Nach knapp 2 Jahren habe ich meine 3 Google Wifi Pucks –in Rente geschickt– auf eBay eingestellt. Erste Probleme hatten sich bereits vor einem Jahr eingestellt als einer der Pucks von einem Tag auf den anderen aufgehört hatte zu arbeiten. Zwar funktionierte er noch, aber er konnte sich nicht mehr mit dem Haupt-Zugangspunkt auf der anderen Seite der Mauer verbinden. Selbst wenn er genau neben dem anderen Puck stand, wollte er sich nicht mehr zuverlässig verbinden. Der Google Wifi Puck wurde von Google sofort ausgetauscht, nur das Problem war nicht gelöst. Sehr wahrscheinlich hatte sich ein anderes Netzwerk in der Nachbarschaft breit gemacht, und tatsächlich hatte der Nachbar unter mir sich ein neues, starkes WLAN besorgt. Das automatische Wechseln der Kanäle ist eine nette Theorie, aber so richtig gut funktioniert es nicht. Zwar wechseln die Wifis ihre Kanäle ab und zu, aber nur um dann gemeinsam auf dem gleichen Kanal abzuhängen.
Als wir diese Wohnung in dem fast 150 Jahre alten Haus sanierten, fragte uns der Elektriker, ob wir nicht Ethernet gelegt haben wollten. “Nein, warum denn, ich hab doch WIFI?”, sagte ich, und das war eine der schlechtesten Entscheidungen, die ich jemals getroffen habe. Mit 8 Sonos-Boxen, 3 bis 5 Handys, 1 Tablet, mehreren Smart Home-Devices wie zum Beispiel von tado sowie jede Menge anderer Geräte im WLAN gibt es hier schon jede Menge Stress. Die Lösung für mein WLAN-Problem sollten daher PowerLine-Adapter von tp Link bilden. Diese leiten angeblich bis zu 1.300 MBit/s durch, und natürlich ist das ein theoretischer Wert. Tatsächlich aber schafften sie tatsächlich je nach Raum zwischen 200 und 950 MBit. Nur im Arbeitszimmer, wo ich das Netz am nötigsten bräuchte, da war die Verbindung sehr unsicher. Entweder war sie gar nicht da, oder sie schwankte zwischen 8 und 200 MBit/s. Richtig Spaß macht das nicht.
Da ich momentan etwas mehr Zeit im Arbeitszimmer verbringe (nach dem Buch ist vor dem Buch), nervte die schlechte WIFI-Verbindung immer mehr. Und ständig den Ethernet-Adapter (der muss an meinem MacBook Air an den alten Thunderbolt-Port, denn der USB-Adapter schafft nur 100MBit/s) anzuschließen, nun ja…. Gestern Abend fiel das Netz dann ständig aus, und dann suchte ich noch mal nach anderen Mesh-Netzwerken. Von dem Netgear Orbi hatte ich schon einige gute Sachen gelesen. Um 0:58 am Samstag Morgen bei Amazon das NETGEAR Orbi High Speed Mesh WLAN System RBK50-100PES (3.000 MBit/s Tri-Band Mesh Router + Satellit Repeater, 350 m² Abdeckung) bestellt, um 11:58 am selben Tag hatte ich es von einer Amazon Locker Station abgeholt (Danke, Amazon! Eigentlich sollte das erst nach dem Wochenende geliefert werden, aber noch am selben Tag ist schon sehr nett).
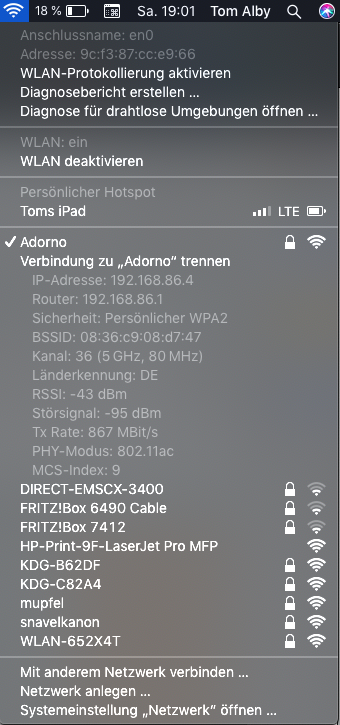
Weniger als eine Stunde später war es eingerichtet. So einfach wie mit dem Google Wifi ist es nicht. Die App ist weniger verständlich, manche Einstellungen wie Port-Weiterleitungen können nur im Browser vorgenommen werden. Aber die Geschwindigkeit… der Satellit steht nun im Arbeitszimmer, und seitdem habe ich keinen einzigen Abbruch mehr gehabt. Besser noch, die Geschwindigkeit ist besser als was ich jemals bisher hatte. In dem Screenshot links sieht man eine Tx Rate von 867 MBit/s. Das scheint das Maximum zu sein, was mein altes MacBook Air auf dem 5 GHz-Band zustande bekommt. Natürlich sind wir hier noch nicht bei den 3.000 MBit/s, die das Netz theoretisch bietet. Aber, um ganz ehrlich zu sein, mit wem sollte sich das MacBook dann auch verbinden? Meine NAS hat zwar einen 10 GBit-Ethernet-Anschluss, hängt aber an einem 1 GBit-Switch, an dem auch das Orbi hängt. Meine Tests zeigen momentan eine maximale Geschwindigkeit von 330 MBit/s zur NAS, wenn ich dort auf eine SSD schreibe, das sind etwas mehr als 40 MByte/Sekunde. Nicht schlecht, wenn man überlegt, dass ich vorher eher nur bangen konnte, dass meine Verbindung überhaupt hält.
Natürlich ist es kein Wunder, dass das Netgear-Gerät mehr Dampf drauf hat: Es ist um einiges größer, so dass auch mehr Platz für Antennen drin steckt. Ja, es ist teurer im Vergleich zum Google Wifi, aber bei mir scheint es zumindest momentan die Lösung für WLAN-Probleme zu sein. Der Langzeit-Test steht noch bevor. Zumindest die Google Wifi-Pucks haben ihn leider nicht überstanden.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Internet Speedtest says
November 2019 at 16:05 Hallo, ich nutze auch ein Netgear Orbi RBK53 System mit 3000MBit/s. Genau diese 3000MBit/s möchte ich dir kurz erklären bzw. wie sich diese zusammensetzen.
1733 MBit/s (4MIMO Streams mit je 433 MBit/s im 5GHz Netz für den Orbi Router und den Satellitten) Dieses Netz siehst du nicht dass ist nur für die interne Verbindung. 867 MBit/s (2MIMO Streams mit je 433 MBit/s im 5GHz Netz für die Clients) 400 MBit/s (2MIMO Streams mit je 200 MBit/s im 2,4GHz Netz für die Clients)
1733 + 867 + 400 = 3000 MBit/s (die du aber an einem Client nie bekommen kannst)
Viel Spaß mit deinem Orbi System! Ich werde mir nie wieder etwas anderes fürs WLAN kaufen…
Mit jedem Google-Update werden die Rankings für manche Seiten durcheinander gewirbelt, und ab und zu fragt man sich, warum es manche Seiten trifft und andere nicht. Denn zum Teil werden Seiten „abgestraft“, bei denen man sich die Frage stellt, wie kann das sein? Das ist doch eigentlich eine gute Seite?
Dass Google Machine Learning nutzt, um die Relevanzberechnungs-Algorithmen zu optimieren, ist bekannt. Aber wie genau funktioniert das? Und was bedeutet das für Suchmaschinenoptimierer?
Wie Machine Learning funktioniert
Zunächst einmal wird zwischen Supervised und Unsupervised Learning unterschieden. Entweder überlässt man es der Maschine, Muster in Daten zu finden. Oder man gibt der Maschine vorab Trainingsmaterialien und sagt zum Beispiel, was gute und was schlechte Dokumente sind, damit die Maschine auf Basis des Gelernten in Zukunft bei neuen Dokumenten entscheiden kann, ob es ein gutes oder ein schlechtes Dokument ist.
Im Machine Learning wird häufig mit Distanzen gearbeitet, und das ist so ein zentrales Konzept, dass es genauer beleuchtet werden soll. Die folgenden Zeilen sind stark vereinfacht. Wir beginnen außerdem mit einem Unsupervised Learning-Beispiel, das in der Suchmaschinenwelt wahrscheinlich keine so große Rolle spielt, aber es zeigt das Konzept der Distanz auf eine sehr einfache Weise.
Stellen wir uns vor, wir haben eine Menge von Dokumenten, und für jedes Dokument sind Eigenschaften gemessen worden. Eine Eigenschaft ist zum Beispiel die Anzahl der Wörter in einem Dokument (X1), eine andere ist eine Maßzahl wie der stark vereinfachte PageRank der Domain, auf der das Dokument liegt (X2). Dies sind jetzt wirklich fiktive Werte, und es soll auf keinen Fall ausgesagt werden, dass es hier eine Korrelation gibt. Es geht nur um die Verdeutlichung.
