Wer mein Blog schon länger verfolgt, hat bemerkt, dass ich in den letzten Jahren immer mehr Finanzthemen behandelt habe. Jahrelang hatte ich einem MLP-Finanzberater vertraut, und auch wenn ich dadurch viele Dinge erst richtig aufgestellt hatte, kam in den letzten Jahren immer mehr ein Unwohlsein auf, dass er einem nicht die ganze Wahrheit erzählt. Letztes Jahr habe ich mich von ihm und MLP getrennt, nachdem mir das ständige Geschwafel, wie toll ein Fonds-Manager seinen Job mache und seine 2,4% Aufschlag wert sei, zu sehr auf den Keks ging. Eine Beratung durch einen unabhängigen Honorarberater (Vorsicht: viele sagen, sie seien unabhängig, aber die tatsächlich unabhängigen Berater bekommen ein Honorar vom Klienten, nicht eine Provision von einer Versicherung) hatte dann ergeben, wie sehr zu meinem Nachteil meine Finanzangelegenheiten geregelt wurden. Darüber werde ich noch mal mehr schreiben, aber heute geht es um einen Teilbereich, nämlich Aktien, Fonds, ETFs. Und ich bedaure es sehr, dass ich Grahams Buch nicht schon viel früher gelesen habe.
Ein bisschen überraschend war das schon. Ich hatte mit Jim Sterne vor kurzem noch gemailt, als es um den deutschen Ableger ging. Die DAA hatte meinem Webanalyse-Buch auch ein Geleitwort gespendet. Ein bisschen schade ist es schon.
Wer es nicht weiß: Die DAA war früher die WAA, die Web Analytics Association, und sie hat die meistgenutzte Definition von Web Analytics geschaffen. Zwar war diese Definition schon lange nicht mehr auf der Webseite zu finden, aber das hat die meisten Wissenschaftler, die die Zitate aus anderen Papern kopieren, nicht interessiert.
Wie aber kann es sein, dass trotz der Wichtigkeit von Daten eine solche Organisation aufgibt? Es könnte zum Beispiel daran liegen, dass viele zwar Google Analytics & Co installiert haben, aber die Daten gar nicht genutzt werden. In meinem letzten Paper, das leider noch nicht öffentlich ist, kam heraus, dass den meisten Anwendern auch gar nicht klar ist, dass das Einbinden des GA-Codes nicht ausreicht, um datengetrieben zu arbeiten. Und vielleicht liegt es auch ein bisschen an der DAA selbst, dass sie es nicht geschafft hat, die eigene Relevanz deutlich zu machen.
Ich war zuletzt nur noch aus Nostalgiegründen Mitglied. Dabei hatte ich meinen Studierendenstatus ausgenutzt, um die Mitgliedsbeiträge etwas zu senken.
Was? Wieso sollte jemand von einem Neo-Broker zu einer mehr oder weniger klassischen Bank wechseln wollen? Vor allem, wenn das Depot 18 Monate vorher von der ING zu Scalable gezogen war? Ist die ING nicht viel teurer, weniger flexibel und außerdem uncooler als Scalable Capital?
Vor 3 Jahren, zum 15. Geburtstag dieses Blogs, war ich umgezogen von WordPress zu Hugo. Superschnelle Seiten, alles in R, eigentlich eine coole Sache. Aber in der Realität war es nicht so cool. Ich brauchte immer eine R-Umgebung, die ich nicht immer hatte. Git machte mich manchmal wahnsinnig. Und manche Probleme waren einfach nicht nachzuvollziehen. Und so bin ich jetzt wieder umgezogen. Vielleicht kommen nun auch die Rankings wieder zurück, die ich auch verloren hatte nach dem Umzug.
Letzten Monat hatte ich noch positiv über Scalable Capital geschrieben, der November hat allerdings dafür gesorgt, dass ich vom Scalable Capital-Promoter zum Detractor geworden bin, um den NPS-Jargon zu verwenden.
Künstliche Intelligenz bezieht sich auf das breite Feld der Informatik, das Maschinen die Fähigkeit gibt, Aufgaben auszuführen, die menschliche Intelligenz erfordern. Ein Beispiel im Marketing ist die Entwicklung von intelligenten Chatbots, die Kundenanfragen automatisch beantworten.
Machine Learning
Machine Learning ist ein Teilbereich der KI, der Maschinen befähigt, aus Daten zu lernen und sich anzupassen, ohne explizit programmiert zu werden. In der Marketingwelt wird Machine Learning beispielsweise genutzt, um Kundentrends vorherzusagen und personalisierte Werbeinhalte zu erstellen.
