Dies ist der vorläufig letzte Teil der Serie über SEO mit R und AWS. Im ersten Teil hatten wir die AWS-Instanz mit RStudio vorbereitet, im zweiten Teil eine kleine SEO-Analyse durchgeführt, im dritten Teil ging es um die Erstellung eines Sichtbarkeitsindexes und eines “actionable Reportings”. In diesem Teil geht es darum, dass es selbst dem hartgesottensten Data Scientist zu anstrengend ist, die einzelnen Skripte täglich durch RStudio laufen zu lassen. Das SEO Monitoring soll also über eine ansprechende Oberfläche laufen.
GUI-Entwicklung mit Shiny
Die Entwickler von RStudio haben mit Shiny ein Framework zur Verfügung gestellt, welches Interaktion mit Daten ermöglicht, und das mit wenigen Zeilen Code. Glücklicherweise wird Shiny in dem AMI, das wir in Teil 1 dieser Serie installiert hatten, gleich mitgeliefert.
Der Code unterteilt sich in zwei Teile, dem Server-Code und dem UI-Code; beide Teile können in eine Datei, die dann als app.R in einen speziellen Ordner in RStudio abgelegt wird. In dem Server-Teil werden die einzelnen Funktionen genutzt, die wir für die ersten Teile dieser Serie verwendet haben (darum ist hier auch nicht der ganze Code zu finden).
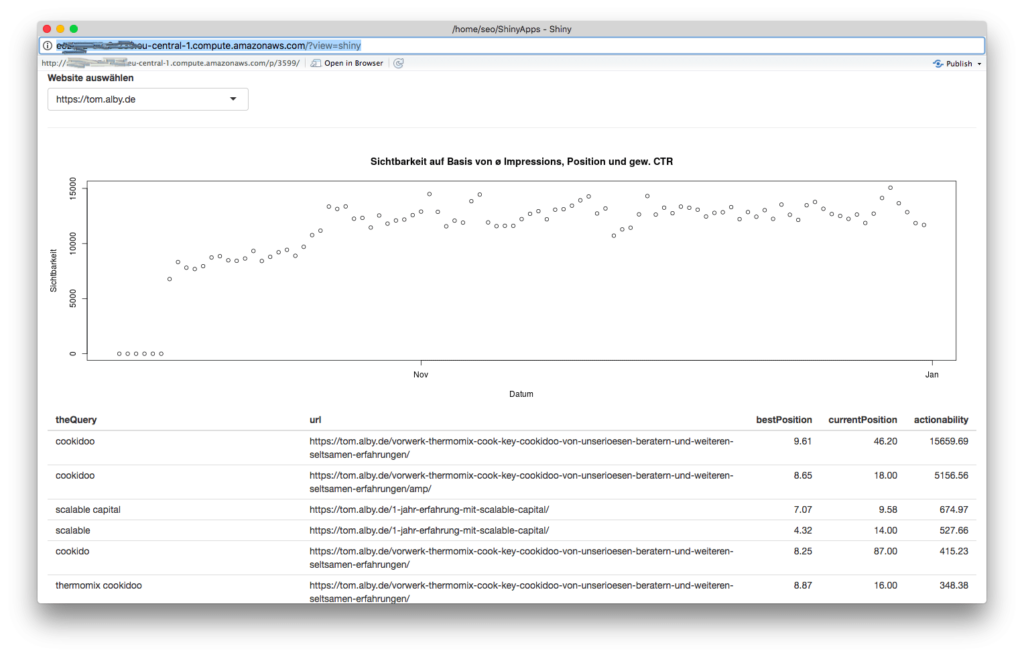
Nicht unbedingt schön für einen Kunden, aber vollkommen ausreichend, um ein Reporting für sich selbst zu bauen. Links oben wähle ich die Webseite aus, für die ich das Reporting haben möchte, und nachdem die Skripte durchgelaufen sind, erscheint der Sichtbarkeitsindex-Plot sowie die Tabelle mit den größten Ranking-Verlusten. Das Erstellen dieses Dashboards hat gerade mal 20 Minuten gedauert (ok, fairerweise hatte ich auch schon mal andere Dashboards mit Shiny gebaut, so dass ich etwas Erfahrung hatte
Nächste Schritte
In meinem gegenwärtigen Setup habe ich einfach nur den Code genutzt, den ich bisher verwendet hatte, was aber auch bedeutet, dass es erst mal dauert, bis etwas zu sehen ist. Besser wäre es, wenn die Daten jeden Tag automatisch ausgewertet werden und das Dashboard dann einfach nur die aggregierten Daten abruft. Steht auf meiner Aufgabenliste.
Dann wäre es schön, wenn man in der Tabelle auf einen Eintrag klicken könnte, um dann diesen weiter zu analysieren. Steht auch auf meiner Aufgabenliste.
Eine Verbindung zu Google Analytics wäre toll.
Nicht jedes Keyword ist interessant und sollte in den Report kommen.
Alles gute Punkte, die ich beizeiten mal angehen könnte, und vor allem guter Stoff für weitere Posts Und ich bin immer offen für weitere Ideen
Fazit
Mit etwas Gehirnschmalz, wenig Code und der Hilfe von Amazon Web Services und R haben wir ein automatisiertes und kostenloses SEO-Reporting gebaut. Natürlich bieten Sistrix & Co noch mehr Funktionen. In diesem Ansatz geht es vor allem darum, die kostenlos zur Verfügung stehenden Daten aus der Webmaster Console besser zu nutzen. Denn sind wir mal ehrlich: Daten haben wir in der Regel genug. Wir machen nur meistens nicht viel daraus.
Diese Vorgehensweise hat noch einen Vorteil: Die Daten aus der Search Console sind nach 90 Tagen weg. Man kann nicht weiter zurück schauen. Hier aber bauen wir ein Archiv auf und können uns auch längerfristige Entwicklungen ansehen.