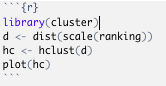
Zunächst werden die Werte auf diesselbe Skala gebracht (Befehl scale), danach wird eine Distanzmatrix erstellt (Befehl dist). Die Befehle für das Cluster werden später besprochen.
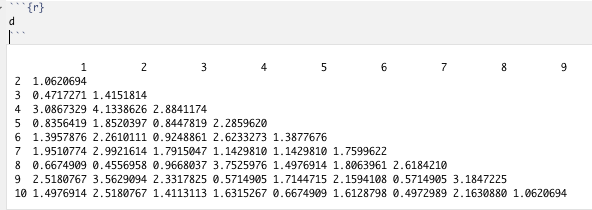
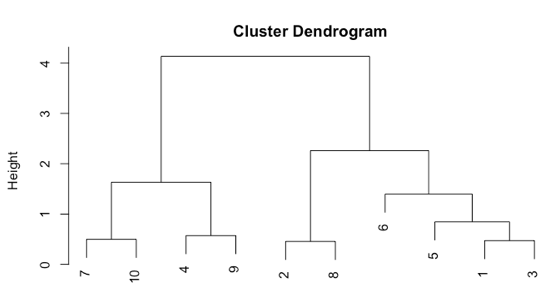
In der Distanzmatrix sind die Distanzen zwischen den einzelnen Reihen abgebildet. So ist der Abstand von Reihe 1 zu Reihe 3 geringer als der von Reihe 1 zu Reihe 4. Schaut man sich die Werte an, so sind diese Distanzberechnungen nachvollziehbar. Im nächsten Schritt werden daraus dann Cluster gebildet und diese in einem Dendrogramm geplottet:
Auch hier kann man gut nachvollziehen, warum die Werte aus den Reihen 7 und 10 eher zusammen gehören als die Werte aus Reihe 1 und 3. Die Maschine hat diese Cluster allein aus den Distanzen berechnen können.
Was haben Googles Human Quality Rater mit Machine Learning zu tun?
Nun gehen wir einen Schritt weiter. Wir wissen, dass Google Menschen Suchergebnisse beurteilen lässt, von highest zu lowest usw. Die Rater Guidelines sind einfach zu finden. Auch hier kommen wieder Distanzen ins Spiel, sobald “highest” eine Zahl bekommt und “lowest” und alle Werte dazwischen.
Natürlich können die Human Quality Rater nicht alle Suchergebnisse durchsehen. Stattdessen werden bestimmte “Regionen” trainiert, das heißt, dass die Bewertungen genutzt werden, um den Algorithmus für bestimmte Suchanfragen oder Signalkonstellationen optimieren zu lassen. Anders als im vorherigen Beispiel haben wir es hier mit Supervised Learning zu tun, denn wir haben eine Target Variable, das Rating. Gehen wir jetzt davon aus, dass mehr als 200 Faktoren für das Ranking verwendet werden, dann könnte man die Aufgabe für den Algorithmus so formulieren, dass er all diese Faktoren so anpassen muss, dass er auf das Target Rating kommt.
Um genauer zu verstehen, wie so etwas funktioniert, nehmen wir wieder ein stark vereinfachtes Beispiel, dieses Mal von einer Support Vector Machine.
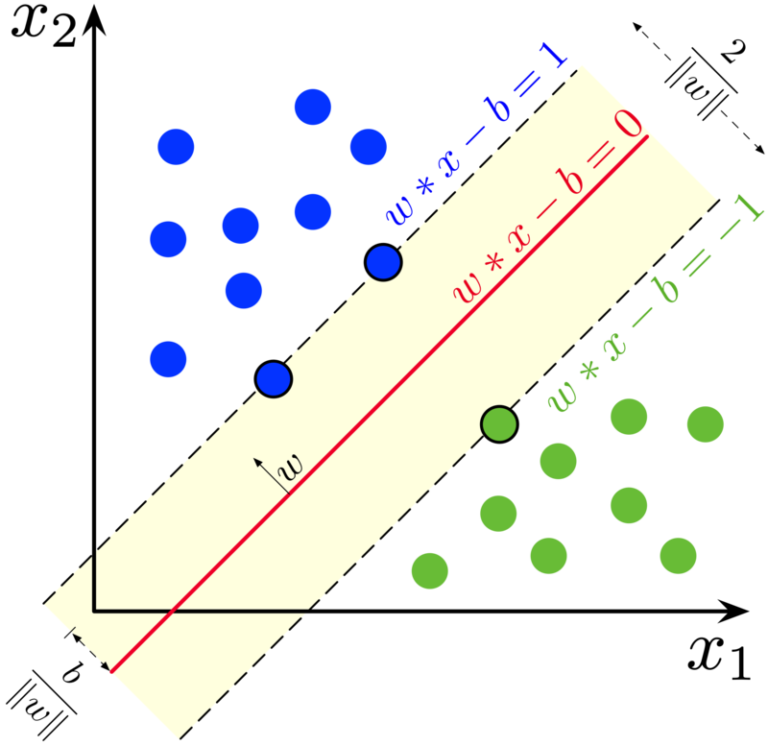
Das Prinzip der Support Vector Machines ist ein simpler, aber ziemlich durchdachter Ansatz, um die optimale Distanz zwischen zwei verschiedenen Segmenten zu berechnen. Nehmen wir im obigen Bild die rote Linie. Sie durchtrennt die blauen und die grünen Kreise. Sie könnte aber genau so gut ein paar Grad nach links oder rechts gedreht werden, und sie würde immer noch die beiden Segmente perfekt voneinander trennen. Und nun kommt der Trick: Um die optimale Trennung zu berechnen, wird die Linie einfach erweitert um zwei parallele Linien. Und der Winkel, bei dem die beiden Parallellinien am breitesten oder am weitesten voneinander entfernt sind, das ist der optimale Winkel für die rote Linie.
Nehmen wir nun an, die beiden Segmente sind wieder Signale aus dem Ranking, x1 ist der PageRank, x2 die PageSpeed. Die Daten werden hier in einem zweidimensionalen Raum geplottet, und man kann schön sehen, dass sie wunderbar voneinander getrennt sind. Wir könnten also unsere Maschine anhand dieser Daten trainieren und dann in Zukunft sagen, wenn neue Elemente in den Raum kommen, dass sie basierend auf dem Gelernten klassifiziert werden sollen. Und das funktioniert nicht nur mit 2 Variablen, sondern auch mit ganz vielen. Der Raum zwischen den Punkten wird dann Hyperplane genannt.
Nun sind Daten nicht immer so genau trennbar. Nehmen wir das Beispiel mit PageRank und PageSpeed. Nur weil eine Seite einen hohen PageRank hat, bedeutet das nicht, dass sie auch eine super Speed haben muss. Es könnte in dem Bild oben also auch vorkommen, dass ein paar grüne Kreise in den blauen sind und umgekehrt. Wie kann dann noch ein ein Trennbalken durch die Segmente berechnet werden? Ganz einfach: Für jeden Kreis, der sich nicht klar auf “seiner” Seite befindet, gibt es einen Minuspunkt. Und nun wird einfach berechnet, bei welchem Balken und seiner Lage die wenigsten Minuspunkte zustande kommen. Dies wird als “Loss Function” bezeichnet. Um es anders auszudrücken: Selbst “gute” Seiten könnten nach einer Support Vector Machine als “schlecht” klassifiziert werden, der Trick ist halt, sowenig gute Seiten wie möglich als schlecht zu klassifizieren und umgekehrt. Es ist halt unwahrscheinlich, dass alle “guten” Seiten dieselben Eigenschaften haben.
Was bedeutet das für Suchmaschinenoptimierer?
Zunächst einmal bedeutet es, was ich schon vor über einem Jahr auf der SEO Campixx-Konferenz gesagt habe, dass es keine statische Gewichtung gibt; das Ranking ist dynamisch. Bei Ask.com hatten wir einzelne Regionen trainiert, zum Beispiel wenn es keine Backlinks gab oder wenig Text oder bei Gesundheitssuchanfragen usw. No one size fits all. Uns stehen heute eben nicht alle 200 Signale zur Verfügung, um das Ranking pro Suchbegriff zu re-engineeren.
Gleichzeitig wird aber auch klar, warum manchmal Seiten abgestraft werden, die es eigentlich nicht verdient hätten. Es liegt nicht daran, dass sie für schlecht befunden worden wären, nur dummerweise haben sie zu viele Signale, die für ein schlechteres Ranking sprechen. Und da die Rater nicht bewusst nach irgendwelchen Signalen gesucht haben, hat der Algorithmus, sei es Support Vector Machines oder etwas anderes, halt selbst die Signale ausgewählt, die einen minimalen Loss bedeuten. Und da wir nicht alle 200 Signale haben, ist es für uns auch oft unmöglich nachzuvollziehen, was es genau gewesen sein kann. Man kann bei einem Re-engineering nur hoffen, dass unter den zur Verfügung stehenden Signalen schon etwas Brauchbares dabei ist.
