit für Neulinge etwas einfacher ist (und für Profis auch). R gibts beim R Project, RStudio auf rstudio.com. Erst R installieren, dann RStudio.
In der ZIP-Datei befinden sich zwei Dateien, ein Notebook und eine CSV-Datei mit einem kleinen Text-Corpus. Ich verweise in diesem Text ab und zu auf das Notebook, aber das Notebook kann auch so durchgearbeitet werden. Wichtig: Bitte nicht die CSV-Datei mit dem Import-Button einlesen, denn dann wird eine Library geladen, die die Funktionalität einer anderen Library zunichte macht.
Das Notebook hat den großen Vorteil, dass sowohl meine Beschreibung, der Programm-Code als auch das Ergebnis im gleichen Dokument zu sehen sind.

Um den Programm-Code auszuführen, einfach rechts oben in der Ecke auf den grünen Pfeil klicken, und schon funktioniert es
(Bitte überspringen, wenn die Konzepte klar sind!)
Es gibt Menschen, die TF/IDF (Term Frequency/Inverse Document Frequency) bzw WDF/IDF (Word Document Frequency/Inverse Document Frequency) besser erklären können als ich, bei WDF/IDF hat sich Karl mit einem unglaublich guten Artikel hervorgetan (und übrigens in diesem Artikel auch schon gesagt, dass “eigentlich kein kleiner bzw. mittelgroßer Anbieter von Analyse-Werkzeugen eine derartige Berechnung für eine große Anzahl an Benutzern anbieten kann … ;-“).
Eine simplifizierte Erklärung ist, dass die Term Frequency (TF) die Häufigkeit eines Terms in einem Dokument ist, die Inverse Document Frequency (IDF) dagegen die Bedeutung eines Terms misst in Bezug auf alle Dokumente eines Corpus, in denen der Begriff vorkommt (Corpus ist der Begriff der Linguisten für eine Kollektion von Dokumenten; das ist nicht dasselbe wie ein Index).
Bei TF wird, vereinfacht und dennoch noch immer viel zu kompliziert ausgedrückt, die Anzahl des Vorkommens eines Begriffes gezählt und dann in der Regel normalisiert, indem diese Zahl durch die Anzahl aller Wörter im Dokument geteilt wird (diese Definition ist in dem Buch “Modern Information Retrieval” von Baeza-Yates et al zu finden, der Bibel der Suchmaschinenbauer). Es gibt aber weitere Gewichtungen der TF, und WDF ist eigentlich nichts weiter als eine solche andere Gewichtung, denn hier wird die Term Frequency um einen Logarithmus zur Basis 2 versehen.
Bei der IDF wird die Anzahl aller Dokumente im Corpus durch die Anzahl der Dokumente geteilt, in denen der Begriff auftaucht, und das Ergebnis wird dann um einen Logarithmus zur Basis 2 versehen. Die Term Frequenz oder die Word Document Frequency wird dann mit der Inverse Document Frequency multipliziert, und schon haben wir TF/IDF (oder, wenn wir WDF anstatt TF verwendet haben, WDF/IDF). Die Frage, die sich mir als Ex-Mitarbeiter von mehreren Suchmaschinen stellt, ist aber, was genau hier ein Begriff ist, denn hinter den Kulissen wird eifrig an den Dokumenten herumgewerkelt. Dazu mehr im nächsten Abschnitt “Crash-Kurs Stemming…”.