Dazu schauen wir erst einmal, was ein Sichtbarkeitsindex überhaupt leisten soll. Bei Sistrix ist der Sichtbarkeitsindex unabhängig von saisonalen Effekten, was ganz charmant ist, denn so weiß man schon im Sommer, ob man mit winterreifen.de einen Blumentopf gewinnen kann. Sowas kann zum Beispiel dadurch gelöst werden, dass man die durchschnittliche Anzahl von Suchen aus dem AdWords Keyword Planner nutzt. Dumm nur, dass dieses Tool nur noch dann einigermaßen nützliche Werte ausspuckt, wenn man auch ausreichend Budget in Google AdWords ausgibt. Dieser Ansatz fällt schon mal flach, denn wir wollen unser Monitoring so günstig wie möglich, bestenfalls kostenlos halten.
Sistrix hat den Nachteil, dass es a) für Studenten, die meine SEO-Kurse besuchen, trotz des günstigen Preises immer noch zu teuer ist und b) meine kleinen Nischengeschichten eben nicht immer vorhanden sind in der Sistrix-Keyword-Datenbank. Sistrix und Co. sind vor allem dann spannend, wenn man eine Seite mit anderen Seiten vergleichen will (idealerweise aus der gleichen Industrie mit dem gleichen Portfolio). Eine abstrakte Zahl wie ein Sichtbarkeitsindex von 2 ist ansonsten ziemlich sinnfrei. Diese Zahl ergibt nur dann Sinn, wenn ich sie in Bezug zu anderen Webseiten setzen kann und/oder wenn ich daraus die Entwicklung meiner eigenen Webseiten-Rankings im Zeitverlauf verfolgen kann. Die Zahl selbst ist dabei immer noch nicht aussagekräftig, denn in was für einer Metrik wird gemessen? Wenn ich 2 Kilo abnehme, dann ist die Metrik klar. Aber 0,002 SI abnehmen? Wie viele Besucher sind das?
Wir wollen uns einen Index bauen, der es uns ermöglicht zu schauen, ob sich unser Ranking über sehr viele Keywords im Zeitverlauf verändert. Wie sich unsere Marktbegleiter entwickeln, das ließe sich nur ablesen, wenn man Google scrapte, und das ist nicht erlaubt.
Sichtbarkeitsindex auf Basis der Webmaster Console
Offensichtlich ist es besser, mit einem Suchbegriff auf Platz 3 zu ranken, der 100 Mal am Tag gesucht wird als für einen Suchbegriff auf Platz 1, der nur 2 Mal am Tag gesucht wird. Die Anzahl der Suchen sollte also eine Rolle spielen in unserem Sichtbarkeitsindex. Das Suchvolumen über den AdWords Keyword Planner schließen wir aus den oben genannten Gründen aus, die einzige Quelle, die uns bleibt, sind die Impressions aus der Webmaster Console. Sobald wir auf der ersten Seite sind und weit genug oben (ich bin nicht sicher, ob es als Impression zählt, wenn man auf Platz 10 ist und nie im sichtbaren Bereich war), sollten wir die Anzahl der Impressions aus der Webmaster Console nutzen können, und das sogar auf Tagesbasis!
Kleiner Health-Check für das Keyword “Scalable Capital Erfahrungen” (AdWords / reale Daten aus der Webmaster Console):
2400 / 1795 (September, aber nur halber Monat)
5400 / 5438 (Oktober)
1000 / 1789 (November)
Für September und Oktober sieht das gut aus, nur im November ist es etwas seltsam, dass ich knapp 80% mehr Impressions hatte als es angeblich Suchen gab. Irgendetwas muß ausserdem im September/Oktober passiert sein, dass Scalable Capital plötzlich so viele Suchen hatte. Tatsächlich war das auch im Traffic auf meiner Seite zu sehen. Den ersten Punkt kriegen wir nicht geklärt und akzeptieren, dass auch die AdWords-Zahlen nicht perfekt sind.
Wie unterschiedlich die Sichtbarkeits-Indices sind je nach Gewichtung, wird in den folgenden Abbildungen deutlich:
Im einfachsten Modell wird einfach nur 11 minus Position gerechnet, alles oberhalb von (größer als) Position 10 bekommt dann 1 Punkt. Pro Ergebnis werden die Daten für jeden Tag zusammengerechnet. Dieses Modell hat den Nachteil, dass ich ganz schnell nach oben klettern kann, selbst wenn ich nur Begriffe auf Platz 1 bin, die nur einmal im Monat gesucht werden.
Im zweiten Modell wird das gleiche Vorgehen gewählt, nur dass hier der Wert mit den Impressions multipliziert wird
Im dritten Modell wird die durchschnittliche CTR auf der SERP aus dem zweiten Teil dieser Serie mit den Impressions multipliziert.
Schaut man sich nun den tatsächlichen Traffic an, so sieht man, dass das 3. Modell dem Traffic schon sehr nahe kommt. Die Ausschläge im echten Traffic sind nicht ganz so stark wie im Index, und zum Schluss bekomme ich nicht so viel Traffic, allerdings kann das daran liegen, dass die tatsächliche CTR unter der erwarteten CTR liegt.
Alternativer Ansatz mit der Webmaster Console
Wenn man sich die Plots anschaut, dann wird aber klar, dass dieser Ansatz mit dem Impressions auf Tagesbasis wenig Sinn ergibt. Denn wenn die Kurve nach unten geht, dann bedeutet das nicht, dass ich auch etwas tun kann, denn eventuell wird nun mal einfach nur weniger nach diesem Thema gesucht und meine Rankings haben sich gar nicht geändert (normalerweise schreibt man ja nur darüber, was funktioniert, aber ich finde auch die Misserfolge spannend, denn daraus kann man eine Menge lernen :-)). Genau deswegen wird Sistrix wohl auch die saisonalen Schwankungen rausrechnen.