Umso wichtiger ist die Beschäftigung mit den Quality Rater Guidelines. Woran machen die Rater Expertise, Trust und Authority fest? Was führt zur “highest” Bewertung? Auch wenn es langweilig ist, einen besseren Tipp kann man neben den Hygienefaktoren wahrscheinlich kaum geben.
Support Vector Machines wurden übrigens in den 60er Jahren entwickelt. Als von Data Science noch nicht die Rede war. Auch noch interessant sind die Ranking SVMs
Der Cold Song heißt eigentlich What Power art thou und ist eine Arie aus dem 3. Akt der Oper King Arthur von Henry Purcell. Das erste Mal wahrgenommen habe ich die Arie von Klaus Nomi, der sie kurz vor seinem Tod live aufnahm:
Eigentlich wird die Arie ein paar Oktaven tiefer gesungen, zum Beispiel so:
Es gibt auch eine wunderschöne Aufnahme mit deutschem Text von Nanette Scriba, wobei diese Aufzeichnung etwas verzerrt ist:
Eine etwas neuere Aufnahme stammt aus Deutschland von der Staatsoper Berlin, sehr langsam gespielt:
Eine Interpretation mit einer Kinderstimme:
Und zum Schluss eine etwas freiere Interpretation mit Steampunk-Charakter:
Zugabe (ich finde diese Version nicht so schön, aber es ist eben eine eigenwillige Interpretation der Sängerin):
Wenn man mit R automatisiert auf APIs zugreifen will, dann ist die Authoritisierung via Browser keine Option. Die Lösung nennt sich Service User: Mit einem Service User und dem dazu gehörenden JSON-File kann ein R-Programm auf die Google Analytics API, die Google Search Console API, aber auch all die anderen wunderbaren Machine Learning APIs zugreifen Dieses kurze Tutorial zeigt, was für die Anbindung an die Google Search Console getan werden muss.
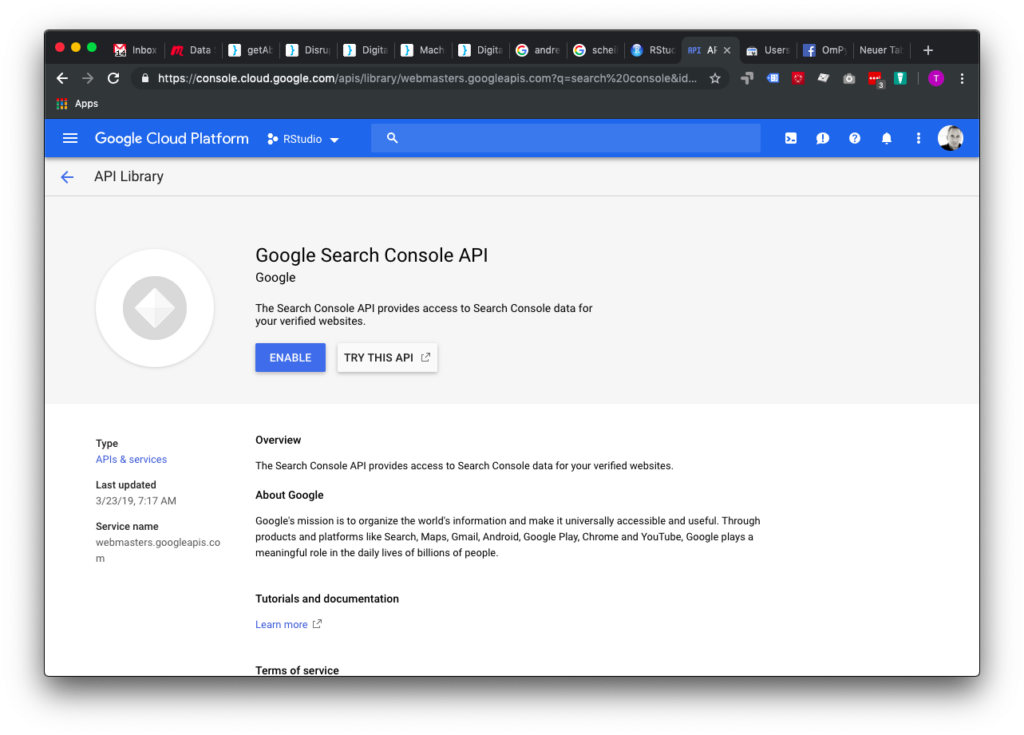
