Mit jedem Google-Update werden die Rankings für manche Seiten durcheinander gewirbelt, und ab und zu fragt man sich, warum es manche Seiten trifft und andere nicht. Denn zum Teil werden Seiten „abgestraft“, bei denen man sich die Frage stellt, wie kann das sein? Das ist doch eigentlich eine gute Seite?
Dass Google Machine Learning nutzt, um die Relevanzberechnungs-Algorithmen zu optimieren, ist bekannt. Aber wie genau funktioniert das? Und was bedeutet das für Suchmaschinenoptimierer?
Wie Machine Learning funktioniert
Zunächst einmal wird zwischen Supervised und Unsupervised Learning unterschieden. Entweder überlässt man es der Maschine, Muster in Daten zu finden. Oder man gibt der Maschine vorab Trainingsmaterialien und sagt zum Beispiel, was gute und was schlechte Dokumente sind, damit die Maschine auf Basis des Gelernten in Zukunft bei neuen Dokumenten entscheiden kann, ob es ein gutes oder ein schlechtes Dokument ist.
Im Machine Learning wird häufig mit Distanzen gearbeitet, und das ist so ein zentrales Konzept, dass es genauer beleuchtet werden soll. Die folgenden Zeilen sind stark vereinfacht. Wir beginnen außerdem mit einem Unsupervised Learning-Beispiel, das in der Suchmaschinenwelt wahrscheinlich keine so große Rolle spielt, aber es zeigt das Konzept der Distanz auf eine sehr einfache Weise.

Stellen wir uns vor, wir haben eine Menge von Dokumenten, und für jedes Dokument sind Eigenschaften gemessen worden. Eine Eigenschaft ist zum Beispiel die Anzahl der Wörter in einem Dokument (X1), eine andere ist eine Maßzahl wie der stark vereinfachte PageRank der Domain, auf der das Dokument liegt (X2). Dies sind jetzt wirklich fiktive Werte, und es soll auf keinen Fall ausgesagt werden, dass es hier eine Korrelation gibt. Es geht nur um die Verdeutlichung.
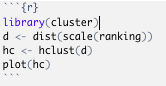
Zunächst werden die Werte auf diesselbe Skala gebracht (Befehl scale), danach wird eine Distanzmatrix erstellt (Befehl dist). Die Befehle für das Cluster werden später besprochen.
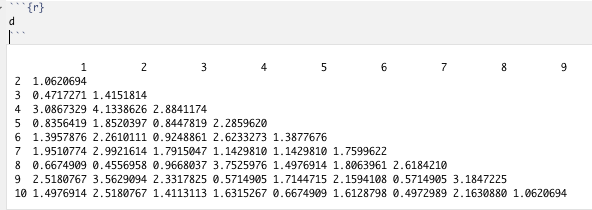
In der Distanzmatrix sind die Distanzen zwischen den einzelnen Reihen abgebildet. So ist der Abstand von Reihe 1 zu Reihe 3 geringer als der von Reihe 1 zu Reihe 4. Schaut man sich die Werte an, so sind diese Distanzberechnungen nachvollziehbar. Im nächsten Schritt werden daraus dann Cluster gebildet und diese in einem Dendrogramm geplottet:
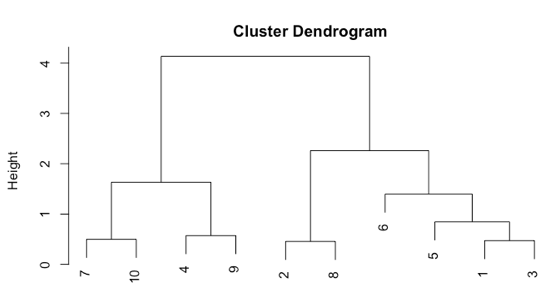
Auch hier kann man gut nachvollziehen, warum die Werte aus den Reihen 7 und 10 eher zusammen gehören als die Werte aus Reihe 1 und 3. Die Maschine hat diese Cluster allein aus den Distanzen berechnen können.