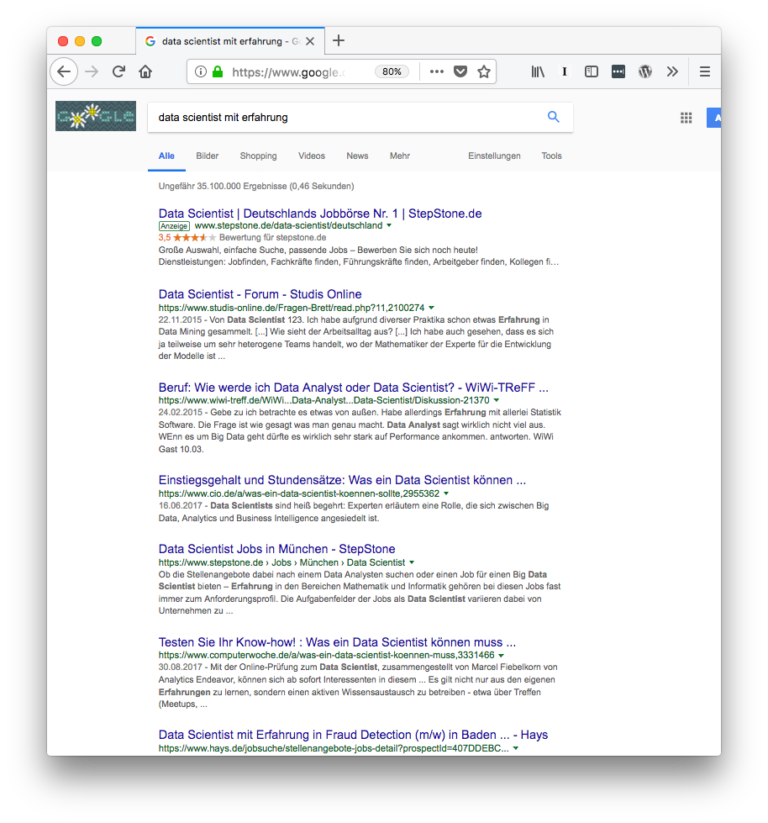
Jeder hat schon die Erfahrung gemacht, dass man nach einem Begriff sucht und dann eine Ergebnisseite bekommt, auf der der Begriff auch in abgewandelter Form zu finden ist. Das liegt zum Beispiel daran, dass ein Stemming durchgeführt wird, bei dem Wörter auf ihren Wortstamm reduziert werden. Denn nicht nur im Deutschen wird konjugiert und dekliniert, auch andere Sprachen verändern Wörter je nach Person, Tempus etc. Um den Recall zu erhöhen wird also nicht nur nach dem exakten Begriff gesucht, sondern auch Varianten dieses Begriffes (den Begriff “Recall” hatte ich im Vortrag nicht verwendet, er beschreibt im Information Retrieval, wie viele passende Dokumente für eine Suchanfrage gefunden werden). So werden für die Suchanfrage “Data Scientist mit Erfahrung” auch Dokumente gefunden, die zum Beispiel die Begriffe “Data Scientist” und “Erfahrungen” enthalten (siehe Screenshot links).
Im Vortrag habe ich live “gestemmt”, und zwar mit dem SnowballC-Stemmer. Dieser ist nicht unbedingt der beste Stemmer, aber er liefert einen Eindruck davon, wie das mit dem Stemming funktioniert. In dem R-Notebook zu diesem Beitrag ist der Stemmer leicht erweitert, denn dummerweise stemmt der SnowBallC immer nur das letzte Wort, so dass der Stemmer in eine Funktion gepackt wurde, die dann einen ganzen Satz komplett stemmen kann:
| > stem_text(„Dies ist ein toller Beitrag“) [1] „Dies ist ein toll Beitrag“ > stem_text(„Hoffentlich hast Du bis hierhin gelesen.“) [1] „Hoffent hast Du bis hierhin geles.“ |
Es sind aber nicht nur Varianten eines Begriffes. Gerade wir Deutschen sind Weltmeister im Erfinden neuer Wörter, indem wir sie durch das Zusammensetzen von anderen Wörtern “komponieren”. Nicht umsonst werden diese Wortschöpfungen Komposita genannt.Ein Beispiel für die Verarbeitung von Komposita findet sich in dem Screenshot rechts, wo aus dem Länderdreieck das Dreiländereck wird. Zunächst einmal klingt das ganz einfach, man trennt einfach Begriffe, die als einzelnes Wort stehen könnten, und indexiert diese dann. Allerdings ist es nicht ganz so einfach. Denn nicht jedes Kompositum darf getrennt werden, weil es getrennt eine andere Bedeutung bekommt. Denken wir zum Beispiel an “Druckabfall”, wo das Abfallen des Drucks auch als Druck und Müll interpretiert werden könnte

Am Beispiel des “Data Scientist mit Erfahrung” wird auch ein weiteres Verfahren der Suchmaschinen deutlich: Begriffe müssen nicht zusammen stehen. Sie können weiter auseinander stehen, was manchmal für den Suchenden extrem nervig sein kann, wenn einer der Begriffe in der Suchanfrage in einem völlig anderen Kontext steht. Die Proximity, also die Nähe der Begriffe, kann ein Signal für die Relevanz der im Dokument vorhandenen Begriffe für die Suchanfrage sein. Google bietet Proximity als Feature an, wie Proximity als Ranking-Signal verwendet wird, ist nicht klar. Und hiermit ist nur die textliche Nähe, noch nicht die semantische Nähe gemeint. Natürlich wird noch viel mehr prozessiert in der lexikalischen Analyse, abgesehen vom Stop Word Removal etc. Aber hier geht es erst einmal nur um einen kleinen Einblick.