Zunächst legt man ein Projekt an, wenn man noch kein Passendes hat, und dann müssen die passenden APIs enabled werden. Nach einer kurzen Suche findet man die Google Search Console API, die nur noch aktiviert werden muss.
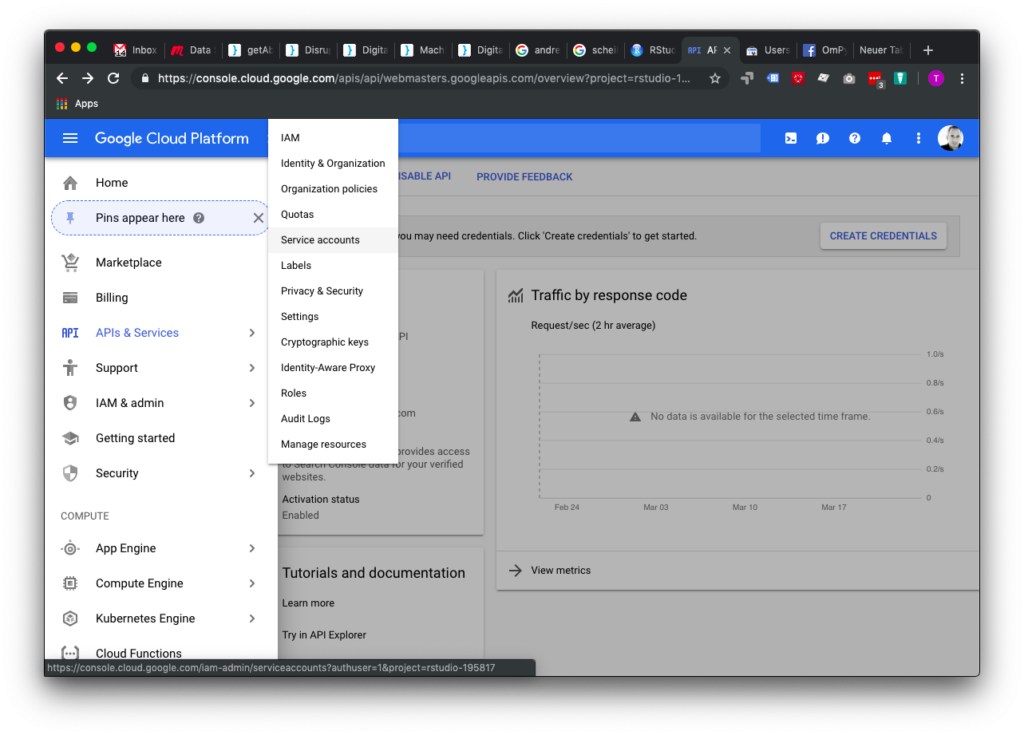
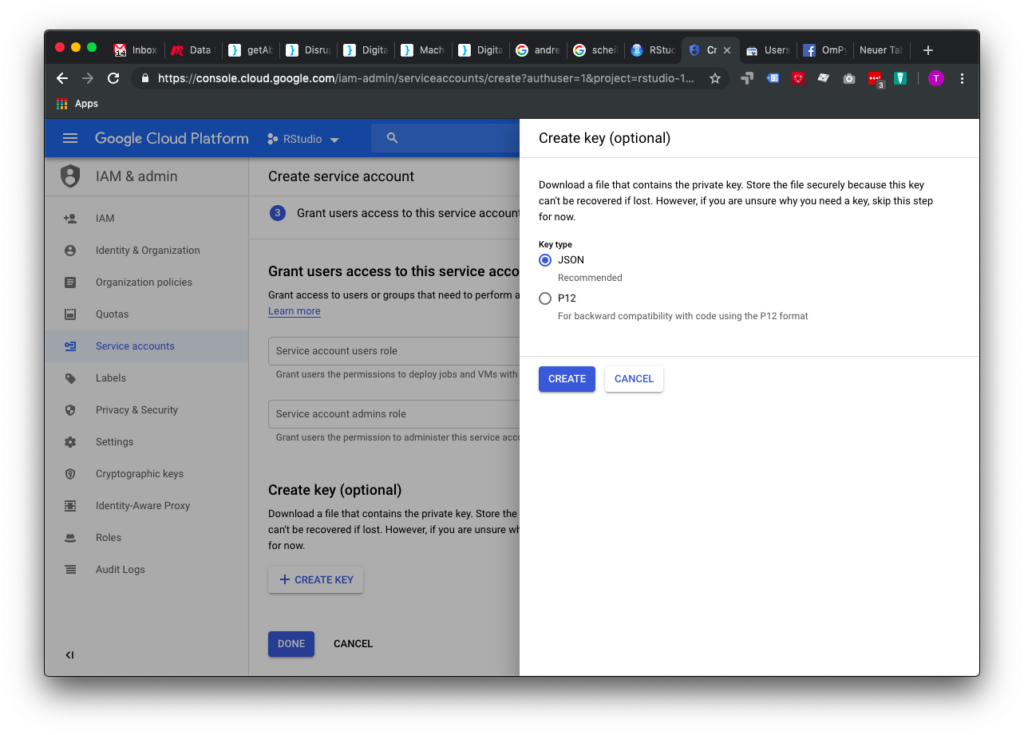
Auf IAM & admin klicken und dann auf Sevice accounts (ist irgendwie seltsam gehighlighted in diesem Screenshot:
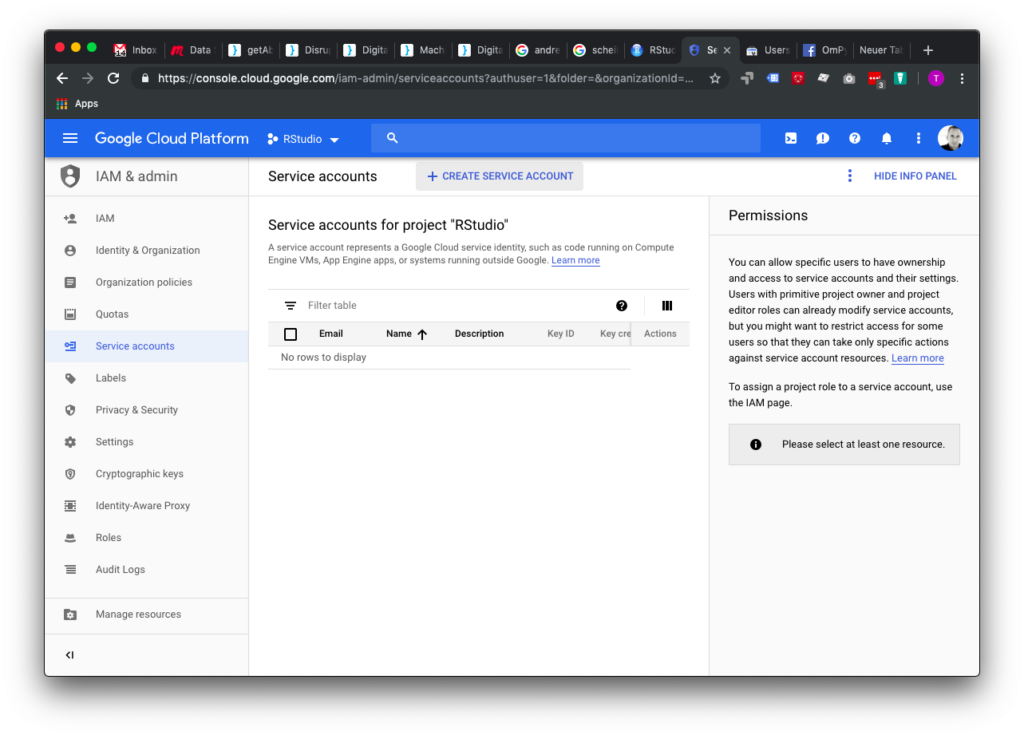
Auf Create Service Account klicken:
Wichtig: Einen sinnvollen Namen geben für die Mail-Adresse, damit man wenigstens etwas die Übersicht behält…
Browse Project reicht bei diesem Schritt:
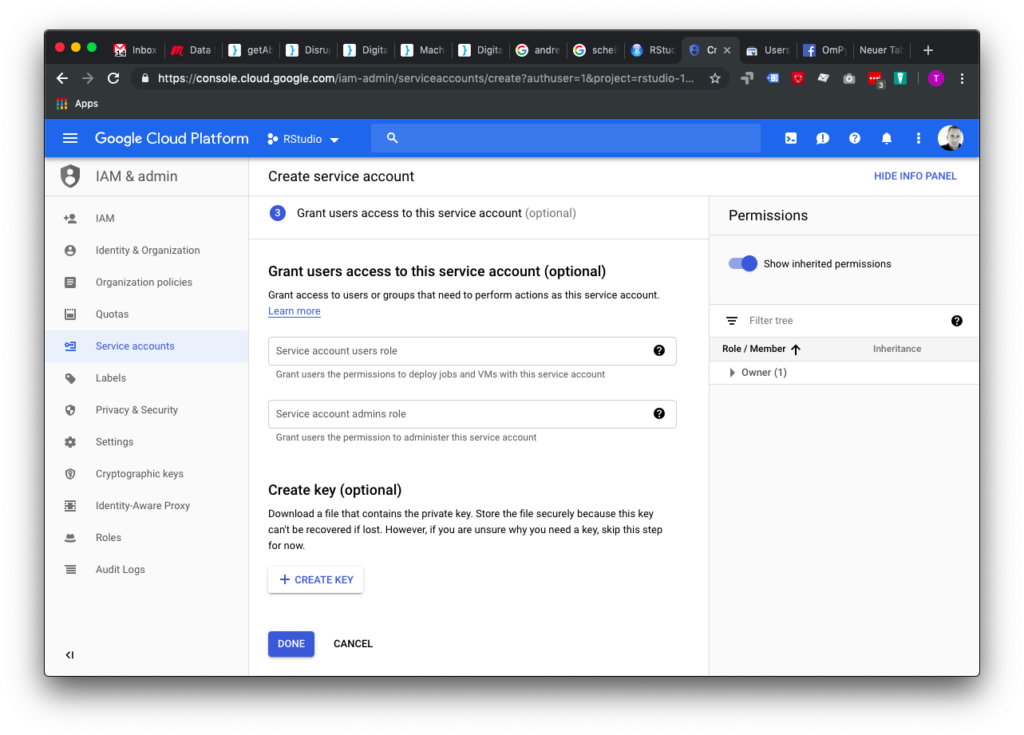
Hier auf “Create Key” klicken:
JSON-Key erstellen, runterladen und dann in das gewünschte RStudio-Verzeichnis legen.
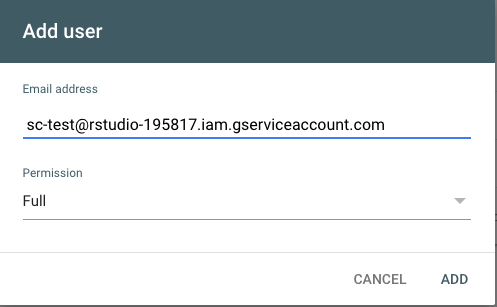
Nun muss der Service User noch als User in der Search Console hinzugefügt werden; wichtig ist, dass er alle Rechte erhält.
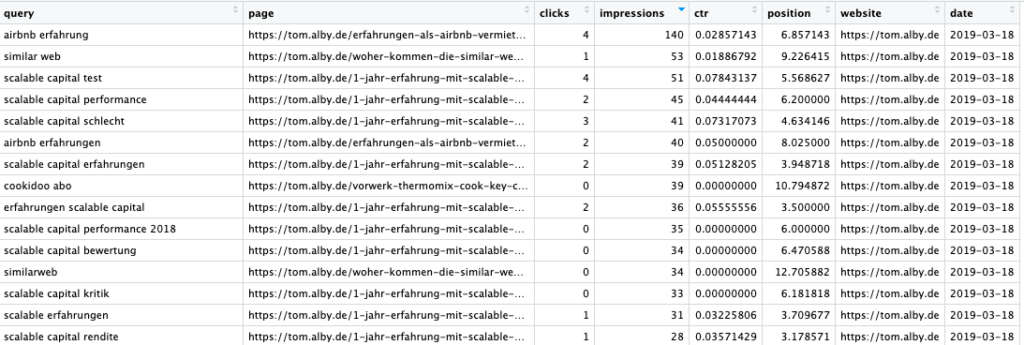
Was wirklich toll ist an der Google Search Console API: Man sieht Query und Landing Page gleichzeitig, anders als in der GUI. Ich hole mir die Daten übrigens jeden Tag und schreibe sie in eine Datenbank, so dass ich eine schöne Historie habe, die über die paar Monate der Search Console hinausgehen.
Zu guter Letzt stelle ich auch noch das R Notebook zur Verfügung, mit dem ich die Daten abfrage; es ist grundsätzlich der Code, den der Autor der API, Mark Edmondson, geschrieben hat, aber nur der Vollständigkeit halber, wie die JSON-Datei eingebunden wird. Es gibt noch eine elegantere Variante mit R Environment Variablen, aber ich weiß nicht, ob die unter Windows funktioniert.