Alternativ könnte man einfach den Durchschnitt über alle Impression-Daten eines Keyword-Landing-Page-Paares bilden und diesen Durchschnitt zur Berechnung nutzen, wieder mit der gewichteten CTR pro Position. Das Gute an diesem Ansatz ist, dass sich saisonale oder temporäre Ausschläge ausgleichen. Geplottet sieht das wie folgt aus:
Dieser Plot sieht dem ersten Plot sehr ähnlich, was aber nicht bedeutet, dass das immer so sein muss. Doch wenn ich mir die Sistrix-Werte anschaue (auch wenn ich da auf einem ganz niedrigen Niveau unterwegs bin), dann sieht das schon sehr ähnlich aus.
Von Daten zur Handlungsrelevanz
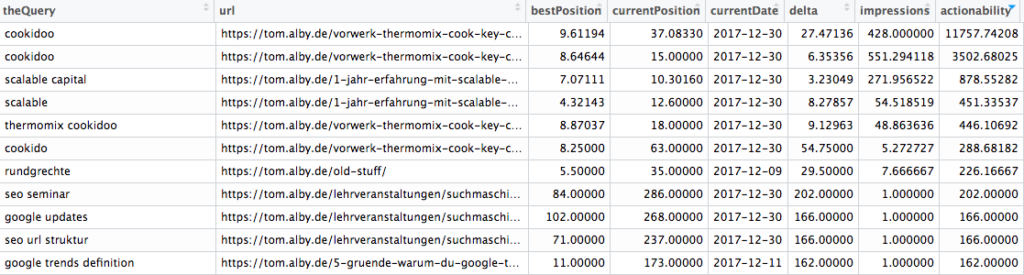
Nun haben wir einen Plot, der uns die gewichtete Entwicklung unserer Rankings anzeigt, aber was machen wir nun damit? So richtig “actionable” ist das nicht. Spannend wird es erst, wenn wir uns zusätzlich anschauen, welche Rankings sich am meisten verändert und einen Einfluss auf unseren Sichtbarkeitsindex haben. Dazu nehmen wir uns wieder für jedes Keyword-Landing-Page-Paar zunächst das minimalste Ranking (minimal weil niedrig, und niedriger als Platz 1 gehts nicht) und dann das aktuelle Ranking. Zum Schluss berechnen wir das Delta und sortieren danach:
Je höher das Delta, desto größer ist sozusagen der Verlust an Ranking-Plätzen. Und desto größer der Handlungsbedarf, vorausgesetzt, dass das Keyword auch wirklich interessant ist. In meinem Beispiel fände ich es zum Beispiel nicht schlecht für “seo monitoring” zu ranken, schließlich sind die Artikel aus dieser Reihe relevant dafür. Man könnte nun noch gewichten anhand der Impressions oder dem Sichtbarkeitsindex, den wir vorher gewählt haben:
Das sieht schon spannender aus: Tatsächlich sind einige Suchanfragen oben (nach “Actionability” sortiert), die ich ganz interessant finde. Und nun könnte man das mit den Daten aus dem zweiten Teil verbinden und ein Dashboard bauen… dazu mehr im vierten Teil
Most real life statistical problems have one or more nonstandard features. There are no routine statistical questions; only questionable statistical routines.
In dem ersten Teil ging es darum, wie mit R und einer zunächst kostenlosen AWS-Instanz ein automatisiertes SEO-Monitoring erstellt wird. Dabei wird die Webmaster Console per API jeden Tag abgefragt, und die Daten werden in eine Datenbank geschrieben. Das Datensammeln allein bringt natürlich nichts, irgendwas sollten wir damit auch anfangen, und mein Mantra, das jeder Student in meinen Veranstaltungen mehrmals pro Tag hört, ist “Daten – Information – Aktion”. In den meisten Abhandlungen steht Wissen an der Stelle von Aktion, denn die Verarbeitung von Informationen erst schafft Wissen. Im Bereich der Datenanalyse oder sogar Data Science aber geht es häufiger darum, nicht nur zu wissen, sondern mit dem Wissen auch etwas zu tun, idealerweise zu wissen, was zu tun ist. Der Grund, warum die meisten Reportings nicht gelesen werden, ist in der Regel, dass keine Aktion abgeleitet werden kann. 5 Likes mehr diese Woche. Ja und? Was mache ich jetzt morgen anders? Wir wollen also nicht einfach nur ein SEO-Reporting bauen, sondern ein SEO-Reporting erstellen, das uns sagt, wo etwas zu tun ist und was man tun sollte. “Actionable” heißt es auf Neudeutsch, und eine richtig schöne Übersetzung gibt es tatsächlich nicht im Deutschen. “Handlungsrelevant”? Ist irgendwie nicht das Gleiche. Leben wir also zunächst mit diesem Begriff.
Der Mehrwert der Webmaster Console-API
Schauen wir uns erst einmal die Daten an, die wir aus der Webmaster Console bekommen haben. Hier ist nämlich schon eine Besonderheit zu sehen, die wir im Interface nicht bekommen. Dort bekommen wir entweder die Suchanfragen oder die Seiten, auf die die Nutzer nach dem Klick auf ein Suchergebnis kamen, aber nicht beides gleichzeitig. Das ist schon ein Mehrwert, denn wir können sozusagen Pärchen bilden aus Keyword und Landing Page. Eine Landing Page kann mehrere Keywords haben, umgekehrt übrigens auch, wenn für ein Keyword mehrere Seiten von einem Host ranken. Wir nutzen für unsere Auswertung diese Pärchen, um einen unique Identifier zu haben, zum Beispiel indem wir beides zusammenpacken und daraus einen MD5-Hash basteln (dem genauen Beobachter wird auffallen, dass die gleiche Kombination zwei Mal an einem Tag auftritt, aber das sieht nur so aus, denn die eine Version der URL hat noch ein /amp/ dahinter, was aber in der Tabelle nicht zu sehen ist).
