Wenn man mit R automatisiert auf APIs zugreifen will, dann ist die Authoritisierung via Browser keine Option. Die Lösung nennt sich Service User: Mit einem Service User und dem dazu gehörenden JSON-File kann ein R-Programm auf die Google Analytics API, die Google Search Console API, aber auch all die anderen wunderbaren Machine Learning APIs zugreifen Dieses kurze Tutorial zeigt, was für die Anbindung an die Google Search Console getan werden muss.
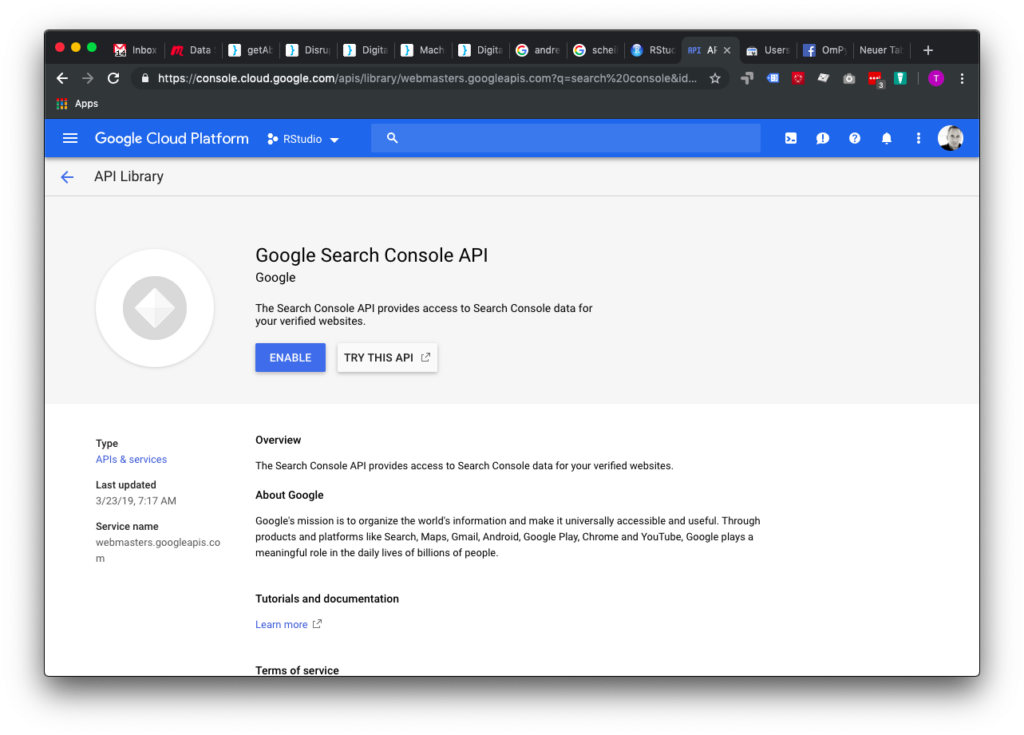
Zunächst legt man ein Projekt an, wenn man noch kein Passendes hat, und dann müssen die passenden APIs enabled werden. Nach einer kurzen Suche findet man die Google Search Console API, die nur noch aktiviert werden muss.
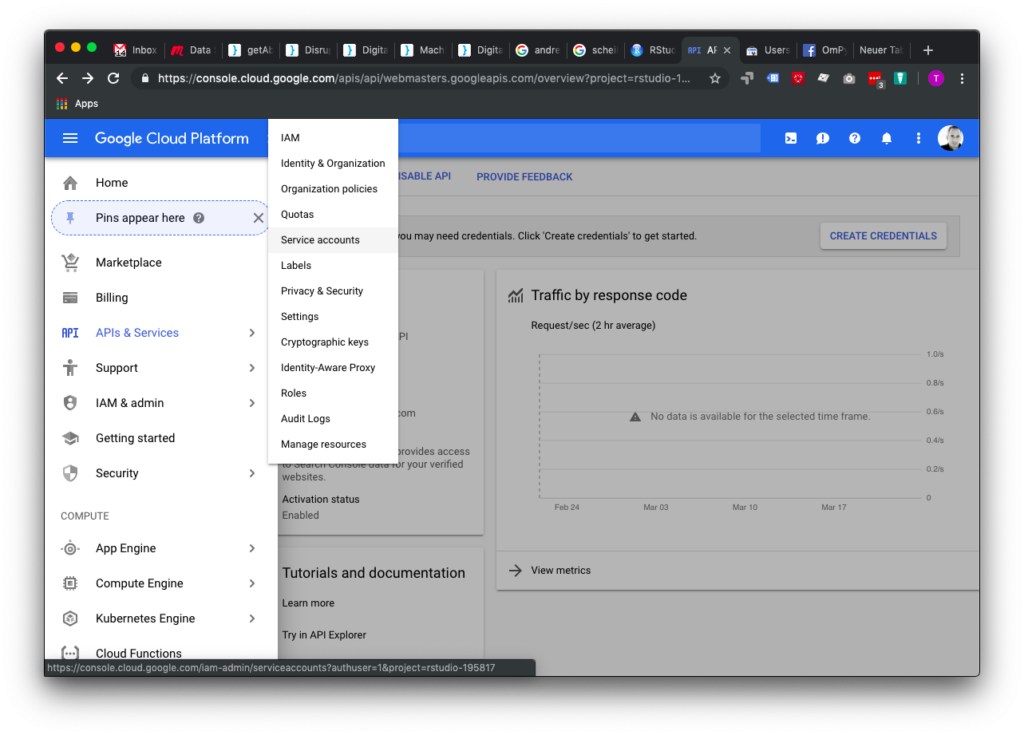
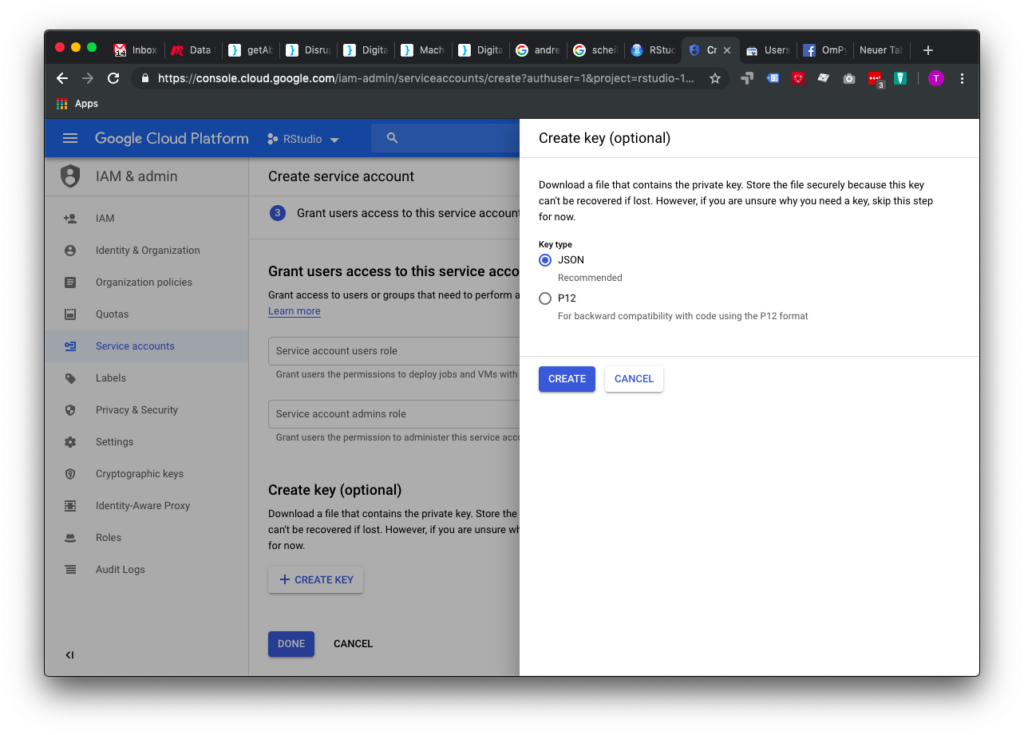
Auf IAM & admin klicken und dann auf Sevice accounts (ist irgendwie seltsam gehighlighted in diesem Screenshot:
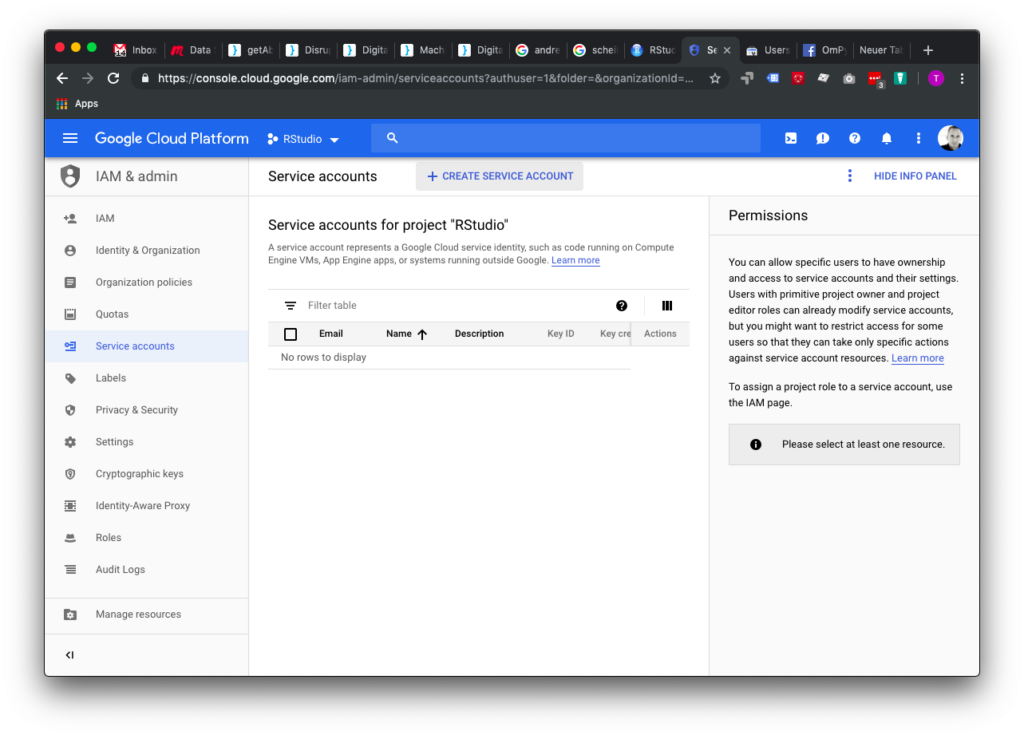
Auf Create Service Account klicken:
Wichtig: Einen sinnvollen Namen geben für die Mail-Adresse, damit man wenigstens etwas die Übersicht behält…
Browse Project reicht bei diesem Schritt:
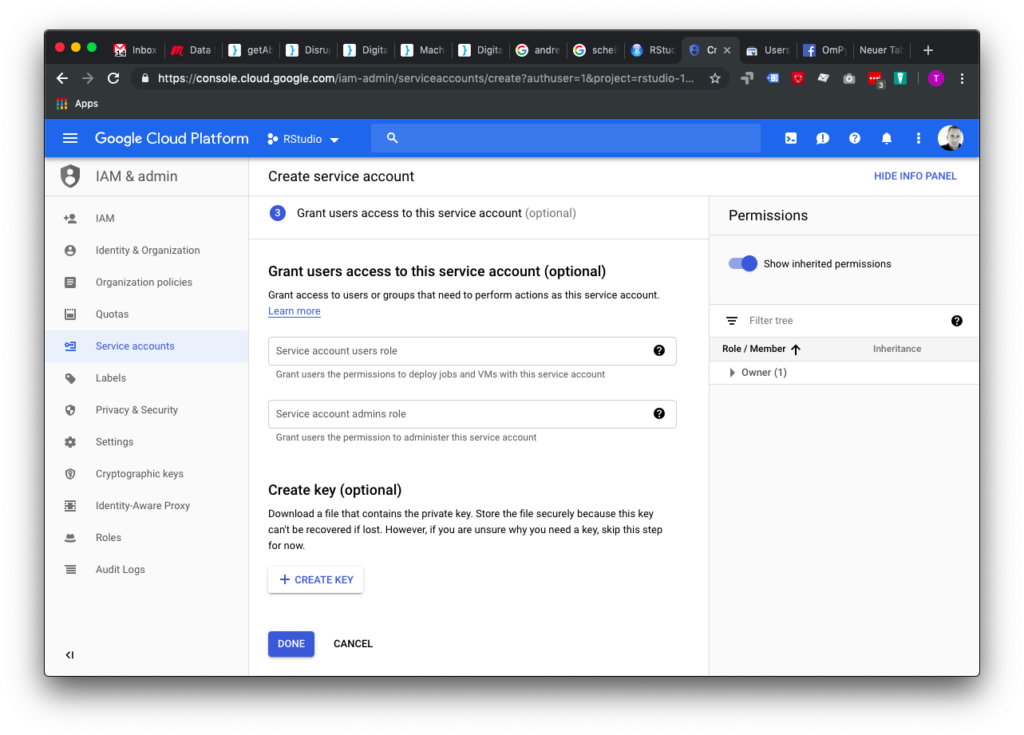
Hier auf “Create Key” klicken:
JSON-Key erstellen, runterladen und dann in das gewünschte RStudio-Verzeichnis legen.