Ich habe den Sinn eines bestimmten Diagramms in Google Analytics nie verstanden, und zwar den des Tortendiagramms, das das Verhältnis der neuen Nutzer zu den wiederkehrenden Nutzern zeigt. Es war früher im Standard-Dashboard, das ein Nutzer nach dem Login sah, und ich hatte mich immer für dieses Diagramm entschuldigt, wenn ich während meiner Zeit bei Google eine Google Analytics-Demo gezeigt hatte.
Tortendiagramm: Nur für statische Zusammensetzungen
Was ist so schlimm an diesem Diagramm? Zunächst einmal wird ein Tortendiagramm für statische Zusammenstellungen verwendet. Wenn ich wissen möchte, wie die Geschlechteraufteilung meines Kurses ist, dann ergibt ein Tortendiagramm Sinn. Die Geschlechter werden sich größtenteils nicht ändern während des Kurses.
Die meisten Webseiten wollen aber die Anzahl ihrer Besucher erhöhen, sei es durch neue Nutzer, wiederkehrende Nutzer oder beides. Eine Entwicklung ist also das Ziel, und somit ist ein Tortendiagramm nicht sinnvoll, da es ja statische Konstellationen zeigt. Ein Liniendiagramm, das die Entwicklung über die Zeit zeigt, ist in den meisten Fällen sicherlich eine bessere Wahl.
Die beiden Metriken sind unabhängig voneinander
Ich gehe jetzt aber noch einen Schritt weiter und behaupte, dass diese beiden Metriken nichts miteinander zu tun haben und deswegen auch nie in einem Diagramm dargestellt werden sollten. Neue Benutzer können wiederkehrende Nutzer werden, müssen es aber nicht. Und wiederkehrende Nutzer können in dem gleichen Zeitraum auch neue Nutzer gewesen sein, sie werden dann zwei Mal gezählt. Wenn ein Nutzer also in beiden Teilen des Tortendiagramms auftauchen kann, was sagt das Verhältnis der beiden Teile zueinander dann aus?
Neue Nutzer entstehen durch Marketing. Idealerweise kommen wiederkehrende Nutzer dadurch zustande, dass die Inhalte so toll sind, dass die Nutzer nicht mehr ohne sie leben wollen. Wenn ich keine neuen Nutzer bekomme, dann muss ich mein Marketing optimieren. Wenn meine Nutzer nicht wiederkehren, dann muss ich meine Inhalte optimieren. Da wir immer auf der Jagd nach sogenannten “Actionable Insights” sind, warum sollten wir dann zwei Metriken in einem Diagramm darstellen, wenn sie unterschiedliche korrigierende Maßnahmen erfordern?
Außerdem: Ich kann zwei Wochen lang viel Geld für Marketing ausgeben, so dass sich der Anteil neuer Nutzer massiv erhöht und der Anteil wiederkehrender Nutzer in der Ratio dadurch stark verringert. Selbst wenn die absolute Zahl wiederkehrender Nutzer gleich bleibt, würde die Ratio uns vermitteln, dass wir weniger wiederkehrende Nutzer hätten. Aus diesem Grund sollten diese beiden Metriken nie zusammen als Ratio, sondern stets getrennt angezeigt werden. Serviervorschlag: Ein Graph mit der Entwicklung der neuen Nutzer mit den Akquisekanälen, ein Graph mit den wiederkehrenden Nutzern und den Inhalten, die für die Wiederkehr verantwortlich sein könnten.
Was ist eigentlich mit den nicht-wiederkehrenden Nutzern?
Diese Frage stellte heute eine Kursteilnehmerin, und diese Frage finde ich aus mehreren Gründen gut. Wir wissen nicht, ob neue Nutzer wiederkehrende Nutzer sein werden (abgesehen von denjenigen neuen Nutzern, die in unserem Zeitraum neu als auch wiederkehrend sind, weil sie 2 Mal kamen, aber sie könnten sich natürlich in der Zukunft gegen einen weiteren Besuch entscheiden). Insofern könnte jeder Nutzer, der einmal dagewesen ist, irgendwann einmal in der Zukunft wiederkommen. Technisch gesehen kann kein Nutzer, der seine Cookies gelöscht hat, als wiederkehrender Nutzer bei uns wieder auftauchen, von User ID-Gebrauch einmal abgesehen. Aber dennoch finde ich die Frage spannend, da ich mich in einem anderen Kontext mit ihr beschäftigt habe: Ab wann muss ich einen Kunden bei einem Produkt, das regelmäßig gekauft wird, als verloren ansehen?
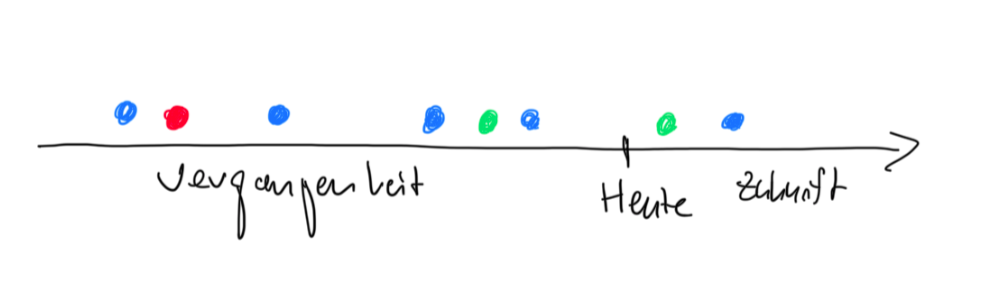
Die Grafik soll meine Gedanken dazu verdeutlichen. Wir haben einen Punkt “Heute” und drei Nutzer, blau, rot und grün. Nutzer blau kommt in mehr oder weniger regelmäßigen Abständen vorbei. Bei dem Zeitpunkt “Heute” würde ich davon ausgehen, dass er auch in Zukunft wiederkommt, zumindest scheint die Wahrscheinlichkeit hoch zu sein. Nutzer grün war erst vor kurzem da. Er hatte vielleicht keine Chance, wiederzukommen. Nutzer rot war vor langer Zeit da, und verglichen mit den Zeitabständen, die Nutzer blau zwischen seinen Käufen hat, scheint die Wahrscheinlichkeit einer Wiederkehr gering zu sein. Er kann wiederkommen, aber ihn würde ich eher mit einem Incentive anlocken als Nutzer grün, der eventuell eh wiederkommen wird (pull-forward cannibalization).
Wir können also nichts Genaues über nicht-wiederkehrende Nutzer sagen, denn wir kennen die Zukunft nicht. Aber wir können mit Wahrscheinlichkeiten rechnen. Bei reinen Nutzern eventuell nicht so spannend. Aber bei Shop-Kunden schon spannender.
Ich habe in den letzten Wochen viel Zeit damit verbracht, unterschiedliche NAS-Konfigurationen zu testen. Kurzgefasst: Es lohnt sich nicht, eine NAS von QNAP oder Synology zu kaufen. Von meinen WD-Ausflügen will ich schon gar nicht mehr erzählen. Für alle diese Kaufsysteme gilt: Die Performance ist unterirdisch, die Sicherheit bedenklich, und überteuert sind diese Systeme auch. Die in diesem Artikel beschriebene Open Source-Lösung kann für sehr viel weniger Geld mehr Sicherheit und Geschwindigkeit bringen. Warum überhaupt eine eigene Cloud, das erklärt dieser Artikel sehr gut.
nextcloudPi
nextcloudPi ist ein wunderbares Projekt, das eine einfache Installation von nextcloud auf einem Single Board Computer ermöglicht, inklusive Memory-Cache (Redis) und SSL-Zertifikat. Single Board Computer sind kleine Mini-Computer wie der Raspberry Pi, die ab 30€ kosten und dennoch beachtliche Dinge leisten können. Die Installation von nextcloudPi ist wie gesagt einfach, aber noch nicht auf dem Stand, den ein DAU unfallfrei hinbekommen würde. Man kann schon ohne Kommandozeile das ganze System installieren und konfigurieren. Nur manche Begriffe wie dnsmasq sind eben nicht selbsterklärend. Vergleicht man diese Installationsroutine aber mit den Installationsanweisungen von Seafile, dann ist nextcloudPi ein Musterbeispiel dafür, wie man aus etwas Kompliziertem etwas Einfaches machen kann. Seafile ist ein kryptisches Monster, was die Installation betrifft, und das schreibe ich als Informatiker.