Data Mining
Data Mining ist der Prozess des Entdeckens von Mustern in großen Datensätzen. Es ist ein wichtiger Teil der Data Science und wird im Marketing eingesetzt, um beispielsweise Kundensegmente zu identifizieren und Zielgruppen besser zu verstehen.
Data Science
Data Science ist das Feld, das Techniken aus Statistik, Machine Learning und Datenanalyse kombiniert, um Erkenntnisse aus Daten zu gewinnen.
Statistik
Statistik ist die Grundlage für Data Science und Machine Learning. Sie befasst sich mit Methoden zur Analyse und Interpretation von Daten. Im Marketingkontext wird Statistik verwendet, um Kundentrends zu analysieren und Hypothesen zu testen, wie z.B. bei A/B-Tests. Böse Zungen behaupten, dass Data Science einfach nur Statistik im neuen Gewand sei. Allerdings ist Data Science eher eine Kreuzung von Statistik und Informatik, da hier auch große Datenmengen bearbeitet werden.
Überlappungen und Unterschiede
Überlappungen: Machine Learning ist ein Teilbereich der KI und wird in der Data Science angewendet. Sowohl Data Mining als auch Machine Learning nutzen statistische Methoden.
Unterschiede: Während KI ein breites Feld mit verschiedenen Anwendungen ist, konzentriert sich Machine Learning spezifisch auf das Lernen aus Daten. Data Science vereint diese Techniken, um datengetriebene Erkenntnisse zu gewinnen.
Ich bin seit sieben Jahren Kunde bei Scalable Capital, zunächst bei dem für mich eher enttäuschenden RoboAdvisor, seit zwei Jahren aber zufriedener Kunde des Prime Brokers.
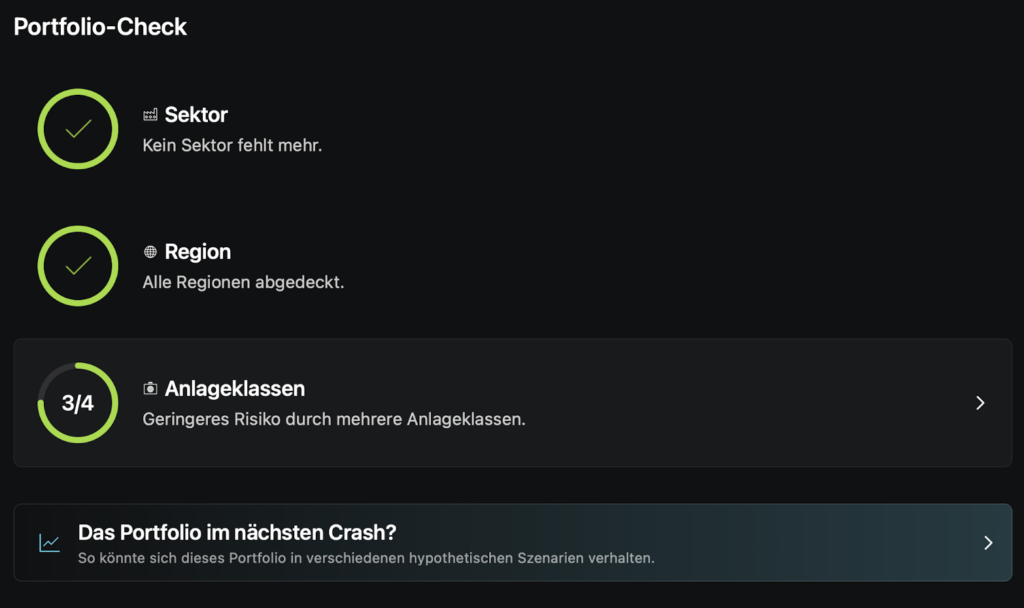
Diese Woche habe ich neue Funktionen entdeckt, zunächst ein Teil davon in der Desktop App, in der Web App sieht man aber schon alles, was Neues angeboten wird. Die neue Funktion nennt sich Insights und basiert auf Daten von BlackRock. Damit das funktioniert werden die Portfoliodaten anonymisiert zu BlackRock geschickt. Zunächst einmal gibt es einen Portfolio Check, wo geprüft wird, wie stark das Portfolio diversifiziert wird.