Sollten wir das nicht schon beim Schreiben in die Tabelle getan haben, so tun wir es jetzt:
library(digest)<br /> i <- 1<br /> newResults <- results<br /> newResults["Hash"] <- NA<br /> for (i in i:nrow(newResults)) {<br /> newResults$Hash[i] <- digest(paste(newResults$query[i],newResults$page[i],sep=""))<br /> i <- i+1<br /> }
Sicherlich geht das mit apply noch hübscher, aber wir sind gerade im Hacker-Modus, nicht im Schön-Programmier-Modus
Eine weitere Besonderheit ist, dass wir uns wahrscheinlich im Interface nicht die Mühe machen werden, uns die Daten für jeden Tag einzeln anzuschauen. Das ist aber extrem hilfreich, denn die Voreinstellung in der Webmaster Console sind die letzten 28 Tage, und hier wird ein Durchschnitt für die einzelnen Werte berechnet. Die, die mich näher kennen, werden jetzt betreten auf den Boden schauen, denn ich sage hier immer wieder dasselbe: Der Durchschnitt, und zwar das arithmetische Mittel, ist der Feind der Statistik. Denn diese Art des Durschnitts zeigt uns nicht die Ausschläge. Dazu ein andermal mehr, wenn ich das Skript zur Datenanalyse-Veranstaltung mal online stelle. Der Punkt ist hier, dass ich im arithmetischen Mittel des Interfaces sehe, dass ein Keyword auf einer bestimmten Position gewesen ist in den letzten 28 Tagen, aber tatsächlich ist die Range pro Tag viel interessanter, denn wenn ich sie pro Tag abgreife, dann kann ich genauere Trends abbilden. Zu guter Letzt schenkt uns die Webmaster Console auch Impressions sowie Keywörter, die nicht in den Datenbanken der gängigen Tools zu finden sind. Sistrix, so sehr ich es auch liebgewonnen habe, findet mich nicht für “Cookidoo” oder “Scalable Capital”. Klar, ich könnte Sistrix meine Webmaster Console-Daten zur Verfügung stellen, aber das darf ich leider nicht bei jedem Projekt tun.
Da wir die Daten jeden Tag abfragen, können wir nun durch die Tabelle laufen und uns die Werte für den erstellten Identifer holen, so dass wir alle Werte für eine Keyword-Landingpage-Kombination erhalten und diese plotten können. Auf der x-Achse haben wir den Zeitverlauf, auf der y-Achse die Position. Hier sind übrigens zwei kleine R-Tricks zu sehen. R plottet nämlich normalerweise auf der Y-Achse vom niedrigen Wert nach oben zu einem höheren Wert. Und dann wird genau der Bereich erwischt, der für uns interessant ist, nämlich nicht alle Positionen von 1 bis 100, sondern nur der Bereich, wofür gerankt wurde. Der Plot benötigt nur wenige Zeilen Code:
Wir sehen auf unserem Plot die Entwicklung des Rankings für ein Keyword, aber so richtig “actionable” ist es noch nicht. Wir schauen uns nun einmal daneben die CTR an:
Je höher die Position, desto höher die Klickrate. Das ist offensichtlich. Aber in diesen beiden Plots sieht man, dass zuerst die Klickrate runterging und dann die Position. Nicht dass die Klickrate der einzige Rankingfaktor wäre, aber eine schlechte Klickrate auf ein Ergebnis zeugt von einer suboptimalen wahrgenommenen Relevanz, und keine Suchmaschine möchte, dass die Ergebnisse als weniger relevant wahrgenommen werden. Hier wäre also ein Blick auf Titel und Description eine gute Handlungsempfehlung. Aber woher wissen wir eigentlich, was eine gute CTR für eine Position ist? Dazu können wir zum Beispiel einen Plot aus den eigenen Rankings nehmen:
Und diesen könnten wir vergleichen mit den Ergebnissen von Advanced Web Ranking, die Plots aus den Webmaster Console-Daten der Vielzahl ihrer Kunden erstellen. Jedes Land und jede Industrie ist anders, auch hängt die CTR von der SERP ab, ob vielleicht noch andere Elemente vorhanden sind, die die CTR beeinflussen. Aber allein aus dem Plot sieht man, dass bestimmte CTRs auf bestimmte Ergebnisse suboptimal sind. Hier müsste also “nur” noch ein Report erstellt werden, welche Keyword-Landingpage-Kombinationen unterdurchschnittlich sind.