An nextcloud gefällt mir, dass anders als bei owncloud kein Geld für die Mobile App verlangt wird und das System irgendwie moderner, flüssiger wirkt. Die App ermöglicht auch, dass Fotos von meinem Handy direkt in meiner Cloud landen und nicht bei Google & Co. Ein Selbstläufer ist es aber in der Regel nicht, da eine bestimmte PHP-Konfiguration benötigt wird, und so einen Memory-Cache installiert man halt auch nicht jeden Tag. All das übernimmt die Installations-Routine von nextcloudPi. Entwickelt wird das von nachoparker:
Odroid XU4 anstatt Raspberry Pi
Der Raspberry Pi hatte sich überraschenderweise sehr gut geschlagen mit der nextcloud-Installation, besser als nextcloud auf der synology oder auf der QNAP. Der Raspberry 3 B+ hat nur einen großen Nachteil, USB (wo die Festplatte dran hängt) und Ethernet hängen am gleichen Bus, und da der Raspberry eh nur mit 100 MBit-Ethernet ausgestattet ist, wird das Schreiben und Lesen nicht gerade schneller, wenn die Festplatte da auch noch dran hängt. 1 GB Arbeitsspeicher ist auch nicht besonders viel.
Nach viel Recherche fiel meine Wahl auf den Odroid XU4 mit 2 GB RAM und 8 (!) Kernen, nachdem ich lange mit dem RockPro64 geliebäugelt hatte (4 GB RAM!). Der XU4 kostet um die 100€, mit Netzteil, Flashspeicher etc zahlt man etwas mehr als 120€. Bei dem RockPro64 gab es zu viele Foreneinträge, welches Betriebssystem welche Probleme macht.
Die Einkaufsliste
Wahrscheinlich kann man die Komponenten irgendwo günstiger kaufen, aber da es bei mir schnell gehen musste, habe ich die folgenden Komponenten genommen:
SanDisk SSD 1 TB für 129€ (Affiliate-Link); natürlich kann man auch eine bestehende Festplatte nehmen, dann bitte den passenden Adapter besorgen
Benötigt wird außerdem ein dynamischer DNS-Dienst, der bei wechselnder eigener IP-Adresse zuhause die Erreichbarkeit von außen unter der gleichen Subdomain ermöglicht; ich habe gute Erfahrungen mit no-ip.com gemacht.
In dem Odroid-Paket ist bereits ein MicroSD-Adapter für die eMMC-Karte enthalten, es wird dann noch ein Adapter für die MicroSD-Karte benötigt, um die eMMC-Karte flashen zu können. Den habe ich nicht in meiner Kostenübersicht einbezogen. Eine eMMC-Karte ist ein extrem schneller Speicher, Fingernagel-groß, der direkt auf den Single Board Computer gesteckt wird.
Die Installation
Zunächst muss das passende System von der nextcloudPi-Seite heruntergeladen werden. Ich wollte Armbian nehmen, da damit schließlich auch andere Sachen möglich gewesen wären, aber damit habe ich die SSD nicht am USB 3.0-Anschluss zum Laufen bekommen. Mit dem Image für das Odroid-Board war das kein Problem. Mit Etcher wird dieses Image dann auf die eMMC geflasht, das dauert ca. 5 Minuten. Und dann kann man die eMMC-Karte auf den Odroid stecken, Ethernet anschließen, den Strom einstöpseln und den kleinen Computer booten. Ich hatte auf das Anschließen eines Monitors verzichtet und einfach im Netz geschaut, welche IP-Adresse der Rechner bekommt. Übrigens keine so schlaue Idee von mir, denn irgendwann will man schon noch per SSH auf den Rechner zugreifen können.
Mit https://:4443/wizard kommt man auf die Installations-Oberfläche, die durch die Installation führt. Irgendwann wird man aufgefordert, sein USB-Laufwerk einzustöpseln, das dann automatisch gemountet und optional auch formatiert wird. Insgesamt ist man nach maximal 30 Minuten fertig, inklusive Auspacken und Zusammenstöpseln.
Die Geschwindigkeit ist der Hammer. Egal ob zuhause im Netzwerk oder draußen, das Ding ist schnell, gefühlt sogar schneller als Dropbox oder Google Drive. Aber was noch wichtiger ist, ich habe meine Daten zuhause (natürlich muss ich dann noch irgendwas aufsetzen, damit ich irgendwo ein verschlüsseltes Backup meiner privaten Cloud in der Cloud habe). Man kann sich natürlich fragen, ob Dropbox oder Google Drive dann nicht doch viel günstiger sind, wenn sie nur 10€ pro Monat für ein TeraByte kosten. Ich brauche mehr als 2 Jahre, um die Kosten reinzuholen. Aber, noch mal, ich habe meine Daten jetzt zuhause und nicht irgendwo. Und schneller ist es halt auch.
Die Konfiguration
Noch ein paar Worte zur Konfiguration. Natürlich aktiviert man 2-Faktor-Autorisierung. Außerdem würde ich dringend dazu raten, im nextcloudPi-Konfigurationspanel dnsmasq zu aktivieren und den DNS-Server des eigenen Rechners auf die IP des Odroid einzustellen. Dadurch können in den Logdateien die einzelnen Rechner im Netzwerk voneinander unterschieden werden.
Als Nutzer legt man für sich selbst einen Standard-Nutzer an, der nicht Admin ist.
Ich habe die Festplatte nicht verschlüsselt. Verschlüsselung drückt die Perfomance und benötigt auch mehr Plattenplatz, aber ich habe mir vor allem darum Sorgen gemacht, dass ich die Schlüssel verliere. Vielleicht hole ich das aber auch irgendwann noch mal nach. Nur geht das dann nur mit neuen Dateien, nicht mit einem bestehenden Set.
Übrigens, auch wenn die Zugangs-URL eine Domain ist, wird im eigenen Heimnetzwerk auch nur lokal kommuniziert. Es wird also nicht der Umweg über das Internet gegangen, auch wenn das vielleicht so aussieht.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Sascha says
Juli 2019 at 04:48 Klingt mega interessant, da mein RaspberryPi 3 echt suboptimal ist… hast du mal den Odroid N2 ausprobiert oder meinst du generell der lohnt sich? Wie genau muss ich das installieren? Also Armbian konntest du nicht nehmen, weil die SSD dann nicht geht? Lag es speziell an der SSD oder wird das allgemein so sein? Ich bin kein Profi und finde keine Anleitung. Welches Image genau von wo muss nun geflasht werden? https://ownyourbits.com/nextcloudpi/#download ich weiß, dass hier alles erhältlich ist und würde eigentlich gerne Docker benutzen und wenn das geht dazu PiHole eben. Das scheint generell alles etwas komplizierter zu sein als beim RaspberryPi. Ich wüsste nicht mal gerade wie man SSH einschaltet. Aber ist ja alles eine einmalige Sache. Kannst du mir da Auskunft geben? Vielen Dank und lieben Gruß!
Tom Alby says
Juli 2019 at 12:09 Soweit ich das sehen kann wird der N2 noch nicht unterstützt. Vielleicht gehst Du mal in die Telegram-Gruppe des Entwicklers und fragst dort nach. Im Prinzip wäre der neue Raspberry 4 ja auch ein guter Kandidat mit seinen 4 GB RAM. Aber auch da sehe ich noch keine Unterstützung.
Ich habe nicht genug Zeit mit der Fehlersuche des USB-Ports und der SSD verbracht. Meine Erfahrung ist, dass man mit sowas unglaublich viel Zeit verbraten kann, und genau das wollte ich eben nicht mehr tun. Flashen tust Du normalerweise ein Image auf eine SD-Karte o.ä., von der Du booten willst. Wegen Docker: https://hub.docker.com/r/ownyourbits/nextcloudpi-armhf
Sascha says
Juli 2019 at 17:33 Hey Tom, danke dir für deine Antwort. Ich befinde mich bereits in der Telegram Gruppe zu NextCloudPi. Habe mir jetzt den N2 bestellt. Das Problem bei dem Gerät ist, das kein offizielles Armbian existiert (jedenfalls momentan) und man NCP nur über Docker installieren kann und damit auf das BTRFS Feature verzichten muss. Für den Raspberry Pi 4 existiert seit gestern ein Image. Ich werde nun eine eMMC mit vorgefertigtem Linux erhalten und muss doch deshalb wahrscheinlich gar nichts flashen oder sehe ich das falsch? Nach dem NCP Entwickler gibt es keinen logischen Grund an einem Raspberry Pi festzuhalten, da er eben in allen Ebenen unterlegen ist. Meinst du denn, dass es sinnvoll ist eine SSD somit quasi als NAS zu nutzen? Habe gerade meine Zweifel daran. Klar ist der Speed super, aber nicht dass die Daten von heut‘ auf morgen weg sind. Naja mal schauen dann. Denke aber der N2 wird gut laufen.
Tom Alby says
Juli 2019 at 11:43 Egal ob SSD oder HDD, eine Platte kann immer kaputt gehen. Entweder RAID oder täglich Snapshots woanders sichern. Ich gehe sogar so weit, dass ich verschlüsselte Snapshots in der Cloud sicher.