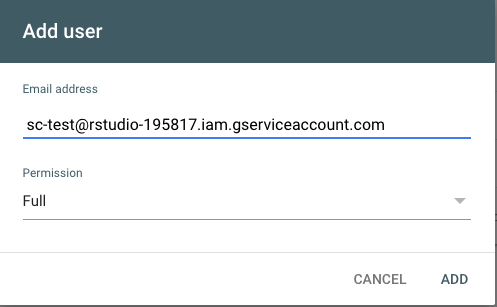
Nun muss der Service User noch als User in der Search Console hinzugefügt werden; wichtig ist, dass er alle Rechte erhält.
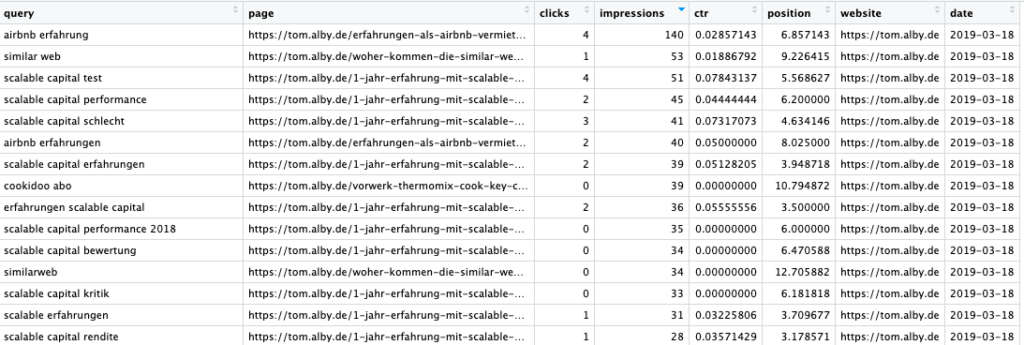
Was wirklich toll ist an der Google Search Console API: Man sieht Query und Landing Page gleichzeitig, anders als in der GUI. Ich hole mir die Daten übrigens jeden Tag und schreibe sie in eine Datenbank, so dass ich eine schöne Historie habe, die über die paar Monate der Search Console hinausgehen.
Zu guter Letzt stelle ich auch noch das R Notebook zur Verfügung, mit dem ich die Daten abfrage; es ist grundsätzlich der Code, den der Autor der API, Mark Edmondson, geschrieben hat, aber nur der Vollständigkeit halber, wie die JSON-Datei eingebunden wird. Es gibt noch eine elegantere Variante mit R Environment Variablen, aber ich weiß nicht, ob die unter Windows funktioniert.
Ich habe den Sinn eines bestimmten Diagramms in Google Analytics nie verstanden, und zwar den des Tortendiagramms, das das Verhältnis der neuen Nutzer zu den wiederkehrenden Nutzern zeigt. Es war früher im Standard-Dashboard, das ein Nutzer nach dem Login sah, und ich hatte mich immer für dieses Diagramm entschuldigt, wenn ich während meiner Zeit bei Google eine Google Analytics-Demo gezeigt hatte.
Tortendiagramm: Nur für statische Zusammensetzungen
Was ist so schlimm an diesem Diagramm? Zunächst einmal wird ein Tortendiagramm für statische Zusammenstellungen verwendet. Wenn ich wissen möchte, wie die Geschlechteraufteilung meines Kurses ist, dann ergibt ein Tortendiagramm Sinn. Die Geschlechter werden sich größtenteils nicht ändern während des Kurses.
Die meisten Webseiten wollen aber die Anzahl ihrer Besucher erhöhen, sei es durch neue Nutzer, wiederkehrende Nutzer oder beides. Eine Entwicklung ist also das Ziel, und somit ist ein Tortendiagramm nicht sinnvoll, da es ja statische Konstellationen zeigt. Ein Liniendiagramm, das die Entwicklung über die Zeit zeigt, ist in den meisten Fällen sicherlich eine bessere Wahl.
Die beiden Metriken sind unabhängig voneinander
Ich gehe jetzt aber noch einen Schritt weiter und behaupte, dass diese beiden Metriken nichts miteinander zu tun haben und deswegen auch nie in einem Diagramm dargestellt werden sollten. Neue Benutzer können wiederkehrende Nutzer werden, müssen es aber nicht. Und wiederkehrende Nutzer können in dem gleichen Zeitraum auch neue Nutzer gewesen sein, sie werden dann zwei Mal gezählt. Wenn ein Nutzer also in beiden Teilen des Tortendiagramms auftauchen kann, was sagt das Verhältnis der beiden Teile zueinander dann aus?
Neue Nutzer entstehen durch Marketing. Idealerweise kommen wiederkehrende Nutzer dadurch zustande, dass die Inhalte so toll sind, dass die Nutzer nicht mehr ohne sie leben wollen. Wenn ich keine neuen Nutzer bekomme, dann muss ich mein Marketing optimieren. Wenn meine Nutzer nicht wiederkehren, dann muss ich meine Inhalte optimieren. Da wir immer auf der Jagd nach sogenannten “Actionable Insights” sind, warum sollten wir dann zwei Metriken in einem Diagramm darstellen, wenn sie unterschiedliche korrigierende Maßnahmen erfordern?
Außerdem: Ich kann zwei Wochen lang viel Geld für Marketing ausgeben, so dass sich der Anteil neuer Nutzer massiv erhöht und der Anteil wiederkehrender Nutzer in der Ratio dadurch stark verringert. Selbst wenn die absolute Zahl wiederkehrender Nutzer gleich bleibt, würde die Ratio uns vermitteln, dass wir weniger wiederkehrende Nutzer hätten. Aus diesem Grund sollten diese beiden Metriken nie zusammen als Ratio, sondern stets getrennt angezeigt werden. Serviervorschlag: Ein Graph mit der Entwicklung der neuen Nutzer mit den Akquisekanälen, ein Graph mit den wiederkehrenden Nutzern und den Inhalten, die für die Wiederkehr verantwortlich sein könnten.
Was ist eigentlich mit den nicht-wiederkehrenden Nutzern?
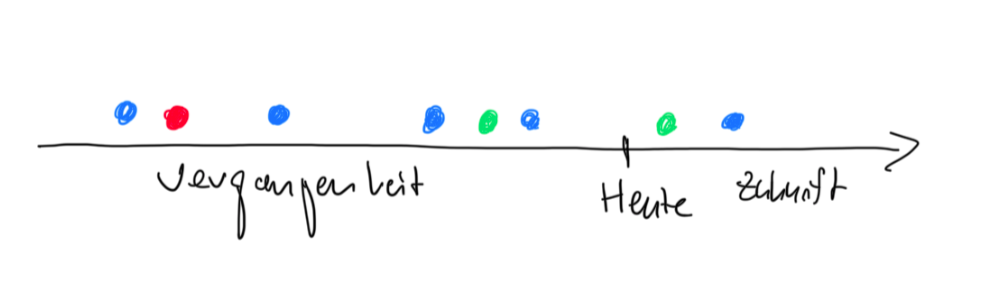
Diese Frage stellte heute eine Kursteilnehmerin, und diese Frage finde ich aus mehreren Gründen gut. Wir wissen nicht, ob neue Nutzer wiederkehrende Nutzer sein werden (abgesehen von denjenigen neuen Nutzern, die in unserem Zeitraum neu als auch wiederkehrend sind, weil sie 2 Mal kamen, aber sie könnten sich natürlich in der Zukunft gegen einen weiteren Besuch entscheiden). Insofern könnte jeder Nutzer, der einmal dagewesen ist, irgendwann einmal in der Zukunft wiederkommen. Technisch gesehen kann kein Nutzer, der seine Cookies gelöscht hat, als wiederkehrender Nutzer bei uns wieder auftauchen, von User ID-Gebrauch einmal abgesehen. Aber dennoch finde ich die Frage spannend, da ich mich in einem anderen Kontext mit ihr beschäftigt habe: Ab wann muss ich einen Kunden bei einem Produkt, das regelmäßig gekauft wird, als verloren ansehen?
Die Grafik soll meine Gedanken dazu verdeutlichen. Wir haben einen Punkt “Heute” und drei Nutzer, blau, rot und grün. Nutzer blau kommt in mehr oder weniger regelmäßigen Abständen vorbei. Bei dem Zeitpunkt “Heute” würde ich davon ausgehen, dass er auch in Zukunft wiederkommt, zumindest scheint die Wahrscheinlichkeit hoch zu sein. Nutzer grün war erst vor kurzem da. Er hatte vielleicht keine Chance, wiederzukommen. Nutzer rot war vor langer Zeit da, und verglichen mit den Zeitabständen, die Nutzer blau zwischen seinen Käufen hat, scheint die Wahrscheinlichkeit einer Wiederkehr gering zu sein. Er kann wiederkommen, aber ihn würde ich eher mit einem Incentive anlocken als Nutzer grün, der eventuell eh wiederkommen wird (pull-forward cannibalization).
Wir können also nichts Genaues über nicht-wiederkehrende Nutzer sagen, denn wir kennen die Zukunft nicht. Aber wir können mit Wahrscheinlichkeiten rechnen. Bei reinen Nutzern eventuell nicht so spannend. Aber bei Shop-Kunden schon spannender.
Ich habe in den letzten Wochen viel Zeit damit verbracht, unterschiedliche NAS-Konfigurationen zu testen. Kurzgefasst: Es lohnt sich nicht, eine NAS von QNAP oder Synology zu kaufen. Von meinen WD-Ausflügen will ich schon gar nicht mehr erzählen. Für alle diese Kaufsysteme gilt: Die Performance ist unterirdisch, die Sicherheit bedenklich, und überteuert sind diese Systeme auch. Die in diesem Artikel beschriebene Open Source-Lösung kann für sehr viel weniger Geld mehr Sicherheit und Geschwindigkeit bringen. Warum überhaupt eine eigene Cloud, das erklärt dieser Artikel sehr gut.
nextcloudPi
nextcloudPi ist ein wunderbares Projekt, das eine einfache Installation von nextcloud auf einem Single Board Computer ermöglicht, inklusive Memory-Cache (Redis) und SSL-Zertifikat. Single Board Computer sind kleine Mini-Computer wie der Raspberry Pi, die ab 30€ kosten und dennoch beachtliche Dinge leisten können. Die Installation von nextcloudPi ist wie gesagt einfach, aber noch nicht auf dem Stand, den ein DAU unfallfrei hinbekommen würde. Man kann schon ohne Kommandozeile das ganze System installieren und konfigurieren. Nur manche Begriffe wie dnsmasq sind eben nicht selbsterklärend. Vergleicht man diese Installationsroutine aber mit den Installationsanweisungen von Seafile, dann ist nextcloudPi ein Musterbeispiel dafür, wie man aus etwas Kompliziertem etwas Einfaches machen kann. Seafile ist ein kryptisches Monster, was die Installation betrifft, und das schreibe ich als Informatiker.