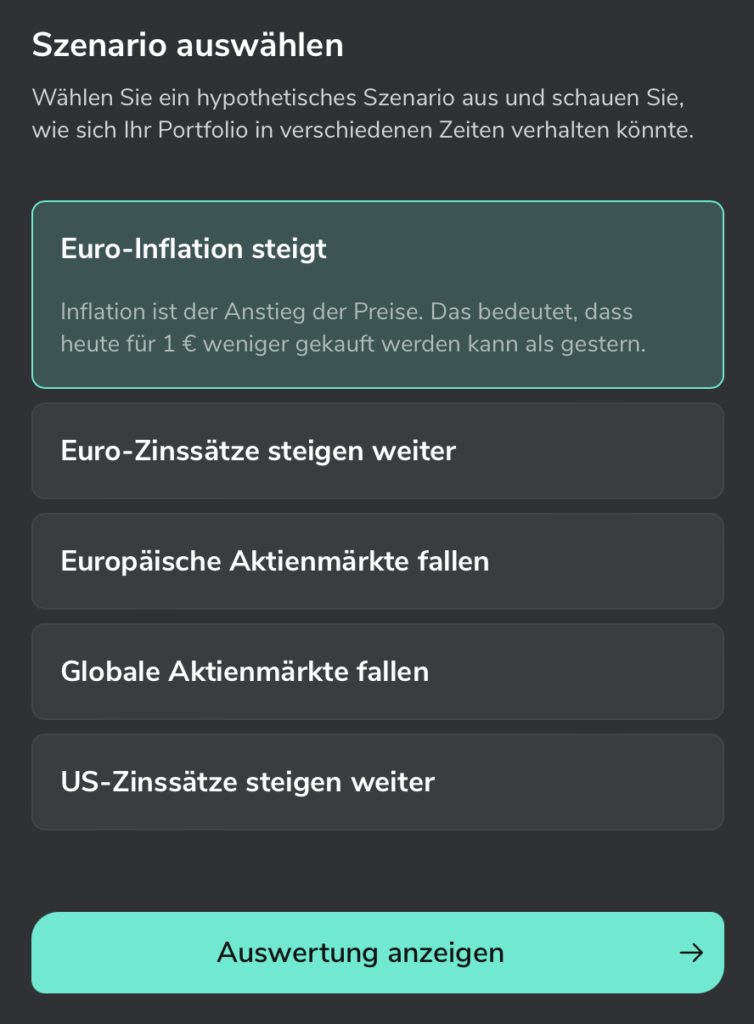
Allerdings wird hier nicht geprüft, wie die Gewichtung ist. Ich habe, nachdem ich diese Grafik gesehen hatte, ein bisschen in eine Anleihe investiert, und schon war der Ring voll. Als nächstes ist eine Crash-Simulation zu sehen, wo man mehrere Szenarien auswählen kann. Die globalen Aktienmärkte fallen in dieser Simulation z.B. um 10%, wobei ich bisher dachte, dass man erst ab 30% von einem Crash sprechen würde.
In so einem Szenario würde mein Portfolio stärker leiden als der Benchmark:
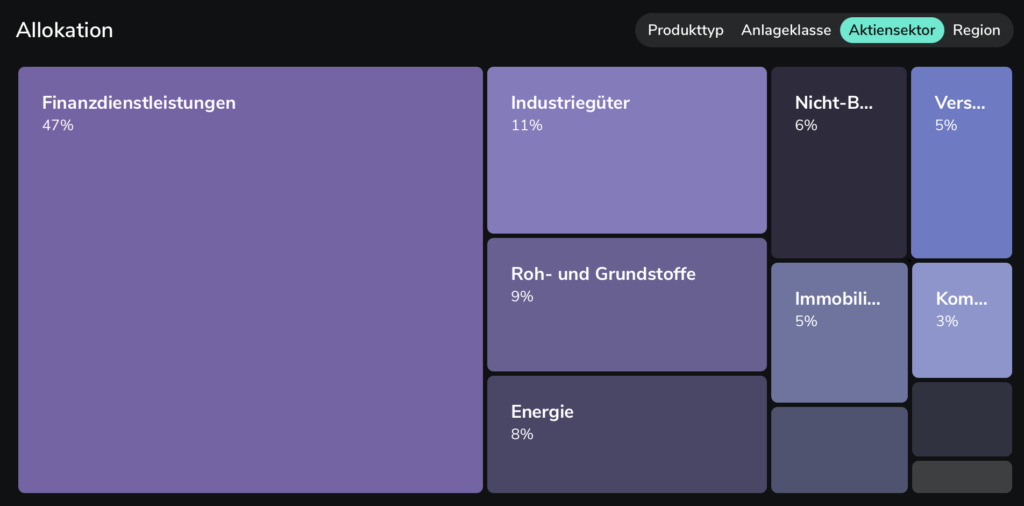
Die nächste neue Funktion ist die Analyse der Allokation des Portfolios in Bezug auf Branchen, Regionen etc:
Bei mir sieht das so aus, als ob ich Finanzdienstleistungen generell übergewichtet hätte, aber tatsächlich ist das nur auf den ersten Blick so. Durch die Dividenden-Treiber Hercules und Ares Capital sieht das größer aus als es eigentlich sein sollte. Dann gibt es noch diese wunderbare Analyse der Unternehmensarten:
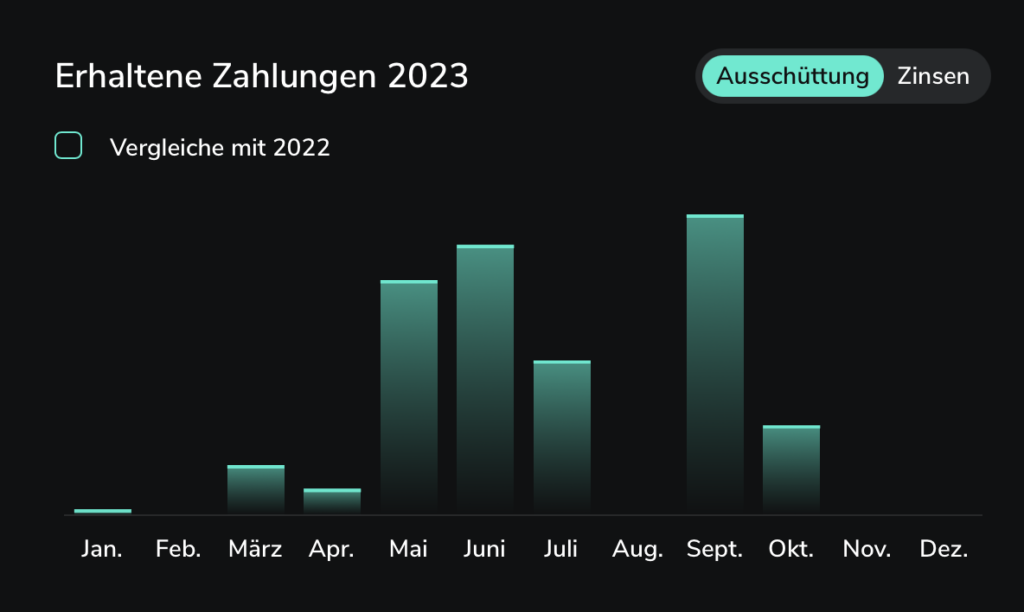
Sowas habe ich bisher vor allem bei ExtraETF gesehen. Und dann, für mich eigentlich am Spannendsten, die Dividenden, denn ich verfolge eine Dividendenstrategie:
Hier würde ich mir wünschen, dass man auch eine Projektion in die Zukunft sehen könnte wie bei ExtraETF, wenngleich man dort auch nur die nächsten Monate im gleichen Kalenderjahr sieht. Aber so sehe ich halt besser, ob ich mich gerade auf dem richtigen Weg befinde oder nicht. Was mir halt an extraETF nicht gefällt ist die wacklige Verbindung zu Scalable. Manchmal geht sie, manchmal nicht. Deswegen bin ich dort auch kein Abonnent mehr.
Scalable nimmt solchen Tools wie ExtraETF, getQuin und DivvyDiary das Marktpotential, wenn sie weiter solche Funktionen einbauen. Für mich aber noch mehr ein Grund, bei Scalable zu bleiben. Sicherlich könnten diese Funktionen noch intelligenter werden und Anleger wie mich, die keinen teuren Roboadvisor nutzen wollen, noch stärker unterstützen bei der Auswahl der Anlagen.