Lutz says
August 2019 at 15:48 Hallo Herr Alby, danke für die Publikation Ihrer Erfahrungen und sicherlich haben Sie sehr profundes IT-Wissen, jedenfalls mehr als ich. Dennoch: ich denke (bis jetzt) dass, wenn man die Capex nicht als limitierenden Faktor alleine setzt, gibt es vermutlich auch leistungsfähige NAS bei z.B. Synology. Laut deren White-Papers (habe ich nch nicht proboert, da ich dafür sicher mehr Zeit investieren muss als Sie) müsste eine Art Ende zu Ende Verschlüsselung beim Upload in die Cloud nutzbar sein. Ich habe mir meinen Router „dicht“ gemacht und keine weiteren offenen Ports offen (z.B. 5000 und 5001 usw.) statt dessen gehe ich via IPSEC IKVE2 auf den Router von außen, das sollte m.E. auch soweit sicher sein. Meine Bauchgrummel-Gefühle kommen von hier: 1.) Ich kenne keine ernst zu nehmende externe Cloud die via VPN ansprechbar ist. Nur prperitäre Lösungen mit Ende zu ende Ecryption und die lassen sich z.B. meines Wissens nicht mit einer Synology verbinden. Also wird das nichts richtiges. 2.) Wie kann man rausbekommen, ob es in der Synology-Welt der Encryption-Lösung eine Backdor gibt? Frage: M.E. müsste es sicher genug sein (100% ist wohl illosorisch, aber wenn sich Geheimdienste für einen mit ihren Budgets interessieren darf man sich wohl „von“ schreiben oder hat was falsch gemacht) Wenn z.B. keine Back-Door vorhanden ist und die Pre-Encryptete Datei via SSL auf z.B. Onedrive von MS abgelegt ist, oder Google Drive o.ä.
Tom Alby says
August 2019 at 19:04 Sicherlich gibt es für mehr Geld leistungsfähigere Hardware, sowohl von QNAP als auch von Synology. Für mich zeigt das NextCloudPi-Projekt aber, dass man mit wenig Aufwand und wenig Geld eine hochperformante Lösung erhält, die auch noch als Open Source verfügbar ist (und da können Sie ja nachprüfen, ob es eine Backdoor gibt). Und jetzt mit dem Raspberry Pi 4…
Auch brauche ich ja kein VPN zu einer externen Cloud, wenn ich meine Sachen da schon verschlüsselt ablege…?
Jan says
August 2019 at 09:23 Hallo Tom,
habe soeben zwei deiner Berichte gelesen, da ich mich die Tage ebenfalls mit einer eigenen Cloud beschäftigt habe.
Die Entscheidung viel bei mir zuletzt auf einen Ordoird HC1, fürs OS habe ich eine Standard MircroSD mit V30 Standard verwendet. Die HC1 / HC2 verwenden angeblich ebenfalls die XU Hardware in einer für NAS/Cloud reduzierten Variante.
Die Installation wurde bei mir über Ubuntu 18.04 von Hand aufgesetzt was mich in Summe inkl. Trial-Error Szenarien zwei Tage gekostet hat. Daher klingt es für mich sehr interessant dass es bei Dir innerhalb 30 Minuten mit dem NextcloudPi Image so reibungslos funktioniert hat. Das muss ich dann in kürze noch im zweiten Bastelprojekt verwenden. Mein nächstes Ziel wäre eine Nextcloudlösung inkl. Backup / RAID, mal schauen was dabei rauskommt.
Beste Grüße, Jan
Markus G. says
September 2019 at 21:16 Hallo Tom,
kannst Du uns schon etwas sagen, wie die Performance und Stabilität Deiner Home NAS läuft, bist Du bisher zufrieden oder gab es irgendwelche Probleme im Laufe der Betriebszeit?
Würde gerne so ein Projekt in Angriff nehmen.
Danke und viele Grüße Markus
Tom Alby says
September 2019 at 21:21 Ich bin superglücklich mit der Lösung. Zwischendurch gab es mal ein Problem mit dem Let’s encrypt-Zertifikat, aber auch das hab ich irgendwie gelöst bekommen.
Christian says
Oktober 2019 at 00:01 Hallo Tom, Würden sie empfehlen auf den Rasperry Pi 4 zu setzen, oder lohnt sich der Mehrpreis mit dem Odroid XU4-Set? Ich bin jetzt in dem Thema Einplatinen-Rechner nicht so bewandert und hatte mich nur gefragt ob die 4 GB Ram einen Vorteil bieten. Bei so einer Investition zahle ich aber lieber etwas mehr, wenn es sich lohnt von der Performance. Nutzen sie die Nextcloud App auf ihren mobilen Geräten auch unterwegs?
Tom Alby says
Oktober 2019 at 09:09 Gute Frage. Ich hab den neuen Raspberry noch nicht ausprobiert und kenne auch keinen Benchmark. Ja, ich nutze die Mobile Apps dazu.
Maik says
Oktober 2019 at 15:41 Hallo Tom, leider habe ich deine Beiträge zum Thema einer eigenen Cloud gerade erst jetzt gefunden. Ich habe mich in den letzten Tagen erheblich mit Owncloud und QNAP abgemüht. Alles, was da im Original angeboten wird, ist leider nicht mehr up-to-date. Allerdings würde auch mein NAS (TS-221) sicher als akzeptable Hardware ausscheiden. Nun bin ich am Nachdenken, Folgendes zu realisieren: Ich habe hier noch 2 Pi 3B+ rumliegen, die ich für nichts nutze. Ich würde gern auf einem von denen die NextCloudPi realisieren, den Speicher für die Dateien allerdings auf mein NAS legen (irgendwie mounten), da dort noch soooo viel Platz ist. Geht das denn auch irgendwie? (Man hört vielleicht, dass ich nicht so der Linux/Unix-Crack bin)
Oktober 2019 at 23:43 Hallo Tom, Ich habe mir auf einem Odroid N2 mit Debian buster Nextcloud eingerichtet. Die Daten werden auf zwei 1TB SSDs im Raid 1 gespeichert. Hast du auch Probleme mit Dateien mit deutschen Umlauten? Ich wollte gerade meine PDFs aus dem Studium hochladen aber habe einige Dateien die Probleme machen. Ich habe einiges gelernt bei diesem Projekt. Danke für die Empfehlung. viele Grüße Christian
Tom Alby says
Oktober 2019 at 09:08 Hey Christian,
nein, keine Probleme mit Umlauten. Ich hoffe, Du bekommst das Problem gelöst.
Beste Grüße
Tom
Nico says
November 2019 at 17:46 Hi Tom,
Danke für Deinen Beitrag, das klingt ganz nach etwas, das ich schon lange gesucht habe Darf ich nachfragen, welche Bandbreite Dein Upload für das von dir oben beschriebene System hat? Dass Du schreibst, gleich schnell/schneller als GDrive ist ja schon eine Aussage, da wollte ich nur mal nachfragen, ob du als IT Spezialist auf einer Gigabit Leitung sitzt
Gerhard Treisbach says
November 2019 at 12:55 Hallo Tom,
nachdem ich Deinen Artikel gefunden habe, habe ich mir die von Dir empfohlene Hardware (ODROID-XU4) über Deine Links bestellt.
Mit einem Original Ubuntu MATE Image von odroid.com bekomme ich das Teil auch problemlos zum Laufen, aber sowie ich versuche, das Image von deinem Link (NextCloudPi_OdroidHC2_08-01-19 ) zu installieren, bleibt der ODROID beim Booten einfach stehen. Keine Bildschirmausgabe und auch keine zugewiesene IP Adresse.
Kannst Du noch irgendwie rausfinden, welche Version das NextCloudPI Image hatte, dass Du damals verwendest hast und mit dem alles auf Anhieb lief?
Liebe Grüße Gerhard
Chillbird says
November 2019 at 16:02 Hallo Tom,
super Artikel und die Zeit die du damit „verschwendet“ hast, koennen sich Leser wie ich dann dafuer ersparen. Vielen Dank! Ich wuerde mich sehr ueber ein Update freuen, vorallem wenn Du die automatisierte E2EE Backupfunktion in die Cloud realisiert hast. Um das System perfekt zu machen, koennte man statt der einzelnen Platte dann auch einen Hardware RAID Array dranhaengen (zb den um 100 Euro: FANTEC QB-35US3-6G), vielleicht gibt es sogar Hardware Encryption+RAID Loesungen?
Hast du sowas wie einen Newsletter? Wenn ja, melde ich mich hiermit an
Danke und alles Gute weiterhin, Chillbird
Gabi says
Januar 2020 at 04:00 „Übrigens, auch wenn die Zugangs-URL eine Domain ist, wird im eigenen Heimnetzwerk auch nur lokal kommuniziert. Es wird also nicht der Umweg über das Internet gegangen, auch wenn das vielleicht so aussieht.“
Wie machst du das? Ich versuche dasselbe, aber bei mir stellt sich die Fritzbox quer…
Mirko says
Januar 2020 at 16:16 Hallo Tom,
es gibt eventuell ein Problem mit Boards der Revision 0.1 20180912 . Die Teile booten nicht mit dem aktuellen NextCloudPi Image vom Januar 2020. Gerhard Treisbach hatte das gleiche Problem. Ich habe versucht Armbian zu installieren, habe aber das gleiche Problem. Ubuntu Mate läuft problemlos.