Schauen wir uns den Plot mit den CTRs pro Position noch einmal genauer an, dann sehen wir ein paar ungewöhnliche Dinge. Zum einen gibt es immer ein paar Ergebnisse, wo ich egal auf welcher Position immer 100% CTR habe. Und dann gibt es zwischen den Positionen 1, 2, 3 und so weiter ganz viel Rauschen. Letzteres erklärt sich ganz leicht, denn die API gibt uns wie oben beschrieben durchschnittliche Positionen mit Nachkommastellen. Wir müssten also nur runden, um tatsächliche Positionen zu erhalten. Die 100% CTR betrifft vor allem Ergebnisse mit wenig Impressions. Werden zum Beispiel alle Ergebnisse rausgefiltert, die weniger als 10 Impressions pro Tag hatten, dann sieht das Bild schon anders aus:
Und siehe da, ich habe gar nicht so viele Nummer 1-Platzierungen mit mehr als einer homöopathischen Dosis an Impressions. Aber wenn ich die Augen etwas zukneife, so könnte ich eine Linie sehen. Und tatsächlich, berechnen wir die Mittelwerte (hier mit Summary), dann sehe ich eine nicht-lineare absteigende Kurve im Mean:<br /> Position 1:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.2143 0.3971 0.4929 0.4828 0.5786 0.7059<br /> Position 2:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.0000 0.2667 0.4118 0.3744 0.5000 0.7692<br /> Position 3:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.0000 0.1176 0.1818 0.2217 0.3205 0.5769<br /> Position 4:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.00000 0.08333 0.18182 0.17266 0.26667 0.45454<br /> Position 5:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.0000 0.1240 0.1579 0.1584 0.2053 0.3200<br /> Position 6:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.00000 0.06977 0.11765 0.12223 0.16667 0.30769<br /> Position 7:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.00000 0.05043 0.09091 0.09246 0.13229 0.22222<br /> Position 8:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.00000 0.00000 0.03880 0.04594 0.08052 0.19048<br /> Position 9:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.00000 0.00000 0.00000 0.01412 0.01205 0.16514<br /> Position 10:<br /> Min. 1st Qu. Median Mean 3rd Qu. Max.<br /> 0.000000 0.000000 0.000000 0.010284 0.004045 0.093023
Im nächsten Schritt müssen wir also “nur” noch auswerten, welches Ergebnis unter einer bestimmten Grenze der CTR liegt. Glücklicherweise existiert in der Statistik eine Maßzahl, die uns hilft, die Streuung um einen Mittelwert zu identifizieren, die Standardabweichung. Diese wird hier jetzt nicht erklärt (aber im Skript zur Datenanalyse-Veranstaltung). Aber auf dem Weg zur Standardabweichung sollten wir uns eine Übersicht über die Verteilung der CTRs ansehen. Wie man schön sehen kann, sieht das nach einer Normalverteilung aus. Nun berechnen wir guten Gewissens die Standardabweichung pro Position:
Für die Position 1 könnten wir also rechnen Mittelwert minus Standardabweichung gleich Ergebnis mit Klickrate, das Beachtung verdient, hier
0.4828 - 0.139202 = 0.3436019
Alle Ergebnisse mit einer gerundeten Position 1 und einer CTR von 0.43… verdienen also Beachtung. In meinem Fall sind das die Suchanfragen für scalable capital erfahrung und cookidoo. Zwar gibt es auch CTRs an manchen Tagen über dem Durchschnitt, aber manchmal fallen sie drunter. Dies wird dann für jede Position wiederholt.
Zu viele Daten?
Wir haben nun ein Problem. Denn mein Blog ist noch eine relativ kleine Seite. Was machen wir mit einer Seite mit vielen Keywords und vielen Rankings? Dazu kommen wir beim nächsten Mal, indem wir einen eigenen Sichtbarkeitsindex erstellen.
Langsam hält R Einzug in die Welt der Suchmaschinenoptimierung, und auch wenn R am Anfang etwas verwirrend sein mag (funktionale Programmierung anstatt prozedural), so kann man mit wenigen Zeilen Code coole Sachen bauen. Als Beispiel soll hier ein kostenloses SEO-Monitoring dienen, das natürlich kein bisschen mit Sistrix und Co mithalten kann, aber wenn man nur seine eigenen Rankings verfolgen will, dann ist dies eine tolle und vor allem kostenlose Lösung.
Fangen wir mit der Infrastruktur an, wir benötigen nur drei Komponenten:
Eine (kostenlose) EC2-Instanz
Einen Google Webmaster-Account
Einen Google API-Service Account
Amazon bietet EC2-Instanzen im “free tier” (kostenlosen Kontingent) an, nach 12 Monaten wird hier zwar eine Gebühr fällig, aber die ist eher im homöopathischen Bereich. Die t2.micro-Instanz ist relativ schwach auf der Brust mit ihrer einen vCPU, 1GB RAM und 30GB SSD, aber für unsere Zwecke reicht sie vollkommen aus. R ist natürlich nicht von vornherein vorhanden, ABER Luis Aslett bietet kostenlose AMIs (Amazon Machine Images) an, wo RStudio Server bereits vorkonfiguriert ist. Matt erklärt sehr gut, wie man mit diesen AMIs seine eigene RStudio-Instanz auf AWS installiert. Das alles dauert maximal 15 Minuten, schon hat man seinen eigenen kostenlosen RStudio Server-Rechner in der AWS-Cloud. Große Berechnungen sind damit nicht möglich, aber ist man erst einmal auf den Geschmack gekommen, so findet man sich schnell in der Situation wieder, dass mal kurz eine Instanz mit viel Speicher für größere Rechenaufgaben genutzt wird. Ein Klick, ein paar Euro am Tag, und schon hat man ein ganzes Cluster mit 16 Prozessoren und 128 GB RAM für sich. Aber ich schweife ab.
Im nächsten Schritt nehmen wir das R Package searchConsoleR von Mark Edmonson. Dies ist der elementare Grundstein unseres SEO-Monitoring. In Marks Beispiel schreibt er die Daten einfach auf Platte, aber wir wollen die Daten lieber in eine Datenbank schreiben (wie man MySQL auf unserer frisch erworbenen EC2-Instanz installiert steht hier. Bitte beachten, dass man nur einen Nutzer “ubuntu” hat, d.h. man muss alles mit sudo erledigen; ansonsten kann man kostenpflichtig auch eine RDS-Instanz buchen). Um von einem Server auf die Webmaster Console-Daten zugreifen zu können, wird ein Service Account benötigt. Dieser ist nicht ganz so einfach aufzusetzen, aber das würde den Rahmen dieses Artikels sprengen. Wichtig ist, dass die Mail-Adresse des Service Accounts als ganzer Nutzer in der Webmaster Console eingetragen wird. Und hier ist nun der Code:
Nun fehlt uns nur noch ein Cronjob, der täglich diese Abfrage durchführt. Dazu nutze ich zunächst ein kleines Shell-Skript, das dann das R-Skript aufruft:
cd /home/rstudio/SearchConsole/ Rscript /home/rstudio/SearchConsole/rankings.R
Dann wird mit sudo crontab -e der Cronjob eingerichtet, mein Cronjob startet jeden Tag um 10:30, bzw 11:30, denn die Instanz ist in einer anderen Zeitzone:
Wichtig: Newline nach der letzten Zeile, sonst meckert cron. Fertig ist das automatische und kostenlose SEO-Monitoring! In einem der nächsten Postings zeige ich, wie man die Daten dann auswerten kann.