Wir sehen hier also gleich drei Punkte, die die meisten SEO-Tools nicht können: Stemming, Proximity und Decompounding. Wenn man also in den Tools über Keyword Density, TF/IDF oder WDF/IDF redet, dann in der Regel auf Basis von Exact Matches und nicht den Varianten, die eine Suchmaschine mit verarbeitet. Bei den meisten Tools wird das nicht deutlich; so kann das allseits beliebte Yoast SEO Plugin für WordPress nur den Exact Match verwenden und berechnet dann eine Keyword Density (Anzahl des Begriffes im Verhältnis zu allen Wörtern des Dokuments). ryte.com sagt aber zum Beispiel:
Darüber hinaus berücksichtigt allein die Formel WDF*IDF nicht, dass Suchbegriffe auch in einem Absatz gehäufter vorkommen können, dass Stemming-Regeln gelten könnten oder dass ein Texte verstärkt mit Synonymen arbeitet.
Solange die SEO-Tools das also nicht können, können wir also nicht davon ausgehen, dass diese Tools uns “echte” Werte geben, und genau das hat der liebe Karl Kratz auch schon gesagt. Es sind Werte, die auf Basis eines Exact Match errechnet wurden, wohingegen Suchmaschinen eine andere Basis nutzen. Vielleicht ist das auch komplett egal, weil alle nur die SEO-Tools nutzen und darauf optimieren, das schauen wir uns im nächsten Teil an Es gibt aber noch weitere Gründe, warum die Tools uns nicht die ganze Sicht bieten, und diese schauen wir uns im nächsten Abschnitt einmal genauer an.
Nun sagt bereits die Definition von IDF aus, warum ein Tool, das TF/IDF ausspuckt, ein kleines Problem hat: Es weiß nicht, wie viele Dokumente mit dem Begriff im Google-Corpus sind, es sei denn, diese Zahl wird auch aus den Ergebnissen “gescraped”. Und hier haben wir es eher mit Schätzungen zu tun. Nicht umsonst steht bei den Suchergebnissen immer “Ungefähr 92.800 Ergebnisse”. Stattdessen nutzen die meisten Tools entweder die Top 10, die Top 100 oder vielleicht sogar einen eigenen kleinen Index, um die IDF zu berechnen. Hinzu kommt, dass wir ja auch noch die Anzahl ALLER Dokumente im Google-Index benötigen (beziehungsweise aller Dokumente eines Sprachraums, worauf mich Karl Kratz noch mal aufmerksam machte). Laut Google sind dies 130 Billionen Dokumente. Wir müssten also, ganz vereinfacht, so rechnen (ich nehme mal TF/IDF, damit der Logarithmus nicht alle abschreckt, aber das Prinzip ist das gleiche):
TF/IDF = (Häufigkeit des Begriffes im Dokument/Anzahl der Wörter im Dokument)*log(130 Billionen/”Ungefähr x Ergebnisse”),
wobei x die Anzahl ist, die Google pro Suchergebnis anzeigt. So, und dann hätten wir eine Zahl pro Dokument, aber wir wissen ja nicht, auf welchen TF/IDF- oder WDF/IDF-Wert die Dokumente kommen, die nicht unter den untersuchten Top 10 oder Top 100 Ergebnissen sind. Es könnte sein, dass auf Platz 967 ein Dokument ist, dass bessere Werte aufweist. Wir sehen nur unseren Ausschnitt und vermuten, dass dieser Ausschnitt uns die Welt erklärt.