Was haben Googles Human Quality Rater mit Machine Learning zu tun?
Nun gehen wir einen Schritt weiter. Wir wissen, dass Google Menschen Suchergebnisse beurteilen lässt, von highest zu lowest usw. Die Rater Guidelines sind einfach zu finden. Auch hier kommen wieder Distanzen ins Spiel, sobald “highest” eine Zahl bekommt und “lowest” und alle Werte dazwischen.
Natürlich können die Human Quality Rater nicht alle Suchergebnisse durchsehen. Stattdessen werden bestimmte “Regionen” trainiert, das heißt, dass die Bewertungen genutzt werden, um den Algorithmus für bestimmte Suchanfragen oder Signalkonstellationen optimieren zu lassen. Anders als im vorherigen Beispiel haben wir es hier mit Supervised Learning zu tun, denn wir haben eine Target Variable, das Rating. Gehen wir jetzt davon aus, dass mehr als 200 Faktoren für das Ranking verwendet werden, dann könnte man die Aufgabe für den Algorithmus so formulieren, dass er all diese Faktoren so anpassen muss, dass er auf das Target Rating kommt.
Um genauer zu verstehen, wie so etwas funktioniert, nehmen wir wieder ein stark vereinfachtes Beispiel, dieses Mal von einer Support Vector Machine.
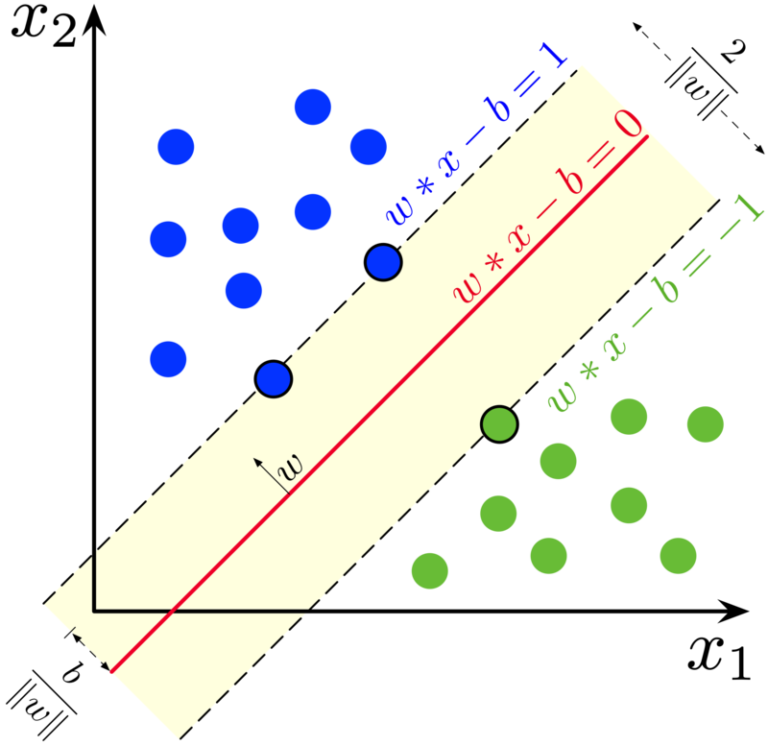
Das Prinzip der Support Vector Machines ist ein simpler, aber ziemlich durchdachter Ansatz, um die optimale Distanz zwischen zwei verschiedenen Segmenten zu berechnen. Nehmen wir im obigen Bild die rote Linie. Sie durchtrennt die blauen und die grünen Kreise. Sie könnte aber genau so gut ein paar Grad nach links oder rechts gedreht werden, und sie würde immer noch die beiden Segmente perfekt voneinander trennen. Und nun kommt der Trick: Um die optimale Trennung zu berechnen, wird die Linie einfach erweitert um zwei parallele Linien. Und der Winkel, bei dem die beiden Parallellinien am breitesten oder am weitesten voneinander entfernt sind, das ist der optimale Winkel für die rote Linie.