An nextcloud gefällt mir, dass anders als bei owncloud kein Geld für die Mobile App verlangt wird und das System irgendwie moderner, flüssiger wirkt. Die App ermöglicht auch, dass Fotos von meinem Handy direkt in meiner Cloud landen und nicht bei Google & Co. Ein Selbstläufer ist es aber in der Regel nicht, da eine bestimmte PHP-Konfiguration benötigt wird, und so einen Memory-Cache installiert man halt auch nicht jeden Tag. All das übernimmt die Installations-Routine von nextcloudPi. Entwickelt wird das von nachoparker:
Odroid XU4 anstatt Raspberry Pi
Der Raspberry Pi hatte sich überraschenderweise sehr gut geschlagen mit der nextcloud-Installation, besser als nextcloud auf der synology oder auf der QNAP. Der Raspberry 3 B+ hat nur einen großen Nachteil, USB (wo die Festplatte dran hängt) und Ethernet hängen am gleichen Bus, und da der Raspberry eh nur mit 100 MBit-Ethernet ausgestattet ist, wird das Schreiben und Lesen nicht gerade schneller, wenn die Festplatte da auch noch dran hängt. 1 GB Arbeitsspeicher ist auch nicht besonders viel.
Nach viel Recherche fiel meine Wahl auf den Odroid XU4 mit 2 GB RAM und 8 (!) Kernen, nachdem ich lange mit dem RockPro64 geliebäugelt hatte (4 GB RAM!). Der XU4 kostet um die 100€, mit Netzteil, Flashspeicher etc zahlt man etwas mehr als 120€. Bei dem RockPro64 gab es zu viele Foreneinträge, welches Betriebssystem welche Probleme macht.
Die Einkaufsliste
Wahrscheinlich kann man die Komponenten irgendwo günstiger kaufen, aber da es bei mir schnell gehen musste, habe ich die folgenden Komponenten genommen:
SanDisk SSD 1 TB für 129€ (Affiliate-Link); natürlich kann man auch eine bestehende Festplatte nehmen, dann bitte den passenden Adapter besorgen
Benötigt wird außerdem ein dynamischer DNS-Dienst, der bei wechselnder eigener IP-Adresse zuhause die Erreichbarkeit von außen unter der gleichen Subdomain ermöglicht; ich habe gute Erfahrungen mit no-ip.com gemacht.
In dem Odroid-Paket ist bereits ein MicroSD-Adapter für die eMMC-Karte enthalten, es wird dann noch ein Adapter für die MicroSD-Karte benötigt, um die eMMC-Karte flashen zu können. Den habe ich nicht in meiner Kostenübersicht einbezogen. Eine eMMC-Karte ist ein extrem schneller Speicher, Fingernagel-groß, der direkt auf den Single Board Computer gesteckt wird.
Die Installation
Zunächst muss das passende System von der nextcloudPi-Seite heruntergeladen werden. Ich wollte Armbian nehmen, da damit schließlich auch andere Sachen möglich gewesen wären, aber damit habe ich die SSD nicht am USB 3.0-Anschluss zum Laufen bekommen. Mit dem Image für das Odroid-Board war das kein Problem. Mit Etcher wird dieses Image dann auf die eMMC geflasht, das dauert ca. 5 Minuten. Und dann kann man die eMMC-Karte auf den Odroid stecken, Ethernet anschließen, den Strom einstöpseln und den kleinen Computer booten. Ich hatte auf das Anschließen eines Monitors verzichtet und einfach im Netz geschaut, welche IP-Adresse der Rechner bekommt. Übrigens keine so schlaue Idee von mir, denn irgendwann will man schon noch per SSH auf den Rechner zugreifen können.
Mit https://:4443/wizard kommt man auf die Installations-Oberfläche, die durch die Installation führt. Irgendwann wird man aufgefordert, sein USB-Laufwerk einzustöpseln, das dann automatisch gemountet und optional auch formatiert wird. Insgesamt ist man nach maximal 30 Minuten fertig, inklusive Auspacken und Zusammenstöpseln.
Die Geschwindigkeit ist der Hammer. Egal ob zuhause im Netzwerk oder draußen, das Ding ist schnell, gefühlt sogar schneller als Dropbox oder Google Drive. Aber was noch wichtiger ist, ich habe meine Daten zuhause (natürlich muss ich dann noch irgendwas aufsetzen, damit ich irgendwo ein verschlüsseltes Backup meiner privaten Cloud in der Cloud habe). Man kann sich natürlich fragen, ob Dropbox oder Google Drive dann nicht doch viel günstiger sind, wenn sie nur 10€ pro Monat für ein TeraByte kosten. Ich brauche mehr als 2 Jahre, um die Kosten reinzuholen. Aber, noch mal, ich habe meine Daten jetzt zuhause und nicht irgendwo. Und schneller ist es halt auch.
Die Konfiguration
Noch ein paar Worte zur Konfiguration. Natürlich aktiviert man 2-Faktor-Autorisierung. Außerdem würde ich dringend dazu raten, im nextcloudPi-Konfigurationspanel dnsmasq zu aktivieren und den DNS-Server des eigenen Rechners auf die IP des Odroid einzustellen. Dadurch können in den Logdateien die einzelnen Rechner im Netzwerk voneinander unterschieden werden.
Als Nutzer legt man für sich selbst einen Standard-Nutzer an, der nicht Admin ist.
Ich habe die Festplatte nicht verschlüsselt. Verschlüsselung drückt die Perfomance und benötigt auch mehr Plattenplatz, aber ich habe mir vor allem darum Sorgen gemacht, dass ich die Schlüssel verliere. Vielleicht hole ich das aber auch irgendwann noch mal nach. Nur geht das dann nur mit neuen Dateien, nicht mit einem bestehenden Set.
Übrigens, auch wenn die Zugangs-URL eine Domain ist, wird im eigenen Heimnetzwerk auch nur lokal kommuniziert. Es wird also nicht der Umweg über das Internet gegangen, auch wenn das vielleicht so aussieht.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Sascha says
Juli 2019 at 04:48 Klingt mega interessant, da mein RaspberryPi 3 echt suboptimal ist… hast du mal den Odroid N2 ausprobiert oder meinst du generell der lohnt sich? Wie genau muss ich das installieren? Also Armbian konntest du nicht nehmen, weil die SSD dann nicht geht? Lag es speziell an der SSD oder wird das allgemein so sein? Ich bin kein Profi und finde keine Anleitung. Welches Image genau von wo muss nun geflasht werden? https://ownyourbits.com/nextcloudpi/#download ich weiß, dass hier alles erhältlich ist und würde eigentlich gerne Docker benutzen und wenn das geht dazu PiHole eben. Das scheint generell alles etwas komplizierter zu sein als beim RaspberryPi. Ich wüsste nicht mal gerade wie man SSH einschaltet. Aber ist ja alles eine einmalige Sache. Kannst du mir da Auskunft geben? Vielen Dank und lieben Gruß!
Tom Alby says
Juli 2019 at 12:09 Soweit ich das sehen kann wird der N2 noch nicht unterstützt. Vielleicht gehst Du mal in die Telegram-Gruppe des Entwicklers und fragst dort nach. Im Prinzip wäre der neue Raspberry 4 ja auch ein guter Kandidat mit seinen 4 GB RAM. Aber auch da sehe ich noch keine Unterstützung.
Ich habe nicht genug Zeit mit der Fehlersuche des USB-Ports und der SSD verbracht. Meine Erfahrung ist, dass man mit sowas unglaublich viel Zeit verbraten kann, und genau das wollte ich eben nicht mehr tun. Flashen tust Du normalerweise ein Image auf eine SD-Karte o.ä., von der Du booten willst. Wegen Docker: https://hub.docker.com/r/ownyourbits/nextcloudpi-armhf
Sascha says
Juli 2019 at 17:33 Hey Tom, danke dir für deine Antwort. Ich befinde mich bereits in der Telegram Gruppe zu NextCloudPi. Habe mir jetzt den N2 bestellt. Das Problem bei dem Gerät ist, das kein offizielles Armbian existiert (jedenfalls momentan) und man NCP nur über Docker installieren kann und damit auf das BTRFS Feature verzichten muss. Für den Raspberry Pi 4 existiert seit gestern ein Image. Ich werde nun eine eMMC mit vorgefertigtem Linux erhalten und muss doch deshalb wahrscheinlich gar nichts flashen oder sehe ich das falsch? Nach dem NCP Entwickler gibt es keinen logischen Grund an einem Raspberry Pi festzuhalten, da er eben in allen Ebenen unterlegen ist. Meinst du denn, dass es sinnvoll ist eine SSD somit quasi als NAS zu nutzen? Habe gerade meine Zweifel daran. Klar ist der Speed super, aber nicht dass die Daten von heut‘ auf morgen weg sind. Naja mal schauen dann. Denke aber der N2 wird gut laufen.
Tom Alby says
Juli 2019 at 11:43 Egal ob SSD oder HDD, eine Platte kann immer kaputt gehen. Entweder RAID oder täglich Snapshots woanders sichern. Ich gehe sogar so weit, dass ich verschlüsselte Snapshots in der Cloud sicher.
Lutz says
August 2019 at 15:48 Hallo Herr Alby, danke für die Publikation Ihrer Erfahrungen und sicherlich haben Sie sehr profundes IT-Wissen, jedenfalls mehr als ich. Dennoch: ich denke (bis jetzt) dass, wenn man die Capex nicht als limitierenden Faktor alleine setzt, gibt es vermutlich auch leistungsfähige NAS bei z.B. Synology. Laut deren White-Papers (habe ich nch nicht proboert, da ich dafür sicher mehr Zeit investieren muss als Sie) müsste eine Art Ende zu Ende Verschlüsselung beim Upload in die Cloud nutzbar sein. Ich habe mir meinen Router „dicht“ gemacht und keine weiteren offenen Ports offen (z.B. 5000 und 5001 usw.) statt dessen gehe ich via IPSEC IKVE2 auf den Router von außen, das sollte m.E. auch soweit sicher sein. Meine Bauchgrummel-Gefühle kommen von hier: 1.) Ich kenne keine ernst zu nehmende externe Cloud die via VPN ansprechbar ist. Nur prperitäre Lösungen mit Ende zu ende Ecryption und die lassen sich z.B. meines Wissens nicht mit einer Synology verbinden. Also wird das nichts richtiges. 2.) Wie kann man rausbekommen, ob es in der Synology-Welt der Encryption-Lösung eine Backdor gibt? Frage: M.E. müsste es sicher genug sein (100% ist wohl illosorisch, aber wenn sich Geheimdienste für einen mit ihren Budgets interessieren darf man sich wohl „von“ schreiben oder hat was falsch gemacht) Wenn z.B. keine Back-Door vorhanden ist und die Pre-Encryptete Datei via SSL auf z.B. Onedrive von MS abgelegt ist, oder Google Drive o.ä.
Tom Alby says
August 2019 at 19:04 Sicherlich gibt es für mehr Geld leistungsfähigere Hardware, sowohl von QNAP als auch von Synology. Für mich zeigt das NextCloudPi-Projekt aber, dass man mit wenig Aufwand und wenig Geld eine hochperformante Lösung erhält, die auch noch als Open Source verfügbar ist (und da können Sie ja nachprüfen, ob es eine Backdoor gibt). Und jetzt mit dem Raspberry Pi 4…
Auch brauche ich ja kein VPN zu einer externen Cloud, wenn ich meine Sachen da schon verschlüsselt ablege…?
Jan says
August 2019 at 09:23 Hallo Tom,
habe soeben zwei deiner Berichte gelesen, da ich mich die Tage ebenfalls mit einer eigenen Cloud beschäftigt habe.
Die Entscheidung viel bei mir zuletzt auf einen Ordoird HC1, fürs OS habe ich eine Standard MircroSD mit V30 Standard verwendet. Die HC1 / HC2 verwenden angeblich ebenfalls die XU Hardware in einer für NAS/Cloud reduzierten Variante.