Aufgrund meiner Vergesslichkeit hatte ein cron job mehr als 3 Millionen Dateien in einem Verzeichnis angesammelt, die ich nun verarbeiten wollte. Damit mein Skript nicht tagelang daran arbeitet (mehr 60 GB an Daten!), sollten die Dateien in kleinere Häppchen verteilt werden. Leider kam mv nicht damit klar, es beschwerte sich mit “argument list too long”. Die Abhilfe schafft eine Kombination von Kommandozeilen-Befehlen:
Manche Fragen lassen sich nicht so einfach oder auch gar nicht mit der Benutzeroberfläche von Google Analytics beantworten (das gilt übrigens auch für Adobe Analytics, Piwik, etc). Zwar bietet Google Analytics eine mächtige und einfach zu nutzende Funktionalität an, um Segmente oder Personas basierend auf Geräte, Akquisitionskanäle oder Browser manuell zu bilden und miteinander zu vergleichen, aber sobald es über diese Standardsegmente hinaus oder zu Kombinationen mehrerer Dimensionen geht, wird der Aufwand komplex. Oft genug wird dann auch einfach nur in den Daten “gestochert” und gehofft, dass man etwas Wertvolles findet. Genau hier kommen die Vorteile der Kombination von Google Analytics und R ins Spiel. Eine Möglichkeit, Google Analytics und R miteinander zu verbinden ist das R Package googleAnalyticsR von Mark Edmonson, das in diesem Artikel beispielhaft verwendet wird.
Segmentierung, Clustering und Klassifizierung
Bevor wir ins Praktische gehen, soll noch einmal kurz der Unterschied zwischen Segmentierung, Clustering und Klassifizierung erläutert werden. Bei einer Segmentierung wird versucht, Kunden oder Nutzer in Gruppen zu unterteilen, die sich anhand von Merkmalen unterscheiden, sei es ein Interesse, ein Zugangskanal, eine Marketingkampagne, über die ein Kunde kam, usw. Bei Clustering wird versucht, solche Gruppen und die sie jeweils unterscheidenden Dimensionen oder Features automatisiert zu identifizieren, wohingegen bei der Klassifizierung versucht wird vorherzusagen, zu welcher Gruppe ein Kunde oder Nutzer gehört. Klassifizierung ist ein gutes Beispiel für supervised Machine Learning, Clustering ein gutes Beispiel für unsupervised Machine Learning. Nicht immer kommt etwas Sinnvolles heraus, daher der häufige Gebrauch des Wortes “versucht”
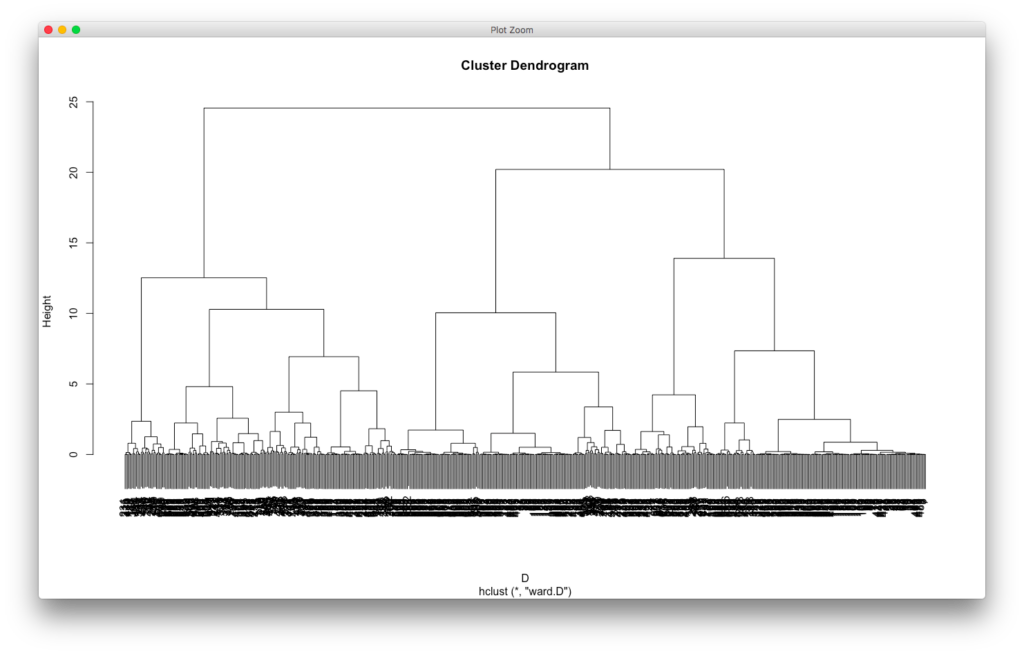
In diesem Beispiel geht es um Clustering, also das Identifizieren von Gruppen auf Basis von Strukturen in den Daten mit Machine Learning-Algorithmen. Im Hierarchical Clustering werden Gruppen anhand ihrer Ähnlichkeit identifiziert, beginnend mit einem eigenen Cluster für jeden Datenpunkt und auf jeder weiteren Ebene mehr Cluster anhand der jeweiligen Ähnlichkeit zusammenzufassend, bis alle Cluster zusammengeführt sind (siehe das Dendrogram). Ein toller Algorithmus, der idealerweise numerische Daten als Input benötigt, denn Ähnlichkeit wird hier als Distanz berechnet. Zwar könnte man mit DAISY auch nicht-numerische Daten verwenden, aber für den ersten Schritt führt das zu weit.