Und hier kommt kurz die Chaos-Theorie ins Spiel Wer Jurassic Park gesehen (oder sogar das Buch gelesen) hat, der erinnert sich vielleicht an den Chaos-Theoretiker, im Film gespielt von Jeff Goldblum. In Jurassic Park spielt die Chaos-Theorie eine große Rolle, denn es geht darum, dass komplexe Systeme ein Verhalten aufweisen können, das schwer vorhersehbar ist. Und so werdem weite Teile des Parks von Videokameras überwacht, bis auf 3% des Areals, und genau dort pflanzen sich die Dinosaurierweibchen fort. Denn diese können ihr Geschlecht wechseln (was zB Frösche auch können). Übertragen auf TF/IDF und WDF/IDF bedeutet das: wir sehen nicht 97% des Areals, sondern weniger als 1% (die Top 10 oder Top 100 der Suchergebnisse) und wissen aber nicht, was im Rest unserer Suchergebnisseite schlummert. Dennoch versuchen wir auf Basis dieses kleinen Teils etwas vorherzusagen.
Heißt das nun, dass TF/IDF oder WDF/IDF Quatsch sind? Nein, bisher habe ich nur gezeigt, dass diese Werte nicht unbedingt etwas damit zu tun haben, was eine Suchmaschine intern für Werte hat. Und das ist nicht mal eine neue Information, sondern bereits von Karl und manchen Toolanbietern auch so dokumentiert. Daher schauen wir uns im nächsten Teil etwas genauer an, ob wir eine Korrelation zwischen TF/IDF bzw WDF/IDF und Position auf der Suchergebnisseite finden können oder nicht.
In dem beigefügten R-Notebook habe ich zur Veranschaulichung ein Beispiel gewählt, dass uns alle (hoffentlich) an die Schule erinnert, und zwar habe ich einen kleinen Corpus von Goethe-Gedichten gebastelt (hier habe ich wenigstens keine Copyright-Probleme, bei den Suchergebnissen war ich mir nicht ganz so sicher). Etwas mehr als 100 Gedichte, eines davon kann ich nach 30 Jahren immer noch auswendig. In diesem kleinen wunderbaren Corpus normalisiere ich erst einmal alle Wörter, indem ich sie alle klein schreibe, entferne Zahlen, entferne Punkte, Kommata, etc und entferne Stopwörter.
Zwar gibt es in R eine Library tm, mit der man TF/IDF wie auch TF (normalisiert)/IDF berechnen kann, aber, Skandal (!!!), nix zu WDF/IDF. Vielleicht baue ich dazu selber mal ein Package. Aber zu Veranschaulichungszwecken habe ich einfach mal alle Varianten selber gebaut und nebeneinander gestellt. Ihr könnt also in meinem Code selber nachvollziehen, was ich getan habe. Schauen wir uns mal die Daten an für die ungestemmte Variante:

Wir sehen hier schon einmal, dass sich das “Ranking” verändern würde, wenn wir nach TF/IDF oder TF (normalisiert)/IDF sortieren würden. Es gibt also schon mal einen Unterschied zwischen WDF/IDF und den “klassischen” Methoden. Und nun schauen wir uns die Daten einmal für die gestemmte Variante an:
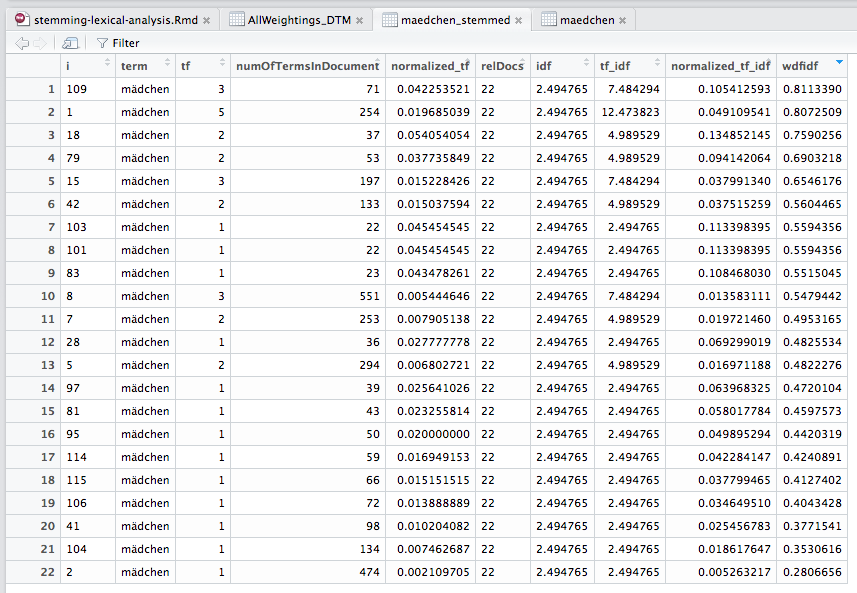