Die Installation wurde bei mir über Ubuntu 18.04 von Hand aufgesetzt was mich in Summe inkl. Trial-Error Szenarien zwei Tage gekostet hat. Daher klingt es für mich sehr interessant dass es bei Dir innerhalb 30 Minuten mit dem NextcloudPi Image so reibungslos funktioniert hat. Das muss ich dann in kürze noch im zweiten Bastelprojekt verwenden. Mein nächstes Ziel wäre eine Nextcloudlösung inkl. Backup / RAID, mal schauen was dabei rauskommt.
Beste Grüße, Jan
Markus G. says
September 2019 at 21:16 Hallo Tom,
kannst Du uns schon etwas sagen, wie die Performance und Stabilität Deiner Home NAS läuft, bist Du bisher zufrieden oder gab es irgendwelche Probleme im Laufe der Betriebszeit?
Würde gerne so ein Projekt in Angriff nehmen.
Danke und viele Grüße Markus
Tom Alby says
September 2019 at 21:21 Ich bin superglücklich mit der Lösung. Zwischendurch gab es mal ein Problem mit dem Let’s encrypt-Zertifikat, aber auch das hab ich irgendwie gelöst bekommen.
Christian says
Oktober 2019 at 00:01 Hallo Tom, Würden sie empfehlen auf den Rasperry Pi 4 zu setzen, oder lohnt sich der Mehrpreis mit dem Odroid XU4-Set? Ich bin jetzt in dem Thema Einplatinen-Rechner nicht so bewandert und hatte mich nur gefragt ob die 4 GB Ram einen Vorteil bieten. Bei so einer Investition zahle ich aber lieber etwas mehr, wenn es sich lohnt von der Performance. Nutzen sie die Nextcloud App auf ihren mobilen Geräten auch unterwegs?
Tom Alby says
Oktober 2019 at 09:09 Gute Frage. Ich hab den neuen Raspberry noch nicht ausprobiert und kenne auch keinen Benchmark. Ja, ich nutze die Mobile Apps dazu.
Maik says
Oktober 2019 at 15:41 Hallo Tom, leider habe ich deine Beiträge zum Thema einer eigenen Cloud gerade erst jetzt gefunden. Ich habe mich in den letzten Tagen erheblich mit Owncloud und QNAP abgemüht. Alles, was da im Original angeboten wird, ist leider nicht mehr up-to-date. Allerdings würde auch mein NAS (TS-221) sicher als akzeptable Hardware ausscheiden. Nun bin ich am Nachdenken, Folgendes zu realisieren: Ich habe hier noch 2 Pi 3B+ rumliegen, die ich für nichts nutze. Ich würde gern auf einem von denen die NextCloudPi realisieren, den Speicher für die Dateien allerdings auf mein NAS legen (irgendwie mounten), da dort noch soooo viel Platz ist. Geht das denn auch irgendwie? (Man hört vielleicht, dass ich nicht so der Linux/Unix-Crack bin)
Oktober 2019 at 23:43 Hallo Tom, Ich habe mir auf einem Odroid N2 mit Debian buster Nextcloud eingerichtet. Die Daten werden auf zwei 1TB SSDs im Raid 1 gespeichert. Hast du auch Probleme mit Dateien mit deutschen Umlauten? Ich wollte gerade meine PDFs aus dem Studium hochladen aber habe einige Dateien die Probleme machen. Ich habe einiges gelernt bei diesem Projekt. Danke für die Empfehlung. viele Grüße Christian
Tom Alby says
Oktober 2019 at 09:08 Hey Christian,
nein, keine Probleme mit Umlauten. Ich hoffe, Du bekommst das Problem gelöst.
Beste Grüße
Tom
Nico says
November 2019 at 17:46 Hi Tom,
Danke für Deinen Beitrag, das klingt ganz nach etwas, das ich schon lange gesucht habe Darf ich nachfragen, welche Bandbreite Dein Upload für das von dir oben beschriebene System hat? Dass Du schreibst, gleich schnell/schneller als GDrive ist ja schon eine Aussage, da wollte ich nur mal nachfragen, ob du als IT Spezialist auf einer Gigabit Leitung sitzt
Gerhard Treisbach says
November 2019 at 12:55 Hallo Tom,
nachdem ich Deinen Artikel gefunden habe, habe ich mir die von Dir empfohlene Hardware (ODROID-XU4) über Deine Links bestellt.
Mit einem Original Ubuntu MATE Image von odroid.com bekomme ich das Teil auch problemlos zum Laufen, aber sowie ich versuche, das Image von deinem Link (NextCloudPi_OdroidHC2_08-01-19 ) zu installieren, bleibt der ODROID beim Booten einfach stehen. Keine Bildschirmausgabe und auch keine zugewiesene IP Adresse.
Kannst Du noch irgendwie rausfinden, welche Version das NextCloudPI Image hatte, dass Du damals verwendest hast und mit dem alles auf Anhieb lief?
Liebe Grüße Gerhard
Chillbird says
November 2019 at 16:02 Hallo Tom,
super Artikel und die Zeit die du damit „verschwendet“ hast, koennen sich Leser wie ich dann dafuer ersparen. Vielen Dank! Ich wuerde mich sehr ueber ein Update freuen, vorallem wenn Du die automatisierte E2EE Backupfunktion in die Cloud realisiert hast. Um das System perfekt zu machen, koennte man statt der einzelnen Platte dann auch einen Hardware RAID Array dranhaengen (zb den um 100 Euro: FANTEC QB-35US3-6G), vielleicht gibt es sogar Hardware Encryption+RAID Loesungen?
Hast du sowas wie einen Newsletter? Wenn ja, melde ich mich hiermit an
Danke und alles Gute weiterhin, Chillbird
Gabi says
Januar 2020 at 04:00 „Übrigens, auch wenn die Zugangs-URL eine Domain ist, wird im eigenen Heimnetzwerk auch nur lokal kommuniziert. Es wird also nicht der Umweg über das Internet gegangen, auch wenn das vielleicht so aussieht.“
Wie machst du das? Ich versuche dasselbe, aber bei mir stellt sich die Fritzbox quer…
Mirko says
Januar 2020 at 16:16 Hallo Tom,
es gibt eventuell ein Problem mit Boards der Revision 0.1 20180912 . Die Teile booten nicht mit dem aktuellen NextCloudPi Image vom Januar 2020. Gerhard Treisbach hatte das gleiche Problem. Ich habe versucht Armbian zu installieren, habe aber das gleiche Problem. Ubuntu Mate läuft problemlos.
Viele Grüße
Mirko
Tobias says
Januar 2020 at 08:43 Hallo Mirko,
mit welcher Revision läuft dann Nextcloudpi image. Mit den älterenen oder den neueren. Würde mich interessieren, da ich mir auch gerade ein NAS aufbauen möchte.
Gruß Tobias
Gerhard Treisbach says
Januar 2020 at 16:49 Hallo, hier noch mal Gerhard,
ich habe das Problem mit dem nicht bootenden XU-4 gelöst bekommen, hier mal der Link zu dem entsprechenden Thread im NextcloudPi Support Forum:
Jeder will Data Scientists haben. Hochschulen bieten Studiengänge an. Coursera & Co überschlagen sich mit Data Science-Angeboten. Angeblich kann man Data Science in einem Monat lernen. Und das ist wichtig! Denn Daten sind das neue Öl. Ohne Daten und die sie zu Gold machenden Data Scientists sei die Zukunft düster, da sind sich alle einig. Selbst wenn man keine spannenden Daten hat, so kann ein Data Scientist vielleicht aus dem Wenigen schon Goldstaub zaubern. Und eigentlich hat man eh keine Ahnung, was man mit den Daten machen kann, aber wenn man erst mal Data Scientists hat, dann wird alles gut. Auf dem Hype Cycle sind wir immer noch nicht ganz oben angekommen, aber es wird nicht mehr lange dauern, bis es runter geht ins Tal der Ernüchterung (und dann zum Plateau der Produktivität). Schuld daran haben mehrere Missverständnisse.
Es gibt keine allgemeingültige Definition von Data Science
Somit kann sich jeder Data Scientist nennen, wer das gerne möchte. Und man kann auch einen Kurs oder einen Studiengang danach betiteln, weil es gerade schick ist. Genau das passiert momentan zu häufig.
Data Science ist das Zusammenspiel aus Data Mining, Statistik und Machine Learning. Und genau das biete ich in meinen Kursen an. Und damit wir uns gleich richtig verstehen: Ein Semester ist dafür viel zu wenig. Und deshalb nennen wir das auch nicht mal Data Science, sondern Data Analytics oder Ähnliches. Wir schnuppern rein in Data Science. Aber in den 60 Stunden im Semester entwickle ich keinen neuen Data Scientist.
Im Prinzip müsste man erst einmal mindestens ein Semester Statistik unterrichten, bevor es weiter geht. Dann eine Programmiersprache richtig lernen, sei es R oder Python. Und dann würde man mit Machine Learning beginnen. Dazwischen immer mal wieder erklären, wie man mit Linux/Unix umgeht. Datenbanken. Cloud-Technologie. Damit kann man sicherlich ein ganzes Studium füllen.
Oft ist es aber nur eine Einführung in Python mit etwas scikit. Aber, wie oben schon beschrieben, das ist egal, denn der Begriff ist eh nicht geschützt. Und es merkt auch kaum jemand, denn wer soll das denn beurteilen?
Es gibt noch keine ausreichende Ausbildung
Vor kurzem habe ich mal in einen Data Science-Kurs auf Udemy reingeschnuppert (der übrigens immer nur noch wenige Stunden gerade mal ein paar Euro kostet). Der junge Mann in seinem Gamer-Stuhl konnte gut reden, aber in die Tiefe konnte er nicht gehen. Wobei, es kommt darauf an, wie man Tiefe definiert. Der inhaltliche Tiefpunkt war für mich erreicht, als er sagte, dass man gewisse Dinge mathematisch nicht verstehen muss, zum Beispiel ob man durch n oder durch n-1 teilt. Wow.
Dann habe ich auch schon mehrere Informatik- o.ä. Studierende von der Uni Hamburg etc bei mir gehabt. Abgesehen davon, dass ihnen grundlegende Kenntnisse fehlen (“Was ist eine CSV-Datei?”), haben sie zwar ein paar Techniken gelernt, die sie auch brav in die Bewerbung schreiben (“Erfahrung in ML”), aber richtig verstanden haben sie nicht, was sie da tun. So wird k-means gerne auf alles geballert, auch wenn es keine numerischen Daten sind (die kann man ja einfach umwandeln, dann sind sie ja numerisch). Dass das selten Sinn ergibt, wenn man euklidische Distanzen berechnet, nun ja. Wenn man nur einen Hammer hat, dann sieht alles aus wie ein Nagel.
Wenn aber die Ausbildung suboptimal ist, wie sollen die Data Scientists dann Gold aus Daten generieren? Für den wirklich krassen Kram wird eine solche Ausbildung nicht ausreichen. Und entweder wird dann Mist geliefert oder das Projekt geht nie zu Ende. Das erinnert mich ein bisschen an die New Economy, als plötzlich jeder HTML-Seiten bauen konnte. Nur diejenigen, die mehr als HTML konnten, haben nach dem Crash noch Chancen auf einen Job gehabt. Und zu viele Läden gingen pleite, weil sie einfach nur schwach ausgebildete Leute eingestellt hatten.
Nicht jedes Problem benötigt einen Data Scientist
Viele Probleme lassen sich auch ohne einen Data Scientist lösen. Tatsächlich sind viele Methoden bereits in der Statistik gut behandelt worden, von der Regressionsanalyse bis zur Bayesian Inferenz. Auch Klassifikation und Clustering gab es lange vor dem Data Science-Zeitalter. Support Vector Machines sind auch schon etwas älter (60er Jahre!). Das einzig Neue ist, dass es viel mehr Bibliotheken gibt, die jeder anwenden kann. Aber man muss nicht sofort an Data Science denken, wenn es um diese Themen geht. Denn da zahlt man gleich einen Hype-Bonus mit.