Für unser Beispiel verwenden wir einen anderen Ansatz, wir wollen einfach nur herausfinden, ob Cluster auf Basis der angesehenen Inhalte oder Produkte einer Seite gebildet werden können. So vermute ich, dass die Besucher dieser Website, die sich Roller Derby-Fotos ansehen, sehr wahrscheinlich nicht an den Artikeln über Fintechs interessiert sind. Aber vielleicht interessieren sich die Google Analytics-Artikel-Leser für Fintechs, so dass ihnen Artikel zu diesem Thema angeboten werden könnten. Wir kennen das von Amazon (“Wird oft zusammen gekauft”), und meistens sind die Vorschläge nützlich. Natürlich kann ich mir auch den Nutzerfluss-Bericht in Google Analytics ansehen (bei den wenigen Seiten auf meiner Homepage reicht das auch völlig aus), aber sobald mehr Seiten oder Produkte vorhanden sind, kommen wir mit diesem Bericht nicht weiter. Hier helfen uns Association Rules weiter, auch als Market Basket Analysis bekannt (mit einem der Schöpfer, Tomas Imielinski, habe ich bei Ask.com sogar mal zusammengearbeitet). Dieser Machine Learning-basierte Ansatz versucht interessante Beziehungen zwischen Variablen in großen Datenbeständen zu identifizieren.
Generell hängt die Auswahl eines Algorithmus auch und vor allem zunächst einmal von dem Business-Problem ab, das gelöst werden soll. Dies ist ein extrem wichtiger Punkt: Welche Frage wollen wir eigentlich beantworten? In diesem Fall kann ich nur die Frage beantworten, welche Seiten in einem “Warenkorb” gelandet sind auf Basis der Nutzung durch Webseitenbesucher. Natürlich könnte ich eine “Ähnlichkeit” auch auf Basis des Inhalts maschinell berechnen.
Augen auf bei der Interpretation der Ergebnisse
Zunächst aber erst einmal eine fette Warnung: Das, was sich die Nutzer ansehen, hängt zu einem großen Maße auch davon ab, wie die Navigation oder weitere Elemente auf der Seite ausssehen. Wenn auf der Seite zum Beispiel schon ein Empfehlungssystem wie YARPP eingebunden ist, dann ist allein aufgrund dieses Plugins die Wahrscheinlichkeit höher, dass manche Seiten eher zusammen mit anderen Seiten aufgerufen werden. Aber auch Kleinigkeiten auf einer Seite können dazu führen, dass Zusammenhänge gesehen werden, die eigentlich gar nicht da sind, und sei es nur ein kleines Icon, dass die Aufmerksamkeit der Nutzer auf sich zieht und zum Klicken verführt.
Dann sollte auch noch darauf hingewiesen werden, dass das Ansehen von Seiten ein nicht ganz so starkes Signal ist wie das Kaufen eines Produktes. Nur weil jemand eine Seite aufruft, heißt das noch lange nicht, dass die Person auch lange auf dieser Seite geblieben und den Text gelesen hat. Man könnte das einfließen lassen, indem man zum Beispiel die Verweildauer auf der jeweiligen Seite misst und nur die Kombinationen zulässt, wo “genug” Zeit verbracht wurde, aber die Verweildauer in den Web Analyse-Systemen ist leider häufig unbrauchbar.
Voraussetzungen
Für das Clustering mit Google Analytics und R werden Analytics-Daten auf User-Level benötigt, das heißt, dass die Nutzer einer Standard-Installation der kostenlosen Variante von Google Analytics nicht ohne Weiteres ein Clustering durchführen können. Die Standard-Variante verfügt zwar über den neuen Nutzer-Explorer, über den man sich das Verhalten einzelner anonymisierter Nutzer anschauen kann, aber diese Daten sind nicht herunterladbar. Lediglich die Käufer der Pro-Variante können a priori auf User-Level Daten zugreifen, in der kostenlosen Variante sind nur aggregierte Daten im Angebot. Allerdings gibt es einen kleinen Hack, mit dem man das ändern kann, ansonsten ist hier ein weiteres Argument für Piwik zumindest als Zweitsystem. Der Vorteil von Piwik ist neben Zugriff auf die Rohdaten unter anderem auch, dass die Daten sofort zur Verfügung stehen. Und auch für Piwik existiert ein R Package. Aber in diesem Artikel soll die Lösung mit Google Analytics und R gezeigt werden.
Google Analytics und R mit googleAnalyticsR verbinden
Nun gehts ans Eingemachte. Ich werde nicht erklären, wie man ein R Package installiert, für das, was wir vorhaben, wird zum einen das Package googleAnalyticsR und das Package googleAuthR benötigt, zum andern das Package arules. Die R-Hilfe ist Dein Freund.
Wir laden zunächst einmal die beiden Packages und melden uns dann mit einem Google-Konto an (dafür geht ein Browser-Fenster auf):
Ist man übrigens bereits angemeldet und möchte auf ein anderes Konto wechseln, so gibt man
ga_auth(new_user = TRUE)
ein und meldet sich mit dem anderen Konto an. Als nächstes holen wir uns die Liste unserer Accounts und Properties, die mit diesem Google Account verbunden sind:
my_accounts <- ga_account_list()
In diesem Datenframe suchen wir in der Spalte viewName nach der Datenansicht, die wir verwenden wollen, und suchen in der Zeile nach der viewId. Diese viewId ist elementar, da wir mit ihr die Daten unserer Datenansicht abrufen werden. Wir speichern die viewID in einer Variable:
ga_id=XXXXXX
wobei XXXXXX für die viewId steht. Welche Daten stehen uns nun zur Verfügung? Einfach
meta <- google_analytics_meta()
eingeben und alle Dimensionen und Metriken sind im Data Frame meta abrufbar. Uns interessiert vor allem die Custom Dimension 1, in der die User Level ID gespeichert ist, und ga:pagePath:
In meinem Dataframe gadata habe ich nun die Daten wie oben beschrieben plus zwei weitere Spalten (sessions und bounceRate), da mir GA die Dimensionen nicht ohne Metriken ausgibt. Die Daten müssen transformiert werden, so dass sie ungefähr so aussehen:
<br /> user id 1, page 1, page 2<br /> user id 2, page 1<br /> user id 3, page 3
Dies geschieht mit dem Code
i <- split(gadata$pagePath,gadata$dimension1)
Wir haben jetzt jede “Transaktion” eines Nutzers in einer Zeile. Dies ist der benötigte Input für unseren Algorithmus.