Wir sehen, dass sich zwei Dokumente in die Top 10 reingemogelt haben, und auch, dass wir plötzlich 22 anstatt 20 Dokumente haben. Das ist logisch, denn aus einem Begriff mit zwei oder mehr verschiedenen Stämmen kann nun einer geworden sein. Wir sehen aber auch sehr schnell, dass sich alle Zahlen verändert haben. Denn nun haben wir eine andere Basis. Mit anderen Worten, was auch immer SEOs aus WDF/IDF lesen, die Werte entsprechen mit hoher Wahrscheinlichkeit nicht dem, was tatsächlich bei Google passiert. Und noch mal: Das ist keine Neuigkeit! Karl Kratz hat das bereits gesagt, und auch einige Tools sagen das in ihren Glossaren. Nach meinem Vortrag aber wirkte es so als hätte ich gesagt, dass Gott nicht existiert
Und vielleicht ist es ja auch so, dass allein die Annäherung schon funktioniert. Das schauen wir uns in den nächsten Teilen über Data Science und SEO an.
Puh. Nee. Nicht wirklich. Nur weil man mit R arbeitet, heißt das noch nicht, dass man Data Science betreibt. Aber wir haben uns zumindest etwas warm gemacht, indem wir wirklich verstanden haben, wie unser Werkzeug tatsächlich funktioniert.
Am 1.3.2018 hatte ich auf der SEO Campixx einen Vortrag zu dem Thema Data Science und SEO gehalten, und da es im Nachgang einige Diskussionen gab :-), werde ich die Inhalte hier etwas ausführlicher beschreiben, in mehreren Teilen. In diesem Teil geht es zunächst einmal darum, was Data Science überhaupt ist und was es bereits zu dem Thema gibt.
“The sexiest job of the 21st century” ist genauer betrachtet eher dröge, denn die meiste Zeit wird damit verbracht, Daten zu akquirieren und zu bereinigen und damit Modelle zu bauen. Es ist Coding, es ist Mathe, es ist Statistik, und bei größeren Datenmengen ist es auch noch jede Menge Wissen darüber, wo man welche Instanzen wie auf Amazon Web Services oder Google Cloud Platform miteinander verdrahtet. Eine globalgalaktische Definition von Data Science existiert meines Wissens nach nicht, aber ich würde Data Science als die Schnittmenge aus
definieren. Das sind alles keine neuen Themen, neu ist aber, dass wir viel mehr Daten, viel schnellere Prozessoren, günstiges Cloud-Processing sowie viele Entwicklungs-Bibliotheken haben. Für die hier genutzte Statistik-Sprache und Entwicklungsumgebung R existieren Bibliotheken für fast jeden Zweck; irgendwo gab es schon mal jemanden, der vor dem gleichen Problem stand und dafür dann eine Lösung gebaut hat. Neu ist auch, dass immer mehr Unternehmen spüren, dass man mit Daten etwas anfangen kann, schließlich weiß Spotify anhand von Daten, welche Musik einem noch gefallen könnte, und Google weiß, wann man sich auf den Weg machen sollte, will man pünktlich zur Arbeit kommen.