Und vor der Anwendung solcher Methoden steht erst einmal die Analyse von Daten. Dies ist die Kompetenz, die am meisten fehlt. Wir brauchen zunächst einmal nicht mehr Data Scientists, wir brauchen mehr Menschen, die nicht vor einer Zahlenkolonne weglaufen und es schaffen, daraus die richtigen Schlussfolgerungen zu ziehen. Und wenn man dann nicht weiß, wie man auf eine Lösung kommt, dann kann man immer noch einen Spezialisten fragen. Die häufigsten Probleme, die ich sehe, sind keine Data Science-Probleme, es sind zunächst einmal Daten-Analyse-Aufgaben. Und idealerweise werden diese Aufgaben nicht von Extra-Datenanalysten durchgeführt, sondern von den Kollegen selbst, die die Experten in einem Thema sind.
Was, wenn nicht Data Science, wird wichtig?
Natürlich wird die Arbeit mit Daten in Zukunft nicht weniger wichtig werden. Ganz im Gegenteil. Aber es ist zu befürchten, dass der gegenwärtige Hype diesem neuen Gewächs nicht gut tut. Da es dort jede Menge Geld zu verdienen gibt, stürzen sich auch Talente darauf, deren bisheriger Fokus nicht unbedingt auf Mathematik-nahen Fächern lag. Einen Udemy-Kurs kann jeder irgendwie abschließen. Aber die Qualität ist nicht bei jedem Kurs gleich gut. Und dementsprechend ist diese Art der Ausbildung sowie auch das plumpe Lernen von Methoden an der Uni nicht hilfreich, Data Science nach vorne zu treiben. Dadurch wird Data Science eher enttäuschen und in das Tal der Enttäuschung abrutschen. Denn es werden nicht alle Erwartungen erfüllt werden können.
Die Arbeit mit Daten sollte im Vordergrund stehen, nicht Data Science. Die Analyse. Die Akquise. Data Scientists sind gelangweilt, wenn sie nur als besser bezahlte Datenanalysten verwendet werden. Und der Anwender, der seine Bedürfnisse und Probleme gar nicht artikulieren kann (sofern überhaupt ein Problem vorhanden ist und nicht einfach nur nach dem “geilen Scheiß” gefragt wird), versteht die Welt nicht mehr, wenn die Data Scientists dann wieder gehen und sich eine spannendere Aufgabe suchen. Wir brauchen Anwender und Data Scientists, die zunächst einmal das zu lösende Problem verstehen und auch die entsprechenden Daten analysiert haben. Wir müssen mehr Menschen die Kompetenz geben, Daten selber analysieren zu können.
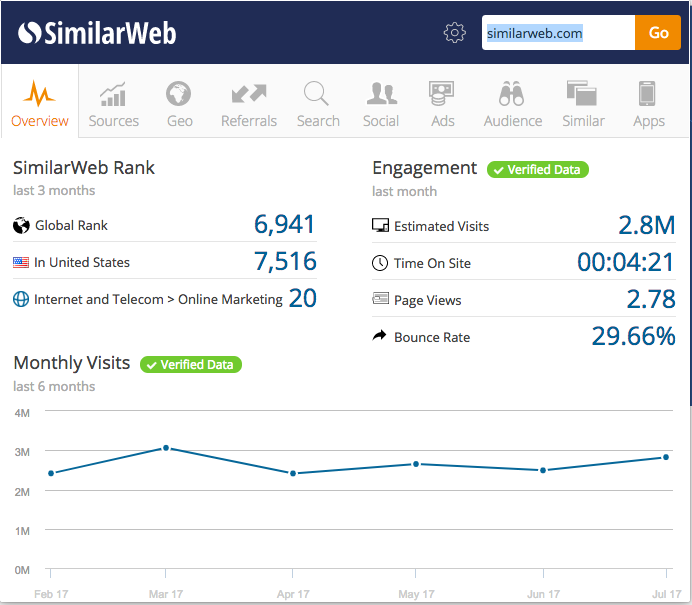
As with Google Trends, I’m always surprised at how quickly conclusions can be drawn from data without having to think about where the data actually comes from and how plausible it is. Especially with Similar Web, this is amazing, because Google has the search data and can read trends from it, but how can Similar Web have data about how many visitors a website or app has? How reliable is this data? Is the reliability sufficient to make important business decisions?
The ancestor of SimilarWeb
In 2006, my former colleague Matt Cutts had once investigated how reliable Alexa’s data is (Alexa used to be an Amazon service that had nothing to do with speech recognition). This service collected data with a browser toolbar (there’s no such thing anymore), i.e. every page a user looked at was logged. Since Alexa was especially interesting for webmasters, pages that are interesting for webmasters were logged. So they were distorted. So if you are already recording the traffic of users, then you have to somehow make sure that the user base somehow corresponds to the network population you want to find out about. That doesn’t mean that the data is completely worthless. If you compare two fashion sites with each other, then they are probably “uninteresting” for the webmaster population (a prejudice, I know), and then you could at least compare them with each other. But you couldn’t compare a fashion page with a webmaster tool page.
But where does Similar Web get the data from? On their website they give 4 sources:
An international panel
crawling
ISP data
direct measurements
Data collection via a panel
The panel is not explained in detail, but if you do only minimal research, you will quickly find browser extensions. These are probably the successors of the earlier browser toolbars. What is the advantage of the Similar Web Extension? It offers exactly what Similar Web offers: You can see with one click how many users the currently viewed page has, where they come from, and so on. The Similar Web-Extension does not only work at home if you are currently viewing the data for a page, but for every page you are viewing.
If you consider for whom such data is interesting and who then installs such an extension, then we have arrived at the data quality of the Alexa Top Sites. Webmasters, marketing people, search engine optimizers, all these people have a higher probability to install this extension than for example a teenager or my mother.
Crawling
What exactly Similar Web crawls is still a mystery to me, especially why a crawling can give information about how much traffic a page has. Strictly speaking, you only cause traffic with a crawler Similar Web says, “[we] scan every public website to create a highly accurate map of the digital world”. Probably links will be read here, maybe topics will be recognized automatically.
ISP traffic
Unfortunately, Similar Web does not say which ISPs they get traffic data from. It’s probably forbidden in Germany, but in some countries it will certainly be allowed for an Internet service provider to have Similar Web’s colleagues record all the traffic they receive through their cables. That would of course be a very good database. But not every ISP is the same. Would we trust the data if, for example, AOL users were in it (do they still exist at all)?
Direct measurements
This is where it gets exciting, because companies can link their web analytics data, in this case Google Analytics, directly to Similar Web, so that the data measured by Google Analytics is available to all Similar Web users. Then the site says “verified”. Why should you do that? You don’t get anything for it, instead you can expect more advertising revenue or strengthen your brand. Quite weak arguments, I think, but there are still some sites that do.
How reliable is Similar Web data really?
Of course, the direct measurements are reliable. It becomes difficult with all other data sources. These make up the majority of the measurements. Only a fraction of the Similar Web data is based on my sample of direct measurement data. But here you could certainly create models based on the accurately measured data and the inaccurately measured data. If I know how the data from spiegel.de is accurate and what the inaccurately measured data looks like, then I could, for example, calculate the panel bias and compensate for other pages. And I could do the same with all other data.
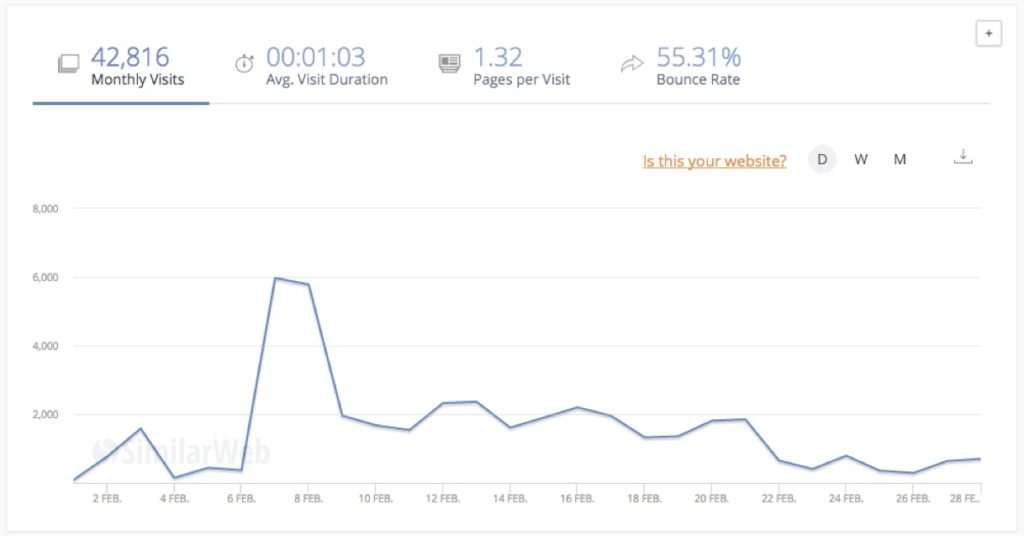
But does it really work? Let’s take a look at a measurement of Similar Web for one of my pages:
Apparently the number of visitors fluctuates between as good as nothing and 6,000 users. There are no clear patterns. And now we look at the real numbers from Google Analytics:
It’s the same time period. And yet the unique traffic patterns from the Google Analytics data are not recognizable in the Similar Web data. The data is simply wrong.
Result
Can you use Similar Web at all? I would advise you to be very careful if the data does not come from a direct measurement. Of course, the question can now arise as to what else to use. The counter-question is what to do with data that you can’t be sure is correct at all. If I had to make a business decision that might cost a lot of money, I wouldn’t rely on that data. For a first glance…? We also know that a “first glance” can quickly become a “fact” because it fits so well into one’s own argumentation.
Of course this is an unsatisfactory situation. No wonder that alternatives like keywordtool.io are popular. But how accurate is their data? Because I couldn’t find a clue where they got the data from, and that makes me very suspicious at first. Where would they get the data from, if not via the API? And here the access is limited. On the initiative of my esteemed colleague Christian, I then took a closer look at it. On the one hand he asked where keywordtool.io got the data from (there was no satisfactory answer). On the other hand he got a test account A first pre-test brought disappointing results, the numbers were completely different than those of AdWords. However, the colleague was no longer sure if he had chosen the same settings as I did in AdWords, so I did the test again on my own.
With the first keyword set from the pedagogy area, the surprise after the pre-test was big: Apart from a few exceptions, all keywords had exactly the same search volume. The few exceptions were that keywordtool.io did not spit out any numbers, but the keyword planner did. Here, however, there were only 2 out of almost 600 keywords. The second keyword set on the subject of acne also showed the same picture. The search volumes fit exactly except for a few exceptions. Interestingly, both keyword sets were more concerned with topics that did not necessarily stand out due to their high search volume, in some cases we are talking about 20 search queries per month. So it is very likely that the Google AdWords API will be tapped directly here, otherwise these exact numbers cannot be explained. This would also explain why you can only query 10 sets of a maximum of 700 keywords (more than 700 keywords are not possible with the Keyword Planner, but more than 10 per day). Thus keywordtool.io would be a good alternative… if not…
The third keyword set then showed a different picture, the deviations are dramatic. Unlike the previous keywords we are talking about high volume keywords like . Unfortunately there is no pattern to be seen on the plot, except for the pattern that keywordtool.io is always higher and never lower. Keywords with a high search volume can be as well off as keywords with a low search volume. It’s also not that it’s always the same deviation, we’re talking about keywords where the numbers fit exactly, and keywords that have a deviation of 16 times the volume reported by Google. There is also no order in any way. The deviations are completely random. And they’re far too big to ignore.
Of course, that won’t stop many people from using keywordtool.io, after all, people like to say “Joa, usually fits” or “It’s better than nothing”. Whether it’s really better, I question that. I wouldn’t want to make any decisions on the basis of such deviations. The keyword planner is the better option, even if it only delivers staggered values, if you don’t have enough budget.
By the way, the data of the third set are available here in an R notebook.