Market Basket Analysis
Jetzt ist der Zeitpunkt, das R Package arules zu laden und die Daten für den Algorithmus zu modifizieren:
Beim Aufruf des Algorithmus werden die Parameter sup für Support und conf für Confidence genutzt, d.h. wir sagen ihm im folgenden Beispiel, dass wir Regeln haben wollen, die mindestens in 0,1% der Fälle anwendbar sind und bei denen eine Konfidenz von 0,1% besteht. Das klingt erst einmal verdammt wenig, aber stellen wir uns vor, dass wir es mit einem “Warenkorb” zu tun haben, in den ganz viele verschiedene Kombinationen “gelegt” werden können, je nach Größe eines Online-Shops oder einer Webseite. Natürlich wollen wir mit den Regeln so viele Vorgänge wie möglich abdecken, aber je mehr Möglichkeiten vorhanden sind, desto wahrscheinlicher ist es, dass wir mit einem niedrigen Support-Wert hineingehen müssen.
Hier kann ganz schön viel Prozessorzeit und Arbeitsspeicher draufgehen, und je nach Ausstattung beendet R den Prozess mit einer Fehlermeldung. Eine Möglichkeit, den Algorithmus zu begrenzen, ist, die Parameter sup und/oder conf zu vergrößern. Ist alles gut gegangen, so können die identifizierten Regeln begutachtet werden:
inspect(head(sort(basket_rules, by="lift"),20))
Hiermit werden die Top 20 Regeln angezeigt, sortiert nacht Lift. Der Lift sagt uns, wie viel höher die Abhängigkeit der Items ist im Vergleich zu ihrer Unabhängigkeit, von der man bei einem Lift von 1 ausgehen muss. Der Output bei mir sieht wie folgt aus (nicht für diese Webseite):
Regel zwei sagt zum Beispiel aus, dass ein kleiner Teil der Transaktionen beinhaltet, dass ein Nutzer sich einen Artikel über Kommunikationsmethoden anschaut und mit einer Konfidenz von 30% auch den Artikel über Kommunikationstechnologie lesen wird. Diese Verbindung hat einen extrem hohen Lift von 521, so dass wir davon ausgehen können, dass diese Verbindung viel wahrscheinlicher ist als ihr zufällig gemeinsames Auftreten.
Zusammenfassung Google Analytics und R
Dieses kleine Beispiel zeigt die Mächtigkeit von R und den Packages. Mit wenigen Zeilen Code können Daten ohne Umwege aus Google Analytics in R importiert und für komplexe Analysen verwendet werden. Diese Analyse wäre in der Benutzeroberfläche nicht möglich gewesen.
Wir sehen hier aber auch, wie wichtig es ist, Daten auf User-Level zu haben, wobei einschränkend gesagt werden muss, dass wir es hier nicht einmal mit User-Level-Daten zu haben, sondern mangels Cross-Device-Tracking eher mit Browser-Level-Daten. Eine nächster Schritt könnte also sein, dass die identifizierten Regeln noch mal auf Basis von segmentierten Daten erstellt werden, um Unterschiede zu identifizieren.
Da gerade die Canon 5d Mark IV herausgekommen ist, wird auch die 5d Mark III erschwinglich. 1.500€ für maximal 30.000 Auslösungen wurde mir geraten, aber wenn man sich die angebotenen Kameras bei eBay und den einschlägigen Foren ansieht, dann scheint der Preis viel höher zu sein. Doch was ist der faire Preis? Mit ausreichend Daten kann dieser durch Regression ermittelt werden.
Gehen wir zunächst mal davon aus, dass eine Kamera umso günstiger wird, je mehr Auslösungen sie hat. 150.000 Auslösungen ist die erwartete Lebensdauer des Auslösers bei der 5d Mark III, ein neuer Auslöser inklusive Arbeit kostet ca 450€ (nicht verifiziert). Doch schauen wir uns erst mal an, wie die Daten aussehen. Ich habe von den verschiedenen Plattformen die Preise und Auslösungen von knapp 30 Angeboten herausgesucht, das berücksichtigt also nicht, wie gut die Kamera äußerlich ist oder welches Zubehör dabei ist. Diese Daten werden in R eingelesen und auf ihre Merkmale untersucht:
Wir haben einen Durchschnittspreis von 1.666€ und eine durchschnittliche Anzahl von Auslösungen von 85.891. Das ist weit entfernt von den 1.500€ bei 30.000 Auslösungen. Auch beim Median sieht es nicht viel besser aus. Nun starten wir die Regression und bilden ein Regressions-Modell mit der Funktion lm und schauen uns die Details an mit dem Befehl summary(MODELLNAME):
Hieraus können wir schon eine Funktion bilden:
Preis = -0,001749x+1816 wobei x die Anzahl der Auslösungen ist. Eine Kamera mit 30.000 Auslösungen sollte also 1.763,53€ kosten, eine Kamera mit 100.000 Auslösungen immer noch 1.614€. Schauen wir uns noch den Plot dazu an:
Wie man schön sehen kann haben wir einige Ausreißer dabei (übrigens nicht wegen tollen Zubehörs oder einer Wartung etc), die das Modell etwas “verbiegen”. Eine Kamera mit knapp 400.000 Auslösungen und einem Preis von immer noch 1.000€ hatte ich bereits rausgenommen.
Leider kann man die Anzahl der Auslösungen nicht automatisiert aus den Portalen auslesen, da sie immer vom Benutzer manuell eingegeben wird. Ansonsten könnte man für jedes Kameramodell ein schönes Tool daraus bauen