Dummerweise stehen dem Data-Hype (dem nach einem Plateau der Enttäuschung ein gesundes Verständnis davon folgen wird, was möglich ist) relativ wenig Menschen gegenüber, die sich in allen drei Disziplinen (plus Cloud Computing) zuhause fühlen. Was wiederum dazu führt, dass diesen Data Scientist-Einhörnern manchmal unvernünftige Summen geboten werden und 1000e von Kursen auf Udemy & Co angeboten werden, die einem das notwendige Wissen vermitteln sollen.
Ein tatsächliches Problem von Data Science ist aber, dass nicht nur Wissen in mehreren Bereichen notwendig ist, sondern auch das Verständnis dafür, dass man mit Daten ein Problem lösen will. Ich kann mich den ganzen Tag mit Algorithmen und Daten beschäftigen, für mich ist das wie eine Art Meditation und Entspannung. Tatsächlich empfinde ich es manchmal wie mit Lego zu spielen Aber am Ende des Tages geht es darum, Probleme zu lösen. Nicht nur Daten sammeln, sondern auch daraus die richtigen Informationen daraus zu ziehen und dann noch die richtige Aktion (die heilige Dreifaltigkeit der Daten). Und hier ist die Herausforderung, dass oft genug einfach nur gesagt wird, hier sind Daten, mach was daraus. Daher ist es eine Kunst für den Data Scientist, sein Gegenüber genau zu verstehen, was eigentlich das Problem ist und dies in Code zu übersetzen.
Hinzu kommt, dass viele Menschen schlechte Erinnerungen an Mathe haben. Dementsprechend ist die Bereitschaft des Publikums, Folien mit vielen Zahlen und Formeln zu konsumieren, in der Regel eher am unteren Ende der Skala. Daher habe ich im Vortrag auch mit kleineren Beispielen gearbeitet, die jeder gut nachvollziehen können sollte.
An was für Themen arbeite ich? Sehr unterschiedlich. Klassifikation. Clustering. Personalisierung. Chatbots. Aber auch Analysen von etwas größeren Datenmengen von 25 Millionen Zeilen Analytics-Daten und mehr, die in wenigen Minuten durchprozessiert werden müssen. Alles mögliche.
Auf der Seite der Suchmaschinen bereits einiges. Als ich noch bei Ask war hatten wir schon mit Support Vector Machines gearbeitet um zum Beispiel das Ranking für die Anfragen zu gestalten, bei denen die Seiten so gut wie keine Backlinks hatten. Schon damals gab es ein dynamisches Ranking. Die Themenerkennung der meisten Suchmaschinen basiert auf Machine Learning. RankBrain wird auf Machine Learning basieren. Es ist also kein neues Thema für die Suchmaschinen.
Auf der anderen Seite, der der SEOs, scheint das Thema allerdings noch relativ frisch zu sein. Search Engine Land sagt, dass sich jeder Search Marketer als Data Scientist wähnen darf. Ich bin nicht sicher, ob ich das unterschreiben würde, denn die meisten Search Marketer, die ich kenne, bauen nicht ihre eigenen Modelle. In der Regel nutzen sie Tools, die das für sie tun. Auf SEMRush findet sich eine Ideensammlung, allerdings eher für SEA. Spannend ist noch Remi Bacha, wobei ich von ihm noch keine Daten gesehen habe. Keyword Hero haben was ziemlich Cooles auf die Beine gestellt, indem sie mit Deep Learning die Organic Keywords identifizieren, die seit der Umstellung auf https nicht mehr mitgeliefert werden. Ansonsten habe ich noch nicht viel gesehen zu dem Thema. Wir sehen also, wir stehen ganz am Anfang.
Was hätten wir gerne?
Zurück zu der Frage, welches Problem ich eigentlich lösen will mit meiner Arbeit. In einer idealen Welt wünscht sich der SEO natürlich, dass man den Google-Algorithmus re-engineeren kann. Das ist allerdings unwahrscheinlich, denn von den über 200 Ranking-Signalen stehen uns nur wenige zur Verfügung. Was wir aber tun können: Versuchen, mit den Signalen, die wir haben, Modelle zu bauen, und eventuell kleinere Tools zu erstellen. Und genau darum geht es dann im nächsten Teil
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}