[Please note that this article was originally written in German in 2016; all screenshots are in German but you will understand them nevertheless. The text has been translated automatically so please excuse the English]
In September 2015, I stood on a big Google stage in Berlin and showed the advantages of the new features of Google Trends in addition to a demo of voice search. For a data lover like me, Google Trends is a fascinating tool if you understand all the pitfalls and know how to avoid them. At the same time the tool offers a lot of potential for misunderstandings Search queries are placed in <> brackets.
Misunderstanding: Not all search queries are considered.
Misunderstanding: The lines say nothing about the search volume / No absolute numbers.
Misunderstanding: Google trends search queries are different
Misunderstanding: Rising lines no longer mean search queries.
Misunderstanding: Without a benchmark, Google Trends is worthless.
1st Misunderstanding: The basis of Google Trends Data
Google Trends is not based on all the searches you enter on Google. Quote: “The Google Trends data is a random selection of data from Google searches. Only a certain percentage of the searches are used to determine the trend data. […] Trends only analyzes data for popular keywords. Low-volume search terms therefore appear as 0. […] Trends removes repeated searches from the same person within a short period of time.” There is no definition of when a term is popular or what a short period is. It is not said whether the random selection is a representative sample of the total population of all search queries (the term “random” suggests this). The first finding is that we are talking about trends, no more and no less.
2nd Misunderstanding: Graphs and search volumes in Google Trends
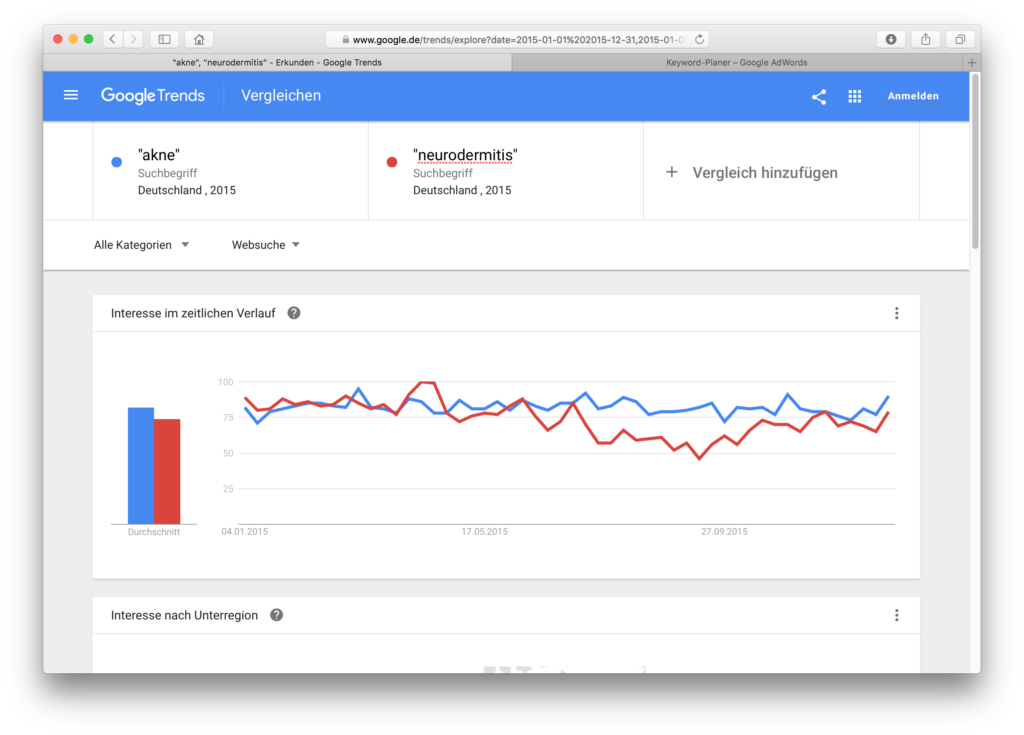
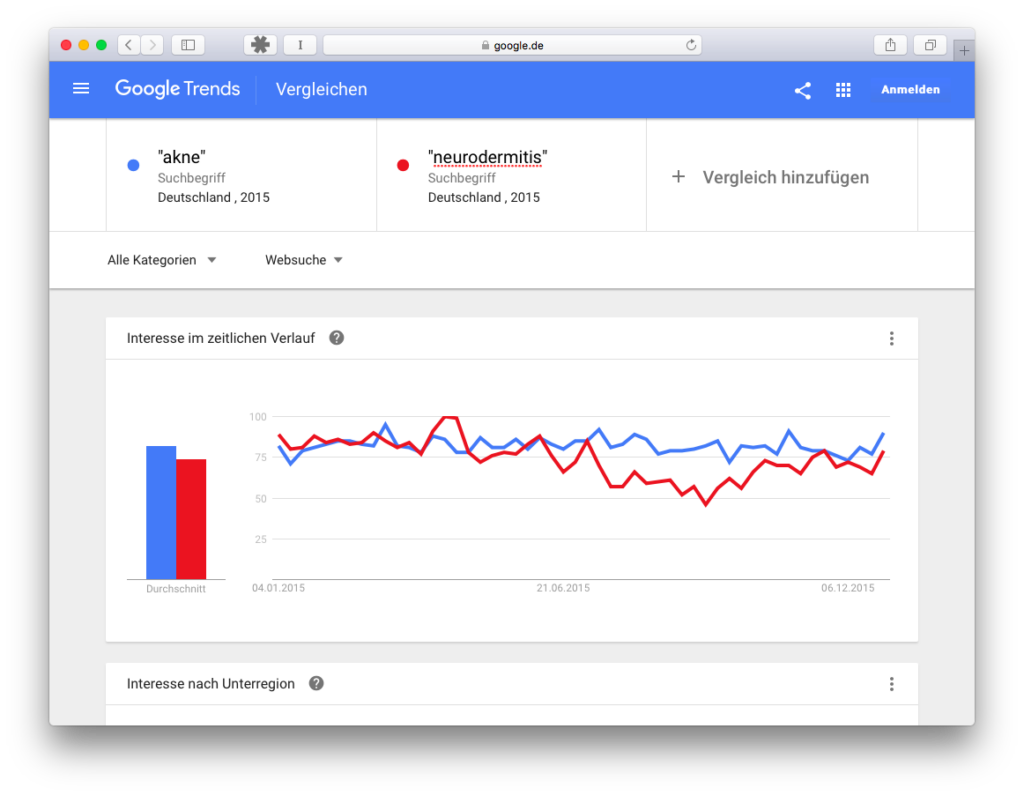
This is the biggest and most fatal misunderstanding. If one curve is above the other, it does not mean that one term was searched for more often than the other. Whaaaaat? Really? Yes. Fancy an example? We are looking for acne and neurodermatitis (I’ll explain below why I write this in quotation marks in the mask) for Germany in 2015. Acne and neurodermatitis alternate in search interest, but acne seems to have a higher search interest more often:
And then I take a look at the data in the Google AdWords Keyword Planner, for the same period, for the same country:
What is interesting here is not the graphic (I only made the screenshot to show that I am searching in the same country for the same period), but the two lines below, where we see the average search volume per month. Neurodermatitis is far above acne, 74,000 to 18,100.
Average values can lead us in the wrong direction, so we also look at the data plotted for each month:
We see a similarity to the Google Trends graphic, namely that the searches for neurodermatitis go down from May or the middle of the year and up again from September. And, this will become important later on, neurodermatitis will reach 100 on Google Trends, but acne never reaches this point. Otherwise the curves of the AdWords data do not touch each other once like in Google Trends. They are far apart. The second finding is that we can’t use Google Trends data to claim that one term is searched for more often than another (although Google Trends is often misused for this purpose). Google Trends does not provide absolute figures. Sorry. But why not? Let’s move on to the next misunderstanding.
3. Misunderstanding: What is a search query?
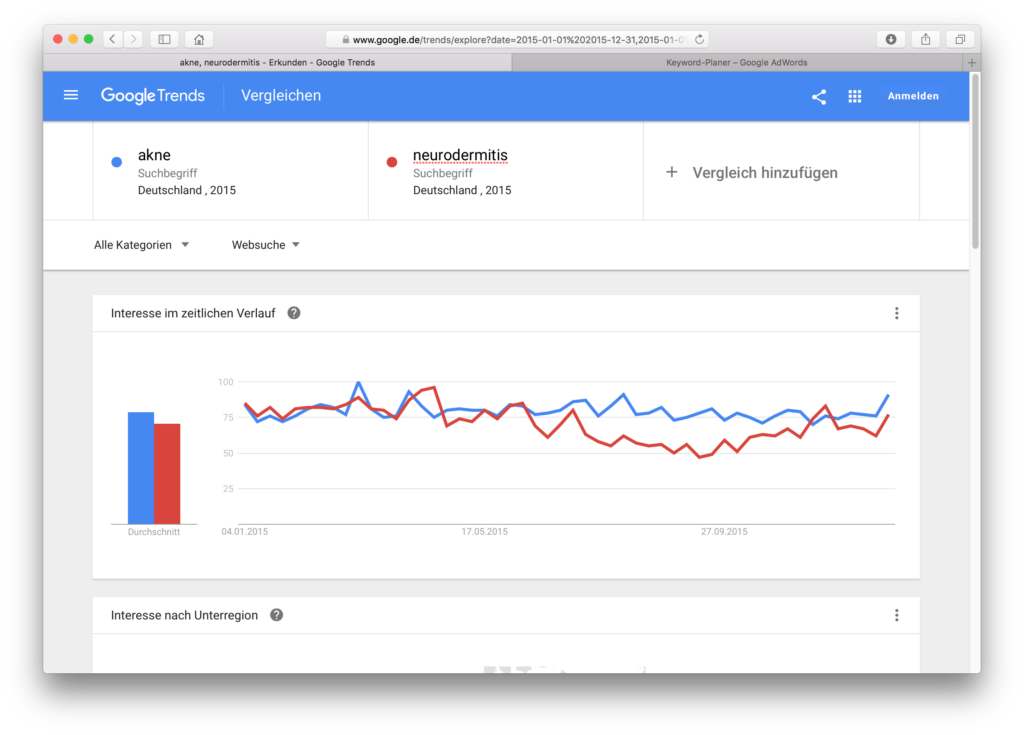
If you enter in Google or in the Google AdWords Keyword Planner, you will only search for this term. If you enter in Google Trends, you will automatically search for other terms, even if you have not selected a topic, but only this search term (see the help section of Google Trends). So you can restrict something by putting a term in quotation marks (“acne creme”), but this only restricts that is not searched for, but could be included. Which search terms are included, is not disclosed. An “exact match” does not exist, see the help section again.
In this example, we compare the search terms and . If we add quotation marks, the curves look a bit different:
Not a huge change, but there’s a difference we’ll remember for later: If we enter the terms without quotation marks, then comes close to 100, with quotation marks comes close to 100.
It is astonishing, because with a one-word term, where no synonyms are searched for, there can be no different order for the words in the search query. I can’t explain this phenomenon.
Finally, let’s look at what happens when we select the automatically identified topic “disease” (Note: Google turns automatically , which is the medical term for neurodermatitis):
Here, the trend data of terms that fit into the group of the disease are aggregated. The “search interest” in neurodermatitis approaches the topic of acne in February 2016, but acne as a topic seems to have a greater search interest than neurodermatitis. Again, we do not know which terms are grouped together. So it could be that the different data comes from the fact that Google Trends includes additional terms for both terms, but for the term acne terms whose search interest is different and therefore changes the result. However, this does not sound very plausible. Third finding: Google trend data is not comparable with AdWords data, because the input is interpreted and enriched differently and we at Google Trends do not know with what.
However, the differences between AdWords and trends are probably still not explained. What could be other reasons?
4th Misunderstanding: Everything that rises or falls is a trend in Google Trends
Now it’s getting a little mathematical. Google Trends does not offer absolute numbers, all data is displayed on a scale from 0 to 100. And now we remember the two clues above again when one of the two query curves touched 100. Touching the 100 has great significance, because from this highest point of search interest, everything else is calculated!