Nehmen wir nun an, die beiden Segmente sind wieder Signale aus dem Ranking, x1 ist der PageRank, x2 die PageSpeed. Die Daten werden hier in einem zweidimensionalen Raum geplottet, und man kann schön sehen, dass sie wunderbar voneinander getrennt sind. Wir könnten also unsere Maschine anhand dieser Daten trainieren und dann in Zukunft sagen, wenn neue Elemente in den Raum kommen, dass sie basierend auf dem Gelernten klassifiziert werden sollen. Und das funktioniert nicht nur mit 2 Variablen, sondern auch mit ganz vielen. Der Raum zwischen den Punkten wird dann Hyperplane genannt.
Nun sind Daten nicht immer so genau trennbar. Nehmen wir das Beispiel mit PageRank und PageSpeed. Nur weil eine Seite einen hohen PageRank hat, bedeutet das nicht, dass sie auch eine super Speed haben muss. Es könnte in dem Bild oben also auch vorkommen, dass ein paar grüne Kreise in den blauen sind und umgekehrt. Wie kann dann noch ein ein Trennbalken durch die Segmente berechnet werden? Ganz einfach: Für jeden Kreis, der sich nicht klar auf “seiner” Seite befindet, gibt es einen Minuspunkt. Und nun wird einfach berechnet, bei welchem Balken und seiner Lage die wenigsten Minuspunkte zustande kommen. Dies wird als “Loss Function” bezeichnet. Um es anders auszudrücken: Selbst “gute” Seiten könnten nach einer Support Vector Machine als “schlecht” klassifiziert werden, der Trick ist halt, sowenig gute Seiten wie möglich als schlecht zu klassifizieren und umgekehrt. Es ist halt unwahrscheinlich, dass alle “guten” Seiten dieselben Eigenschaften haben.
Was bedeutet das für Suchmaschinenoptimierer?
Zunächst einmal bedeutet es, was ich schon vor über einem Jahr auf der SEO Campixx-Konferenz gesagt habe, dass es keine statische Gewichtung gibt; das Ranking ist dynamisch. Bei Ask.com hatten wir einzelne Regionen trainiert, zum Beispiel wenn es keine Backlinks gab oder wenig Text oder bei Gesundheitssuchanfragen usw. No one size fits all. Uns stehen heute eben nicht alle 200 Signale zur Verfügung, um das Ranking pro Suchbegriff zu re-engineeren.
Gleichzeitig wird aber auch klar, warum manchmal Seiten abgestraft werden, die es eigentlich nicht verdient hätten. Es liegt nicht daran, dass sie für schlecht befunden worden wären, nur dummerweise haben sie zu viele Signale, die für ein schlechteres Ranking sprechen. Und da die Rater nicht bewusst nach irgendwelchen Signalen gesucht haben, hat der Algorithmus, sei es Support Vector Machines oder etwas anderes, halt selbst die Signale ausgewählt, die einen minimalen Loss bedeuten. Und da wir nicht alle 200 Signale haben, ist es für uns auch oft unmöglich nachzuvollziehen, was es genau gewesen sein kann. Man kann bei einem Re-engineering nur hoffen, dass unter den zur Verfügung stehenden Signalen schon etwas Brauchbares dabei ist.
Umso wichtiger ist die Beschäftigung mit den Quality Rater Guidelines. Woran machen die Rater Expertise, Trust und Authority fest? Was führt zur “highest” Bewertung? Auch wenn es langweilig ist, einen besseren Tipp kann man neben den Hygienefaktoren wahrscheinlich kaum geben.
Support Vector Machines wurden übrigens in den 60er Jahren entwickelt. Als von Data Science noch nicht die Rede war. Auch noch interessant sind die Ranking SVMs