Viele Grüße
Mirko
Tobias says
Januar 2020 at 08:43 Hallo Mirko,
mit welcher Revision läuft dann Nextcloudpi image. Mit den älterenen oder den neueren. Würde mich interessieren, da ich mir auch gerade ein NAS aufbauen möchte.
Gruß Tobias
Gerhard Treisbach says
Januar 2020 at 16:49 Hallo, hier noch mal Gerhard,
ich habe das Problem mit dem nicht bootenden XU-4 gelöst bekommen, hier mal der Link zu dem entsprechenden Thread im NextcloudPi Support Forum:
Vorab: Ich war ein großer Verehrer der Achim Freyer-Inszenierung der Zauberflöte an der Hamburgischen Staatsoper, die bei ihrer Premiere 1982 neben Applaus auch Buhrufe bekam. Diese Inszenierung war aufgrund ihrer Verspieltheit nach über 30 Jahren gefühlt immer noch modern, und ich habe sie bestimmt ein Dutzend Mal gesehen. Die Interpretation, dass Tamino alles geträumt haben könnte und sich deswegen zum Schluß selbst beobachten kann, fand ich zwar stets eigenwillig, aber die Bilder Freyers waren einfach wunderschön.
Die Zauberflöte hat für die Hamburgische Staatsoper vielleicht eine besondere Bedeutung, schließlich war sie das erste Stück, das 1955 nach dem Wiederaufbau des Opernhauses gegeben wurde. Zudem existiert eine DVD mit einer von Peter Ustinov in den 60er Jahren in Hamburg inszenierten Aufführung, die wahrscheinlich die Brücke zwischen der Wiedereröffnung und der Freyer-Inszenierung bildete.
Und auch für mich hat die Zauberflöte eine besondere Bedeutung. Jedes Mal, wenn ich mich mit ihr beschäftige, entdecke ich etwas Neues darin. Und sobald ich die Möglichkeit habe, eine Inszenierung zu sehen, versuche ich alles dafür zu tun, diese Möglichkeit Realität werden zu lassen. Ich habe schon einige Inszenierungen gesehen, von einer ganz klassischen in der Semper-Oper über eine wunderbare Produktion der HfMT bis zu einer John Dew-Inszenierung in Bielefeld, wo er den Tempel Sarastros in ein Computerlabor verwandelte.
Buhrufe wie die Freyer-Produktion bekam 34 Jahre später auch die neue Inszenierung von Jette Steckel. Wahrscheinlich hätte jede neue Inszenierung zu Buhrufen geführt, denn schließlich hatte man die alte Inszenierung liebgewonnen, sie war ein steter Begleiter durch viele Jahre. Jette Steckel hatte es also nicht einfach. Und ich habe zwei Jahre gebraucht, um mich in die neue Inszenierung zu wagen. Die Licht-Installationen sind faszinierend und stimmten mich zunächst mehr als versöhnlich, doch gleich zu Beginn fand ich das verkürzte Libretto verstörend. Kein Wunder, dass die Staatsoper in drei Stunden fertig sein wollte (am Ende war es sogar eine Viertelstunde weniger), und das trotz Pause. Am Text wurde einiges gekürzt, und wenn ich mich richtig erinnere, dann auch an der ersten Arie (“Zu Hilfe”).
Kein Schwarz oder Weiß, kein eindeutiges Gut oder Böse
Und so stehen die Musik und die visuelle Inszenierung im Vordergrund, denn vom Text blieb nicht viel übrig. Stattdessen wurde ein wenig neuer Text hinzugefügt, der zur Anbiederung an das junge Publikum passte. Natürlich darf eine Inszenierung attraktiv für neue Operngänger sein. Vielleicht verlässt man sich aber auch zu sehr darauf, dass der Inhalt vorher in der Schule ausgiebig besprochen wurde.
Denn das Faszinierende an der Zauberflöte, neben der Musik natürlich, der Wechsel von Gut zu Böse und umgekehrt, der kam so nicht heraus. Steht zunächst die Königin der Nacht als die arme, des Kindes beraubte Mutter da, so entpuppt sich später Sarastro als der gute Protagonist, wenngleich nicht ganz, denn auch bei ihm ist nicht alles gut (“Zur Liebe will ich dich nicht zwingen, doch geb ich dir die Freiheit nicht”). In der Einführung zur gestrigen Vorstellung brachte der Herr, der sich nicht vorstellte, auch noch das Beispiel der Gewalt, die er an Monostatos ausführen ließ. Und auch er verwies auf diese nicht eindeutige Polarisierung.
Im Film von Kenneth Branagh, der übrigens auch phänomenal ist, geht die Interpretation sogar so weit, dass Sarastro ein Verhältnis mit der Königin der Nacht hatte, sie aber verließ. Er will sie zum Schluß retten, schafft es aber nicht.
Das Leben ist nicht schwarz oder weiß, und manches ist anders, als man es zunächst vermutet. Doch egal wie ist es ist, man muss an sich selbst arbeiten, um ein besserer Mensch zu werden. So würde ich in zwei Sätzen die Kernbotschaft der Zauberflöte formulieren, und wir sehen dies in allen Charakteren der Zauberflöte. Schaut man sich die Vereinfachung mancher heutigen politischen Problemlösungsansätze an, so wird deutlich, wie relevant die Zauberflöte noch heute sein kann. Es ist nicht einfach, es ist komplex. Und da helfen keine einfachen Antworten. Gerade diese Relevanz zur heutigen Zeit hat Jette Steckel versäumt aufzuzeigen.
Dass die Botschaft, an sich zu arbeiten, aus dem Gedankengut der Freimaurer stammen, liegt nahe, denn sowohl Mozart als auch Schikaneder, der das Libretto lieferte, waren Freimaurer. Es ist eine Ironie der Geschichte, dass man, wenn man aus dem Foyer der Staatsoper zur Straße schaut, in einem bestimmten Winkel den Eingang einer der über 40 Freimaurer-Logen in Hamburg sieht. Doch von all dem blieb nicht viel übrig in dieser Inszenierung.
Lebenswege und -Richtungen
Die rot leuchtenden Pfeile, die die Protagonisten mit sich herumschleppten, waren stattdessen das vorherrschende Motiv. Wege, die man nimmt, manche sind falsch, manche sind richtig. Und die Lebenswege von Pamina und Tamino, die sich erst am Ende wieder treffen und anscheinend zusammen bleiben, sind eine tolle Idee, wenn man das Leben als Reihe von Prüfungen und einem Labyrinth von falschen und richtigen Entscheidungen versteht. Und doch, wenn wir uns an das Grundmotiv erinnern, kann etwas komplett falsch oder richtig sein? Papageno, der die Prüfungen nicht bestand, einen “falschen” Weg beschritt, dafür aber seine Traumfrau kennen lernte, was ihm wahrscheinlich reichte. Die Pfeile sind somit eine wirklich gute Idee, die eine weitere Facette zur Interpretation hinzufügen. Dafür wurde ihr nur leider etwas anderes Wesentliches genommen.
Ein Zitat aus der “alten” Zauberflöten-Inszenierung meine ich übrigens entdeckt zu haben, nämlich die Hand, die Pamina leitet und umarmt (siehe Foto), nur dieses Mal ist sie aus Licht geformt. Sollte es tatsächlich ein Zitat sein, so ist es eine wunderschöne Idee.
Die neue Aufführung wird nicht meine neue Lieblingsaufführung werden. Und zwar allein wegen der Kürzung des Textes. Ein bisschen kürzen und anpassen, klar, der Schikaneder-Text ist nicht wirklich zeitgemäß.
Es ist schade, dass so radikal und meiner Meinung nach unnötig Inhalt entfernt wurde. Das Spiel mit dem Licht ist faszinierend, viele wirklich tolle Ideen stecken in dieser Inszenierung. Aber wie in der Zauberflöte selbst: Kein eindeutiges “gut” oder “schlecht”.
Übrigens werden anscheinend keine Solisten mehr aus dem Tölzer Knabenchor eingeflogen. Die Jungs gestern stammten aus einem Dortmunder Chor; leider war der Erste Knabe viel zu laut, so dass die anderen beiden Knaben untergingen. Ich habe mich aber schon immer gefragt, ob es in Hamburg keine Kinder gibt, die diesen Part übernehmen können. Auf der DVD der Ustinov-Inszenierung sangen noch Solisten eines Hamburger Chors. Was für die Kids und für die Umwelt sicherlich besser ist, wenn lokale Solisten auf die Bühne kommen.

 onsole API, die nur noch aktiviert werden muss.
onsole API, die nur noch aktiviert werden muss.