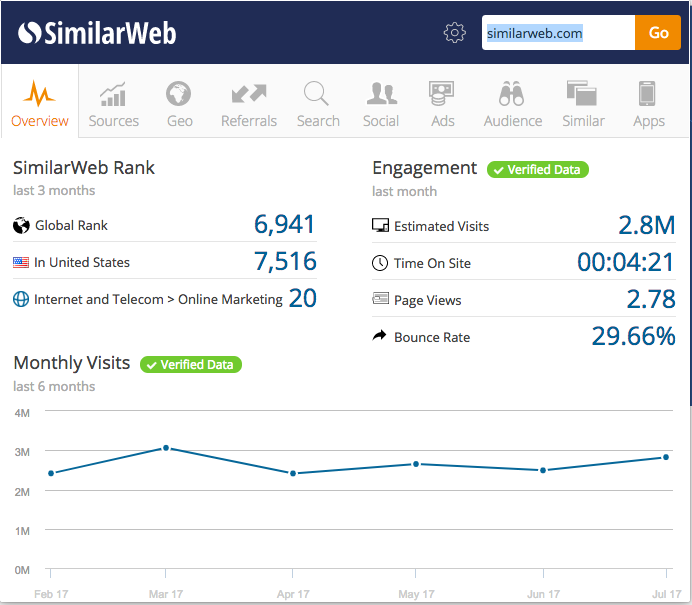
As with Google Trends, I’m always surprised at how quickly conclusions can be drawn from data without having to think about where the data actually comes from and how plausible it is. Especially with Similar Web, this is amazing, because Google has the search data and can read trends from it, but how can Similar Web have data about how many visitors a website or app has? How reliable is this data? Is the reliability sufficient to make important business decisions?
The ancestor of SimilarWeb
In 2006, my former colleague Matt Cutts had once investigated how reliable Alexa’s data is (Alexa used to be an Amazon service that had nothing to do with speech recognition). This service collected data with a browser toolbar (there’s no such thing anymore), i.e. every page a user looked at was logged. Since Alexa was especially interesting for webmasters, pages that are interesting for webmasters were logged. So they were distorted. So if you are already recording the traffic of users, then you have to somehow make sure that the user base somehow corresponds to the network population you want to find out about. That doesn’t mean that the data is completely worthless. If you compare two fashion sites with each other, then they are probably “uninteresting” for the webmaster population (a prejudice, I know), and then you could at least compare them with each other. But you couldn’t compare a fashion page with a webmaster tool page.
But where does Similar Web get the data from? On their website they give 4 sources:
- An international panel
- crawling
- ISP data
- direct measurements
Data collection via a panel
The panel is not explained in detail, but if you do only minimal research, you will quickly find browser extensions. These are probably the successors of the earlier browser toolbars. What is the advantage of the Similar Web Extension? It offers exactly what Similar Web offers: You can see with one click how many users the currently viewed page has, where they come from, and so on. The Similar Web-Extension does not only work at home if you are currently viewing the data for a page, but for every page you are viewing.
If you consider for whom such data is interesting and who then installs such an extension, then we have arrived at the data quality of the Alexa Top Sites. Webmasters, marketing people, search engine optimizers, all these people have a higher probability to install this extension than for example a teenager or my mother.
Crawling
What exactly Similar Web crawls is still a mystery to me, especially why a crawling can give information about how much traffic a page has. Strictly speaking, you only cause traffic with a crawler Similar Web says, “[we] scan every public website to create a highly accurate map of the digital world”. Probably links will be read here, maybe topics will be recognized automatically.
ISP traffic
Unfortunately, Similar Web does not say which ISPs they get traffic data from. It’s probably forbidden in Germany, but in some countries it will certainly be allowed for an Internet service provider to have Similar Web’s colleagues record all the traffic they receive through their cables. That would of course be a very good database. But not every ISP is the same. Would we trust the data if, for example, AOL users were in it (do they still exist at all)?
Direct measurements
This is where it gets exciting, because companies can link their web analytics data, in this case Google Analytics, directly to Similar Web, so that the data measured by Google Analytics is available to all Similar Web users. Then the site says “verified”. Why should you do that? You don’t get anything for it, instead you can expect more advertising revenue or strengthen your brand. Quite weak arguments, I think, but there are still some sites that do.
How reliable is Similar Web data really?
Of course, the direct measurements are reliable. It becomes difficult with all other data sources. These make up the majority of the measurements. Only a fraction of the Similar Web data is based on my sample of direct measurement data. But here you could certainly create models based on the accurately measured data and the inaccurately measured data. If I know how the data from spiegel.de is accurate and what the inaccurately measured data looks like, then I could, for example, calculate the panel bias and compensate for other pages. And I could do the same with all other data.
But does it really work? Let’s take a look at a measurement of Similar Web for one of my pages:
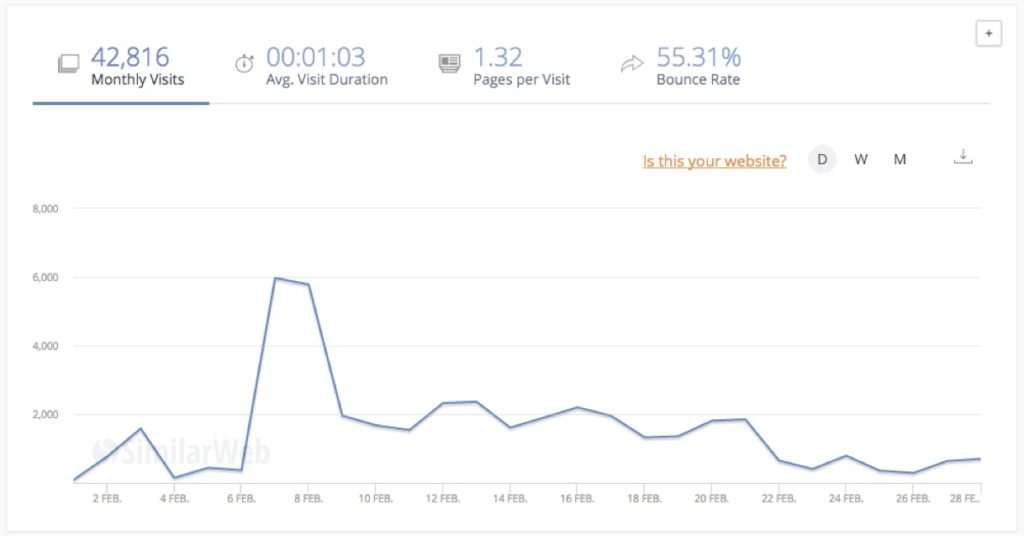
Apparently the number of visitors fluctuates between as good as nothing and 6,000 users. There are no clear patterns. And now we look at the real numbers from Google Analytics:

It’s the same time period. And yet the unique traffic patterns from the Google Analytics data are not recognizable in the Similar Web data. The data is simply wrong.
Result
Can you use Similar Web at all? I would advise you to be very careful if the data does not come from a direct measurement. Of course, the question can now arise as to what else to use. The counter-question is what to do with data that you can’t be sure is correct at all. If I had to make a business decision that might cost a lot of money, I wouldn’t rely on that data. For a first glance…? We also know that a “first glance” can quickly become a “fact” because it fits so well into one’s own argumentation.