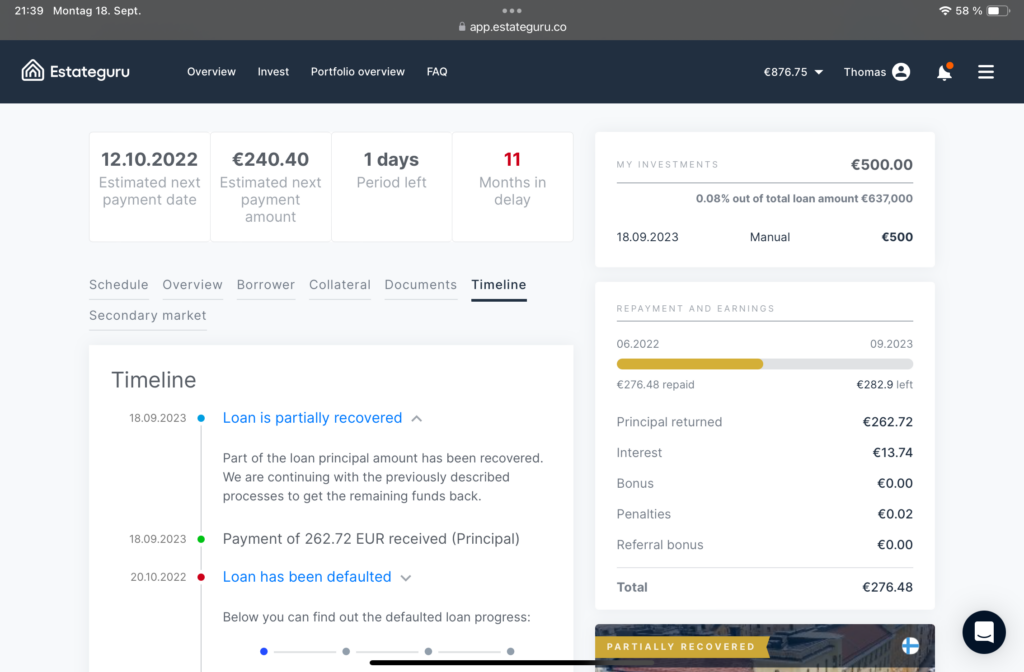
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
repaid <- filter(data, Status == "Repaid")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
Interest Rate`
in_default <- filter(data, Status == "In Default")
Tatsächlich wurde nun ein erstes Projekt zumindest teilweise eingeholt, von 500 Euro sind 262,72 Euro wieder da:
Estateguru Project partially recovered
Ansonsten hat sich wenig getan seit meinem letzten Update. Dennoch habe ich mich entschlossen, wieder zu investieren. 2/5 meiner Investitionssumme habe ich abgezogen, der verbleibende Betrag ist zwar immer noch ansehnlich, aber macht nicht mehr einen zu großen Anteil meines Portfolios aus. Außerdem habe ich einen Riegel vor die Thesaurierung geschoben, zumindest so gut es ging. Denn leider kann man bei Estateguru nicht sagen, dass man nur Summe x investiert haben will, so dass die Zinsen dann immer abrufbar sind. Stattdessen kann man sagen, dass man eine bestimmte Summe immer vorgehalten haben will, was nicht ganz so prall ist, denn wenn ich zum Beispiel 10.000 Euro investiert hätte und jeden Monat 100 Euro abziehen und damit reservieren möchte, dann aber eine Zahlung von 300 Euro bekäme, dann wären sehr schnell mehr als 10.000 Euro investiert, auch wenn ich das gar nicht will. So richtig hilfreich war der Support da nicht.
Estateguru bietet ja die Möglichkeit, die eigenen Portfolio-Daten herunterzuladen, was es mir ermöglicht, mal genauer zu schauen, was eigentlich schief gelaufen ist:
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, x = as.factor(Country))) +
geom_bar() +
theme_minimal() +
xlab("Land")
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
data %>%
group_by(Country, Status) %>%
ggplot(., aes(fill = Status, y = `Initial Principal`, x = as.factor(Country))) +
geom_bar(stat = "identity") +
theme_minimal() +
xlab("Land") +
ylab("Darlehensbetrag in Euro")
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Wir sehen auf jeden Fall den einen Outlier, wo ich 2.500 Euro investiert hatte bei ca. 11 Prozent. Es sieht auch so aus, dass vor allem bei den höheren Zinssätzen Ausfälle sind, nur nicht bei den deutschen Projekten, da habe ich sie überall. So ganz passt das aber nicht, da man in manche Projekte über mehrere Stages investieren konnte:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
data %>%
filter(Status == "Repaid" | Status == "In Default") %>%
group_by(Status) %>%
summarize(mean_interest = mean(`Interest Rate`), median_interest = median(`Interest Rate`))
## # A tibble: 2 × 3
## Status mean_interest median_interest
## <chr> <dbl> <dbl>
## 1 In Default 10.7 10.5
## 2 Repaid 10.0 10
Der Shapiro-Wilk-Test hilft uns, um die Normalität der Daten zu überprüfen.