But it becomes even more complicated: First of all, the search interest is the search volume for a term divided by the search volume of all terms. Since we do not know the base (i.e. how many searches there were in total on that day) and this base changes every day, it is possible that the line of search interest for a term changes, although this term is searched for equally often every day. The point in time at which the maximum of this ratio search term/all search terms is reached becomes the maximum, i.e. 100 in the Google Trends diagram, and all other values, including those of comparison terms, are derived normalized from it. And only for the selected period. If this is changed, the maximum will also be recalculated. This leads to differences that could tempt you to choose exactly the period that matches what you would like to sell Examples:
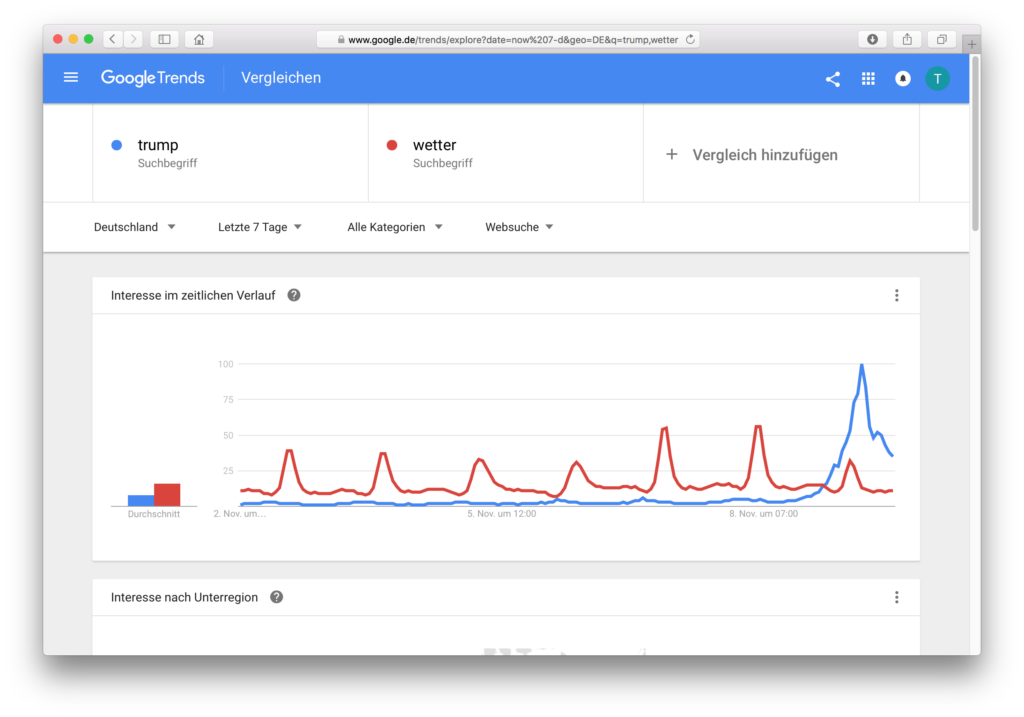
Misinterpretation: Compared to the weather, interest in Trump has hardly increased in the last 12 months
Misinterpretation: In the last 30 days interest in Trump has not increased as much as interest in weather. In fact, the data from Google Trends are not yet updated, the election day and the previous day are missing.
The diagram for the last 7 days: Can we now say that Trump was searched for more often than the weather?
These last graphics are very nice because they clearly show that the Germans didn’t necessarily search less for the weather, but the search queries for the term Trump on 9.11 had a much higher share in the population of all searches compared to the 6 days before. From this one maximum everything else is calculated. But over 30 days the weather had a maximum (EDIT: Because the day after the election was not yet there and it is also two days later not! Thanks to Jean-Luc for this hint!), and then it will be calculated from there. That’s why these dates can differ so much.
Edit: If you look one day after the election and only look at the last day (i.e. data that is about 10 minutes old), then the result looks like this:
Again the weather is higher, although Trump gets close. Is it? Well, I took this screenshot in the evening, and the peak of Trump searches probably took place more than 24 hours ago. It is very likely that I would have got another image if I had made the same query this morning.
What do we take out of this misunderstanding? 1. the period of observation is immensely important, and you shouldn’t believe a trend graphic without looking at several periods of time 2. all observations start from the maximum and are then relatively visible from this maximum, but are at the same time dependent on the total volume of all search queries, which we do not know. 3. it may not be so obvious in the graphs, but in the 7-day graph it is calculated on an hourly basis, in the 30-day graph on a daily basis, in the 12-month graph on a weekly basis. The Google AdWords Keyword Planner delivers data on a monthly basis. This is another reason why the data is not comparable.
EDIT: 4th Learning: “The last 30 days” does not necessarily mean that the last 30 days are really in
5th Misunderstanding: Everything that rises or falls is a trend in Google Trends, Part 2
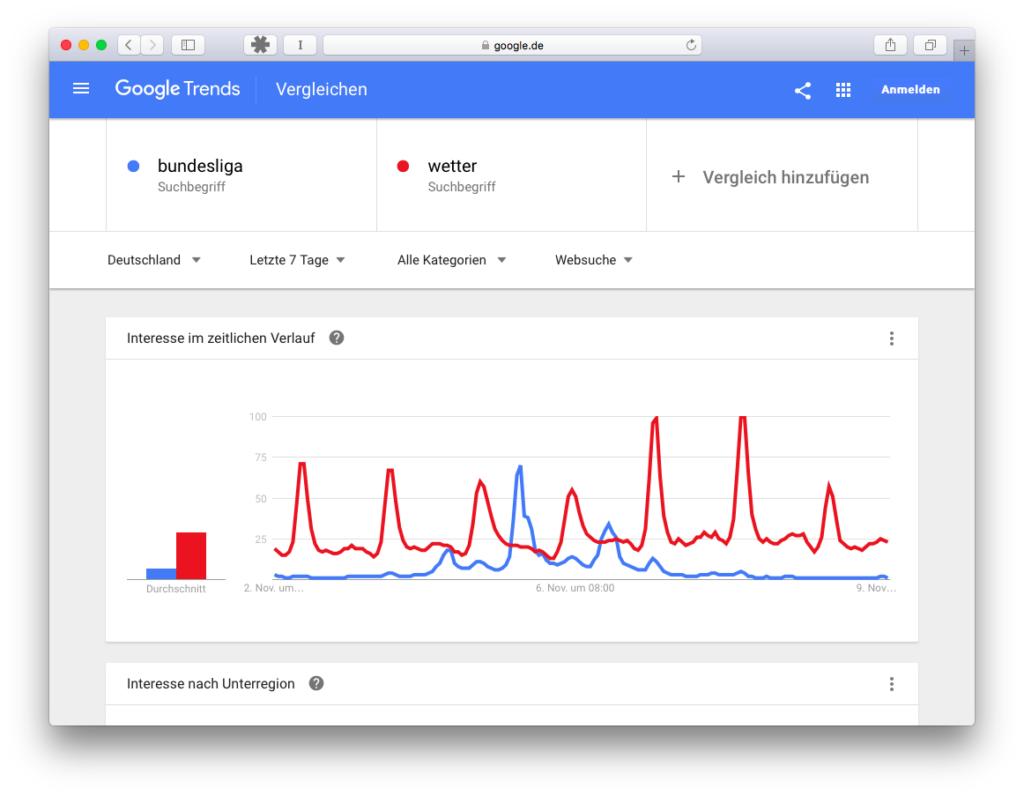
Depends on how you define trend. After the Brexit vote, a journalist found out through Google Trends that the British had googled only after the vote, what the Brexit means, many newspapers wrote about it, and only after a data analyst had looked at what was really happening, did everyone row back. Yes, there was more searching based on… see the 4th misunderstanding But compared to a popular search query, there was only a twitch. Data must always be put into context to get a feel for what it really means. Although I’m not a football fan, I like to use the search query , but also to see how relevant a term really is.
The weather is always searched for, but a certain seasonality can also be observed here, Bundesliga is primarily searched for by a part of the population, and that only seasonally, but interesting observations can also be made here.
We see the Friday game (first small dent in the blue curve), the Saturday games (biggest dent in the blue curve) and then again smaller dents for the Sunday games. The weather here has the highest swings, especially on Monday and Tuesday (maybe because of the snow?). So were you looking for the weather more often? No, not necessarily! Since here everything is calculated on an hourly basis, everything is calculated from the maximum on 8.11., 5 and 6 o’clock, at this time the search interest (search query/all search queries) was highest, and everything else is calculated relatively. So it can be theoretical that on Saturday afternoon you searched more often for Bundesliga than for weather on 8.11., but the total population of search queries was higher! What do we take with us? We always need a reference point, a benchmark, something with which we can compare the search interest. And best of all, we also know something about this reference point, as in this case, for example, that it snowed, and that’s why there were outliers.
Summary
The mechanism “I enter two terms into Google Trends and see which one is more popular” simply doesn’t work. This will be hard to get out of your heads, because the interface is wonderfully intuitive and literally leads to this interpretation, and it’s not completely wrong either. It’s difficult if you want to make momentous decisions based on this data, additional data is necessary. Keyword planner data are no longer available to everyone, but are not directly comparable anyway, since Google trend data do not compare pure terms.
And yet Google Trends is more than just a gimmick. You only have to invest a little more brain fat in all of the above to build a real story out of it.
Sorry for the lurid title, by the way. I wanted your attention. I hope it was worth it
Heute wirds mal etwas technischer. Über die Durchschnittliche Verweildauer in Google Analytics und anderen Webanalyse-Systemen habe ich schon viel geschrieben, sie stimmt in einer Standard-Installation nicht. In einem meiner Kurse sagte dann mal ein Teilnehmer, dass man doch einfach messen könne, wenn der Nutzer den Tab schließt, zum Beispiel mit beforeUnload. So ein Trigger ist schnell gebaut, hat aber auch Nachteile. Zunächst einmal ist das nicht zuverlässig, denn ein Benutzer kann auch einfach den Tab wechseln und nicht schließen, engagiert sich aber trotzdem nicht mit den Inhalten meiner Webseite, so dass die ermittelte Time on Site nicht richtig ist. Insbesondere auf mobilen Geräten sehe ich es eher selten, dass Nutzer ihre “Tabs” schließen. Aber darum geht es heute nicht, das ist mindestens einen weiteren Beitrag wert. In diesem Artikel geht es vor allem darum, wie wir überhaupt den Einsatz von onbeforeUnload messen debuggen können.
Das Problem: Unser Logging verschwindet, wenn der Tab geschlossen wird
Hintergrund: Wenn ein Nutzer einen Tab schließt oder im gleichen Tab eine andere Website aufruft, dann kann ich zwar das Event abfangen, aber im schlimmsten Fall verlangsamt das die User Experience, da in der Regel ein Get Request geschickt wird. Geht der Nutzer nur auf eine andere Site, dann sehe ich im GA Debugger zwar was vorher geloggt wurde; aber sollte der Nutzer den Tab schließen, dann ist auch meine Console weg. Natürlich kann ich im Echtzeit-Bericht von Google Analytics schauen, ob mein beforeUnload-Event ankommt, aber Debugging ist etwas anderes. Der Google Tag Manager Debug Mode hilft hier auch nicht, denn das beforeUnload Event ist nur ganz kurz zu sehen, wenn wir den Tab schließen.
Nutzen wir dann noch sendBeacon, dann wird es noch komplexer, denn der Google Tag Assistant kommt damit gar nicht klar, wahrscheinlich weil sendBeacon POST Requests sendet und keine GET Requests. sendBeacon hat aber den großen Vorteil, dass wir nicht die User Experience beeinträchtigen.
Die Lösung: Logging vom GA Debugger in eine Datei schreiben
Abhilfe schafft hier ein kleiner Hack. Wir starten Chrome mit einem Logging im Terminal und lassen uns dann zum Beispiel live die Logdatei ausgeben. Hier muss der GA Debugger immer noch aktiviert sein, denn er schreibt weiterhin brav in die Console, nur dass wir in der Datei sehen können, was er reingeschrieben hat, auch wenn der Tab schon geschlossen wurde.
Mit diesem Code starte ich meine Live-Ansicht des Loggings; der Parameter -f für tail bedeutet lediglich, dass ich immer sehen will, wenn an das Ende der Log-Datei etwas angehängt wird:
Ich nutze danach grep, um nur die relevanten Zeilen zu bekommen, denn Chrome loggt einiges mit; in diesem Fall schaue ich mir 11 Zeilen vor und 30 Zeilen nach dimension1 an (das kann natürlich auch irgendetwas anderes sein, ich weiß nur, dass bei mir die Dimension1 immer drin ist ). Und dann starte ich Chrome im Logging-Modus, hier der Befehl für den Mac:
Google Analytics kann mitunter fies sein, denn manche Dimensionen gepaart mit Segmenten verhalten sich nicht so, wie man das zunächst denken mag. Dank Michael Janssens und Maik Bruns‘ Kommentare auf meine Frage in der von Maik gegründeten Analyse-Gruppe kann ich heute beruhigt schlafen gehen und bin wieder ein bisschen schlauer geworden.
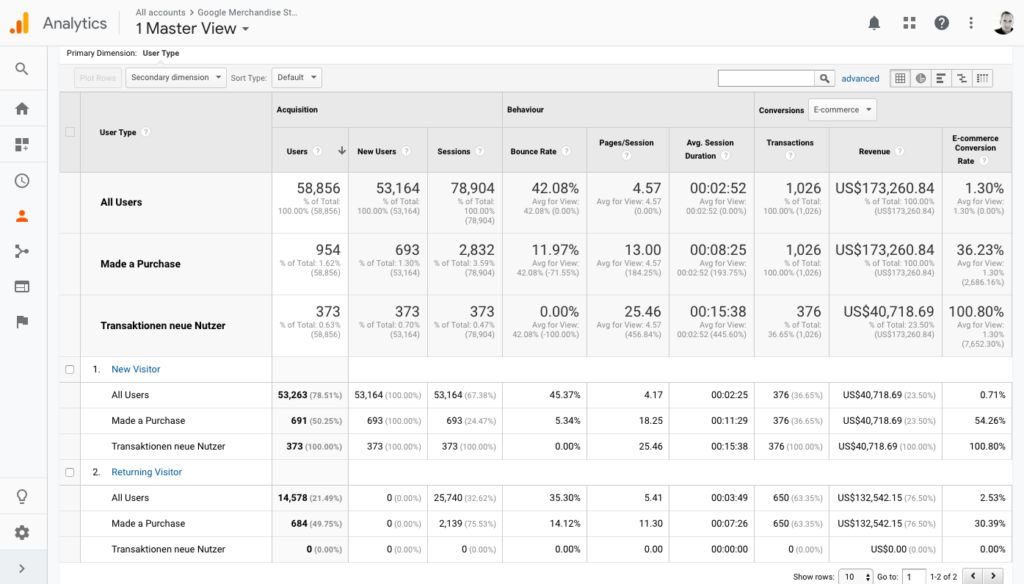
Die Frage kam heute im Analytics-Kurs auf: Wie kann es sein, dass ich mehr Neue Nutzer als Transaktionen habe, wenn ich in dem Segment “Hat einen Kauf getätigt” bin? Den Link zum Bericht gibt es hier, die Annahme, die ich hatte, war die: Wenn ich ein Segment von Nutzern habe, die einen Kauf getätigt haben, und dieses Segment im Bericht “Neue vs. wiederkehrende Nutzer” verwende, dann gehe ich davon aus, dass ich in dem Bereich Neue Besucher + Haben einen Kauf getätigt nur die Nutzer sehe, die in ihrem ersten Besuch etwas gekauft haben. Allerdings sehen wir hier in diesem Bericht 691 Nutzer, aber nur 376 Transaktionen. Wenn meine Erwartungshaltung stimmen würde, dann müsste die Zahl hier gleich sein. Ist sie aber nicht.
Neue Nutzer + Wiederkehrende Nutzer > Alle Nutzer
Wir sehen hier auch andere Widersprüche, und der Vollständigkeit halber fangen wir mit ihnen an. So liegt die Zahl der neuen Nutzer bei 53.263, die der wiederkehrenden Nutzer bei 14.578. Allerdings haben wir nur 58.856 Nutzer insgesamt, also weniger als die Summe der neuen und der wiederkehrenden Nutzer.
Diese Diskrepanz ist einfach erklärt: Wenn ein Nutzer innerhalb des Berichtszeitraums das erste Mal kommt, dann ist er ein Neuer Nutzer. Kommt er innerhalb des Berichtszeitraums ein zweites Mal, dann ist er auch ein Wiederkehrender Nutzer. Er wird also zwei Mal gezählt, einmal bei den Neuen Nutzern, einmal bei den Wiederkehrenden Nutzern. Bei “Alle Nutzer” wird er aber nur einmal gezählt.
Schauen wir einmal in die Spalte Transactions, so sehen wir, dass diese nicht mehrmals gezählt werden. Das ist logisch, denn sie können sich nur einmal als Transaktion definieren
Globale Seiten verzerren die Daten
Maik brachte noch den Punkt, dass globale Seiten etwas verzerrte Daten aufweisen, weil Google Analytics um Mitternacht alle Sessions neu startet, so dass ein neuer Besucher, der um 23:55 kommt und um 0:01 eine zweite Seite aufruft, an diesem zweiten Tag auch als Neuer Besucher gilt, wie am ersten Tag. Es ist derselbe Nutzer, aber er wird zwei Mal als neuer Nutzer gezählt (siehe Quelle hier). Aber kann das dazu führen, dass wir so viel mehr Neue Nutzer als Transaktionen haben? Sicherlich, der Google Merchandising Store ist globalgalaktisch aktiv, aber wird rund um die Uhr so viel gekauft?
Die Lösung: Kein Bool’sches UND
Die Lösung (Danke, Michael!) liegt darin, dass das Segment “Made a Purchase” gepaart mit “Neuer Besucher” nicht mit einem UND verknüpft sind, d.h. wir können hier Nutzer drin haben, die irgendwann gekauft haben, aber nicht unbedingt im ersten Besuch. Das wird deutlich, wenn wir unsere beiden Segmente mit einem Segment vergleichen, das Michael gebaut hat:
Michaels Segment ist so gebaut, dass es die UND-Verknüpfung nutzt:
Wir haben hier Sessions, in denen ein Nutzer neu sein muss und gleichzeitig mindestens eine Transaktion. Und wir sehen plötzlich, dass wir für die 376 Transaktionen 373 Nutzer haben, d.h. es muss Nutzer gegeben haben, die in ihrem Besuch mehrere Transaktionen gehabt haben. Mit anderen Worten, die Neuen Besucher in unserem Segment “Made a Purchase” haben zwar alle einen Purchase gemacht, aber 691 minus 376 Transaktionen wurden von diesen Neuen Besuchern nicht während ihres ersten Besuchs gemacht, sondern in einem späteren. Die Verknüpfung des Berichts und des Segments könnte man so formulieren: Zeig mir alle Benutzer, die in irgendeiner Session eine Transaktion hatten und innerhalb des Berichtszeitraums auch ihren ersten Besuch.Sie bedeutet nicht, zeig mir alle Nutzer, die in ihrer ersten Session auch eine Transaktion haben.
In Zukunft werde ich etwas genauer schauen, wie die Verknüpfung eines Segments mit einem Bericht zu interpretieren habe. Denn das war, wie gesagt, etwas fies
This is not a love song. Dies ist auch keine Liebesgeschichte. Zumindest nicht über dieses Produkt. Dies ist die Geschichte des Kickstarter-Projekts von Revols, in dem es um eine super Idee ging, die aber irgendwie nicht zu einer Erfolgsstory wurde. Im Januar 2016 finanzierte ich die Kickstarter-Kampagne von Revols mit, $219 für Kopfhörer, die sich automatisch meinem Ohr anpassen. Eine super Geschichte, dachte ich, denn meinen Ohrschutz, den ich bei Konzerten oder beim Schlagzeugspielen immer trage, habe ich beim Hörgeräte-Akustiker auch für knapp 200€ damals erstellen lassen, und ich bin nach vielen Jahren immer noch schwer überzeugt davon. Für das gleiche Geld dann Wireless Kopfhörer bekommen? Wunderbare Idee.
Hier das Kickstarter-Video, das mich überzeugt hatte:
Im Juni 2016 sollten die Kopfhörer ankommen. Mit etwas mehr als zwei Jahren Verspätung kam das Produkt tatsächlich an. Knapp 40€ Zoll noch drauf. Ärgere ich mich darüber? Nein, kein bisschen, Es geht hier um ein komplett neues Produkt, und man kann die Gründer nur bewundern, dass sie trotz aller Widerstände durchgehalten haben. Zwischendurch wurden sie von Logitech gekauft, die Wahrscheinlichkeit nix mehr zu sehen war also gering. Es ist auch nicht mein erstes Produkt, das ich bei Kickstarter gekauft habe, das Vi war auch so ein Projekt, das erst mal ein paar Kinderkrankheiten überstehen musste. Das ist halt das Risiko eines Early Adopters
Was an den Revols suboptimal ist
[
as stört mich also? Zunächst einmal, die Kopfhörer sind riesengroß. Ja, das hätte mir schon im Video auffallen müssen. Aber wenn man sie dann wirklich in der Hand hat, dann wirken sie irgendwie größer. Ich hab sie zum Vergleich mal auf ein Reclam-Heft gelegt, das hat den Vorteil, dass wahrscheinlich jeder die Größe eines Reclam-Hefts kennt und so selber einschätzen kann, wie groß die Hörer sind. Ich frage mich, ob es nicht kleiner gegangen wäre.
Und dann… passen sie nicht einmal sonderlich gut. Sie fallen mir aus dem Ohr. Und ja, ich habe die Anleitung genau befolgt. Der Sound ist nicht besonders toll. Das kann natürlich daran liegen, dass sie nicht richtig sitzen. Aber selbst wenn ich sie mir ins Ohr drücke, dann klingen sie eher naja. Der Sound wirkt auf mich leise, der Bass kommt nicht richtig, selbst die Vi-Hörer sind besser.
Aus den angekündigten 8+6 Stunden Akku-Laufzeit (8 Stunden die Kopfhörer selbst und 6 Stunden der Zusatzakku) sind 5+5 Stunden geworden. Ich komme auf ca. 4+4 Stunden. Kommuniziert wurde die verringerte Akku-Laufzeit meines Wissens nach nicht.
[
ann sind hier trotz Wireless jede Menge Kabel zu sehen. Das Aufladekabel wirkt nicht sehr stabil, und da an dem Kabel gezogen werden muss, wenn man die Auflademuscheln von den Aufladestäben trennen will, dann habe ich immer Angst, dass das dürre Kabel reisst. Zwar soll das so geprüft worden sein, aber so richtig stabil wirkt es eben nicht.
Insgesamt habe ich 250€ ausgegeben, und für das Geld hätte ich wahrscheinlich weniger Kabelsalat, mehr Qualität und eine schnellere Lieferung gehabt, dafür nur keine angepassten Hörer, die bei mir aber eh nicht gut passen. Tatsächlich stehe ich auch nicht allein da mit meiner Meinung, wenn ich mir andere Reviews auf YouTube ansehe:
Aber wie der Autor dort selbst sagt, auf Kickstarter verzichten würde ich trotz mancher Enttäuschungen nicht. Denn man hat die Chance, neue Technologien zu erleben, bevor sie die große Masse in die Hand bekommt. Oder manchmal auch einfach eine smarte Idee zu finanzieren, die das Leben einfacher macht. Insgesamt habe ich schon eine kleine zweistellige Anzahl von Kickstarter- und Indiegogo-Projekten unterstützt. Manche wurden gecancelt wie das MOTI, manche Firmen gingen nach Auslieferung pleite wie die Hersteller vom Backbone, der Hangbird war eine der besten Anschaffungen überhaupt (und nicht wirklich Hightech), auf die Dokumentation über Dieter Rams freue ich mich wie ein Kleinkind, und auch wenn der Reward von Mine Kafon Drone eher symbolischer Natur war, die Idee die Welt von Landminen zu befreien, ist einfach nur wunderbar.
 onsole API, die nur noch aktiviert werden muss.
onsole API, die nur noch aktiviert werden muss.