cat("P-value for Repaid group:", shapiro_test_repaid$p.value, "\n")
## P-value for Repaid group: 1.143358e-08
cat("P-value for In Default group:", shapiro_test_in_default$p.value, "\n")
## P-value for In Default group: 6.078673e-05
Die p-Werte sind signifikant (unter 0,05), was darauf hinweist, dass die Daten nicht normalverteilt sind. Darum der Mann-Whitney-U-Test verwendet, ein nichtparametrischer Test, um die Zinssätze der beiden Gruppen zu vergleichen.
wilcox_test <- wilcox.test(repaid, in_default, alternative = "two.sided")
cat("P-value for Mann-Whitney U test:", wilcox_test$p.value, "\n")
## P-value for Mann-Whitney U test: 6.66547e-08
Der p-Wert ist signifikant, also unter 0,05, was darauf hinweist, dass es einen signifikanten Unterschied in den Zinssätzen zwischen den zurückgezahlten und den in Verzug geratenen Darlehen gibt. Dies ist nun über das ganze Portfolio geschehen. Wie sieht das pro Land aus?
countries <- unique(data$Country)
# Function to analyze each country
analyze_country <- function(country) {
cat("Analyse für", country, ":\n")
# Filter data by country and status
data_df <- data %>% filter(Country == country) %>% filter(Status %in% c("Repaid", "In Default"))
# Check if there is enough data for both categories
if (nrow(data_df) > 0 & length(unique(data_df$Status)) > 1) {
repaid <- data_df %>% filter(Status == "Repaid") %>% select(`Interest Rate`) %>% unlist()
in_default <- data_df %>% filter(Status == "In Default") %>% select(`Interest Rate`) %>% unlist()
test <- wilcox.test(repaid, in_default, exact = FALSE)
cat("Mann-Whitney U Test-Ergebnis: W =", test$statistic, ", p-value =", test$p.value, "\n\n")
} else {
cat("Nicht genug Daten für die Analyse.\n\n")
}
}
# Analyze each country
for (country in countries) {
analyze_country(country)
}
## Analyse für Estonia :
## Mann-Whitney U Test-Ergebnis: W = 77 , p-value = 0.02871484
##
## Analyse für Germany :
## Mann-Whitney U Test-Ergebnis: W = 101 , p-value = 0.5058534
##
## Analyse für Lithuania :
## Mann-Whitney U Test-Ergebnis: W = 224.5 , p-value = 3.126943e-06
##
## Analyse für Finland :
## Mann-Whitney U Test-Ergebnis: W = 54 , p-value = 0.8649381
##
## Analyse für Spain :
## Nicht genug Daten für die Analyse.
##
## Analyse für Portugal :
## Nicht genug Daten für die Analyse.
##
## Analyse für Latvia :
## Mann-Whitney U Test-Ergebnis: W = 12 , p-value = 0.04383209
Tatsächlich ist der Unterschied in Deutschland nicht signifikant. Ich war hier also doch nicht so gierig, wie ich dachte 🙂
Was, wenn ich in alle Kredite nur 50 Euro investiert hätte und nicht manchmal sehr viel mehr? Wie stünde ich heute da?
Hier sieht man schon sehr deutlich, dass ich mit meiner Strategie, bei einigen Projekten mehr auszugeben, auf die Nase geknallt bin. Es wäre besser gewesen, ausgewogener und diversifizierter zu investieren. Genau das mache ich nun anders.







 Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht.
Wie man hier schön sehen kann, habe ich in Deutschland zwar weniger Projekte gehabt als in Estland zum Beispiel, aber hier sind die meisten Projekte ausgefallen. Das ist schon erschreckend. Noch schlimmer sieht es aus, wenn man sich die tatsächlichen Summen ansieht. Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
Gibt es einen Zusammenhang zwischen Interest Rate und dem Status “ausgefallen”, d.h. habe ich in meiner “Gier” zu riskante Kredite übernommen, die sich durch höhere Zinsen auszeichneten? Erst mal visualisieren wir mehrere Variablen:
 Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an:
Anscheinend war ich in Deutschland besonders mutig, weil ich dachte, dass Kredite dort sicherer sind, und bin daher mehrmals über die mir selbst gesetzte Grenze von 500 Euro pro Projekt gegangen. Einen statistisch signifikanten Unterschied auszurechnen wäre die Aufgabe. Fangen wir aber erst mal anders an: