In den ersten beiden Teilen ging es darum, was Data Science überhaupt ist und warum WDF/IDF-Werte sehr wahrscheinlich wenig mit dem zu tun haben, was bei Google unter der Motorhaube passiert. In diesem Teil geht es einen Schritt weiter, wir schauen nämlich, ob es Korrelationen zwischen Ranking Signalen und der Position gibt. Im Vortrag hatte ich das am Beispiel einer Suchanfrage gezeigt und angesichts der zur Verfügung stehenden Zeit auch eher kurz abgehandelt. Hier kann ich in die Tiefe gehen. Wir schauen uns hierbei allerdings erst einmal nur jedes einzelne Rankingsignal in Bezug auf die Positon an, nicht die eventuell vorhandene Wirkung der Rankingsignale untereinander.
Risiken und Nebenwirkungen von Data Science
Da mein Vortrag bei manchen Kollegen für Schnappatmung und zum Teil “interessante” Äußerungen gesorgt hat, war ein Punkt wahrscheinlich untergegangen. Denn ich hatte ausdrücklich gesagt, und das wiederhole ich hier, dass ich nicht die Aussage treffe, dass man von diesen Daten davon ausgehen kann, dass das Ranking so funktioniert. Wer einmal mit Rechtsanwälten oder Statistikern zu tun hatte weiß, dass diese sich nur ungern auf belastbare Aussagen festnageln lassen wollen. Schließlich kennen wir in der Regel nicht die Gesamtpopulation und müssen daher von einem kleinen Sample auf die Grundgesamtheit schließen; wer ist denn so verrückt und lässt sich darauf festnageln? Daher all die Komplexität mit Konfidenzniveau, Konfidenzintervallen etc…
Die folgenden Aussagen beziehen sich auf ein Sample von 5.000 Suchanfragen. Das klingt nach viel, aber wir wissen nicht, ob diese Suchanfragen der Gesamtpopulation aller Suchanfragen entsprechen. Die Ergebnisse gelten also für das Sample, und ich bin jederzeit bereit, dass für andere Suchanfragen zu wiederholen, wenn mir diese Suchanfragen zur Verfügung gestellt werden.
Weitere Probleme in diesem Ansatz: Wir haben Zugriff auf ein paar Ranking-Signale, aber nicht alle, und die wenigen Signale, die wir haben, sind zum Teil auch noch ungenau. Wir haben von den über 200 Ranking-Signalen:
- Domain-Alter: ungenau, da sich die einzelnen Quellen wiedersprechen und auch kein Muster zu erkennen ist, ob eine Quelle generell jüngere Werte ausgibt als die andere
- Backlinks: hier haben wir die Werte, die aus Tools ausgegeben werden, und die haben in der Regel keine komplette Übersicht aller Backlinks
- Anchor Texte: Da wir nicht davon ausgehen können, dass die Backlinks komplett sind, können wir auch nicht damit rechnen, dass wir alle Anchor Texte haben
- Text Matches: Wir können Exact Matches identifizieren, haben aber im vorherigen Teil gesehen, dass Suchmaschinen das nicht tun
- Textlänge
- Speed
- https versus http
- Lesbarkeit
Uns fehlen also Signale wie
- User Signals
- Quality Score
- Domain History
- RankBrain
- und einiges mehr
Zusammengefasst haben wir nur einen Bruchteil der Daten, und von denen sind einige auch nicht mal genau. Und meine Berechnungen basieren zudem auf Suchanfragen, von denen wir nicht wissen, ob sie repräsentativ sind.
Ein Wort noch zu Korrelationen
Mein Lieblingsbeispiel für den verhängnisvollen Glauben an Korrelationen ist der statistische Zusammenhang zwischen den Marktanteilen des Microsoft Internet Explorers und der Mordrate in den USA zwischen 2006 und 2011. Zwar mag es witzig sein zu behaupten, dass hier ein Zusammenhang besteht (und das führt auch regelmäßig zu einem Lacher in Vorträgen), aber Tatsache ist, dass hier ein statistischer Zusammenhang, den wir als Korrelation bezeichnen, kein wirklicher Zusammenhang sein muss. Korrelation bedeutet nicht Ursache und Wirkung. Schlimmer noch, in der Statistik wissen wir nicht mal, in welche Richtung der statistische Zusammenhang läuft. In diesem Beispiel also, ob die Marktanteile des Internet Explorers zu mehr Morden geführt haben, oder ob die Morde dazu geführt haben, dass man danach den Internet Explorer benutzt hat, um seine Spuren zu verwischen.
Natürlich sind die Zusammenhänge in manchen Situationen klar: Wenn ich mehr Geld ausgebe bei AdWords, dann bekomme ich evtl. mehr Conversions. Und wenn wir den statistischen Zusammenhang zwischen Ranking-Signalen untersuchen, dann ist es wahrscheinlich, dass mehr Backlinks zu einer besseren Position führen, auch wenn natürlich eine bessere Position dafür sorgen kann, dass mehr Webseitenbetreiber interessante Inhalte finden und diese verlinken… Wir wissen aber nicht, ob zum Beispiel die einzelnen Signale sich untereinander beeinflussen können, und wir schauen uns in der Regel ja auch nur die Top 10 an. Wie im vorherigen Teil beschrieben ist das eine Art Jurassic Park, wo wir nicht das ganze Bild haben.
Ein wenig deskriptive Statistik
Jede Analyse beginnt mit einer Beschreibung der Daten. Für die 5.000 Suchanfragen haben wir mehr als 50.000 Suchergebnisse bekommen, aber die Ergebnisse, die auf Google-Dienste zeigen, nehmen wir erst einmal raus, da wir nicht wissen, ob diese nach den normalen Ranking-Faktoren gerankt werden. Es bleiben 48.837 URLs über, die sich auf 14.099 Hosts verteilen.
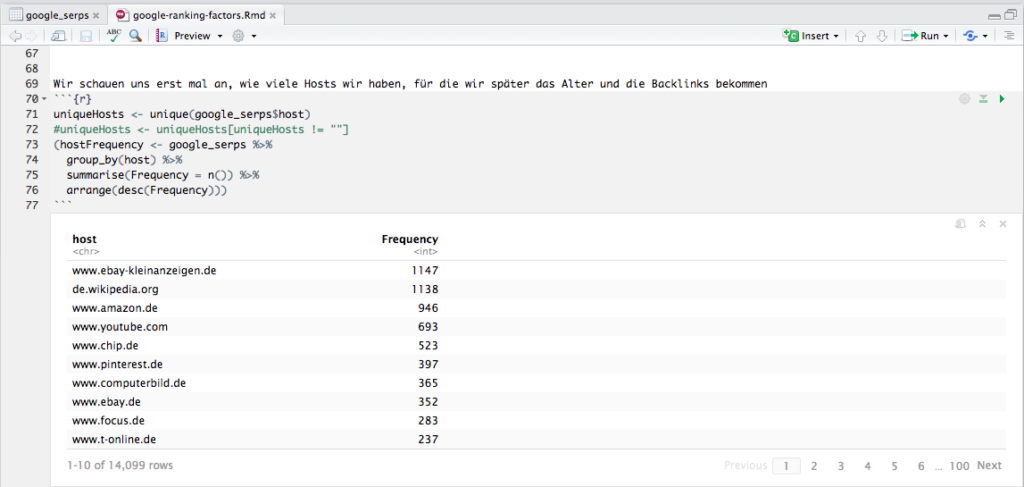
In letzter Zeit arbeite ich vermehrt mit dplyr, das ein Piping ermöglicht wie unter Linux/UNIX; diese Funktionalität wurde dem magrittr-Package entliehen, und sie macht den Code unglaublich übersichtlich. In dem Beispiel in der Abbildung werfe ich nach der auskommentierten Zeile meinen Dataframe google_serps auf group_by(), das nach host gruppiert, und das Ergebnis dieses Schritts werfe ich auf summarise(), das mir dann die Häufigkeiten pro Host berechnet, und das werfe ich zum Schluß noch auf arrange(), was das Ergebnis absteigend sortiert. Das Ergebnis schreibe ich in hostFrequency, und weil ich das Ergebnis in meinem R Notebook sofort sehen will, setze ich den ganzen Ausdruck in Klammern, damit das Ergebnis nicht nur in den Dataframe hostFrequency geschrieben wird, sondern auch gleich ausgegeben. Jedes Mal, wenn ich sowas mit dplyr mache, freue ich mich einen Ast. Und wenn man richtig große Datensätze hat, dann macht man das gleiche mit sparklyr :).
Aber zurück zum Thema: Wir sehen hier also, dass wenige Hosts sehr häufig ranken, und das heißt umgekehrt, dass viele Hosts nur einmal ranken. Keine Überraschung hier.
Zum Aufwärmen: Speed als Rankingfaktor
Die Speed-Daten für jeden Host sind sehr einfach zu bekommen, denn Google bietet dafür die PageSpeed Insights API an, und netterweise gibt es hierfür auch ein R Package. Bei über 10.000 Hosts dauert die Abfrage etwas, und mehr als 25.000 Anfragen pro Tag darf man nicht stellen sowie nicht mehr als 100 (?) Anfragen pro 100 Sekunden. Ich hab das einfach laufen lassen, und nach 1 Tag war mein R abgestürzt und alle Daten verloren. Nicht schön, aber ein Workaround: Nach jedem Request den Dataframe auf die Festplatte schreiben.
Aber schauen wir uns die Daten jetzt einmal genauer an. Hier ist ein Histogramm der Verteilung der Speed-Werte von 14.008 Hosts (ich hab also für 99,4% der Hosts einen PageSpeed-Wert erhalten):

Wir sehen, dass die meisten Hosts es über die 50 Punkte schaffen, und summary gibt uns folgende Zahlen:
Min. 1st Qu. Median Mean 3rd Qu. Max. 0.00 55.00 70.00 66.69 82.00 100.00
Schön ist hier zu sehen, wie irreführend der Durchschnitt sein kann Und nun plotten wir einmal Positionen versus Speed:

Wie wir sehen, sehen wir nix. Das prüfen wir noch einmal genauer:
cor.test(google_serps$position,google_serps$SPEED) Pearson’s product-moment correlation data: google_serps$position and google_serps$SPEED t = -5.6294, df = 48675, p-value = 1.818e-08 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.03438350 -0.01662789 sample estimates: cor -0.02550771
Sieht so aus als ob es keine Korrelation zwischen PageSpeed und Position in den Top 10 gäbe (wir wissen nicht, ob es vielleicht eine gäbe in den Top 100, könnte ja sein, dass die Plätze 11 bis 100 schlechtere PageSpeed-Werte haben). Aber es ist auch nicht unwahrscheinlich, dass wir es mit einem Hygiene-Faktor zu tun haben: Wenn man gut rankt, dann hat man keinen Vorteil, wenn man schlecht rankt, dann wird man bestraft. Das ist ungefähr so als ob man duscht, dann merkt es keiner, aber wenn man nicht geduscht hat, dann fällt es auf. Oder, kurz gefasst (so soll ich es auf der SEO Campixx gesagt haben), eine langsame Webseite ist wie nicht geduscht zu haben Allerdings sehen wir auch Hosts, die trotz einer gruseligen Speed ranken. Aber wenn man nach “ganter schuhe” sucht, dann ist http://ganter-shoes.com/de-at/ wohl das beste Ergebnis, auch wenn die Seite bei mir 30 Sekunden zum Laden benötigt.
Bedenken sollten wir auch, dass die PageSpeed API eine Echtzeit-Messung durchführt… vielleicht haben wir nur einen schlechten Moment erwischt? Man müsste eigentlich mehrmals die PageSpeed messen und daraus einen Durchschnitt erstellen.
SSL als Rankingfaktor
Was wir auch sehr einfach bekommen an Daten, ist die Unterscheidung, ob ein Host https verwendet oder nicht. Während manche die Verwendung sicherer Protokolle als einen gewichtigen Rankingfaktor ansehen, sehen gemäßigtere Stimmen wie Sistrix die Verwendung von SSL eher als schwachen Rankingfaktor. In diesem Datensatz haben 70% aller URLs ein https. Aber bedeutet das auch, dass diese Seiten besser ranken?
Wir haben es hier mit einer besonderen Form der Berechnung zu tun, denn wir versuchen den Zusammenhang zwischen einer kontinuierlichen Variable (der Position) und einer dichotomen Variable (SSL ja/nein) zu ermitteln. Die beiden Varianten des Protokolls wandeln wir um in Zahlen, http wird zu einer 0, https zu einer 1 (siehe Screenshot unten in den Spalten secure und secure2).
Die Ermittlung des Point-Biserial Koeffizienten ist ein Sonderfall des Pearson Korrelation Koeffizients; normalerweise würden wir in R einfach cor.test(x,y) eingeben, aber hierfür wird ein zusätzliches Paket geladen, was diese Sonderform unterstützt. Tatsächlich unterscheiden sich die Werte der beiden Tests aber kaum, und cor.test liefert mir zudem noch den p-Wert.

Wie wir sehen, sehen wir nix oder fast nix: Mit einem Korrelations-Koeffizienten von -0,045067 können wir ausschließen, dass https einen Einfluss auf das Ranking in den Top 10 gehabt hat. Bedeutet das, dass wir alle wieder auf https verzichten sollten? Nein, denn für den Nutzer ist es besser. Und sobald Browser noch deutlicher zeigen, dass eine Verbindung nicht sicher ist, werden sich die Nutzer eher schneller von einer Seite verabschieden. Ganz abgesehen davon, dass wir uns hier ja nur die Top 10 angesehen haben. Es könnte ja sein, dass die Plätze 11 bis 1000 vor allem von Seiten ohne SSL belegt waren. Und dann könnten die Ergebnisse schon wieder anders aussehen.
Vielleicht haben wir es bei SSL als Ranking-Faktor aber auch mit einem umgekehrten Hygienefaktor zu tun. Google hätte zwar gerne SSL, aber da manche wichtige Seite evtl noch kejn SSL hat, verzichtet man darauf. So wie man vielleicht gerne hätte, dass der Traumpartner geduscht ist, aber wenn die oder der dann plötzlich vor einem steht, dann ist es doch egal, weil man halt so verliebt ist. Auf Dauer geht das natürlich nicht gut. Und so wird das bei SSL auch sein
Alter einer Domain als Ranking-Faktor
Gehen wir zu dem nächsten Ranking-Signal, dem Alter einer Domain, auch wenn es heißt, dass das Alter einer Domain keine Rolle spielt. Hier stehen wir vor einer ersten Herausforderung: Wie bekomme ich möglichst automatisch und vor allem zuverlässig das Alter einer Domain heraus? Sistrix bietet das Alter einer Domain an, aber nicht die eines Hosts (der Unterschied wird im Skript zu meinem SEO-Seminar an der HAW erklärt). Trotzdem hat Sistrix den Vorteil, dass die API sehr schlank und schnell ist. Allerdings findet Sistrix für 2.912 der Domains (nicht Hosts) kein Alter, bei 13.226 unique Domains sind das dann 22% ohne Domain-Alter. Jurassic Park lässt grüßen (wer diese Anspielung nicht versteht, bitte den zweiten Teil über Data Science und SEO lesen). Schauen wir uns dennoch einmal die Verteilung an:

Wir sehen eine leicht rechtsschiefe Verteilung, d.h. dass wir links bei den älteren Domains eine höhere Frequenz sehen (nein, ich sehe nicht spiegelverkehrt, so bezeichnet man das halt). Jüngere Domains scheinen hier geringere Chancen zu haben. Allerdings kann es auch sein, dass Sistrix gerade jüngere Domains nicht in der Datenbank hat und die knapp 3.000 fehlenden Domains eher rechts anzusiedeln wären.
Können wir wenigstens hier eine Korrelation sehen? Wir plotten die Daten erst einmal:
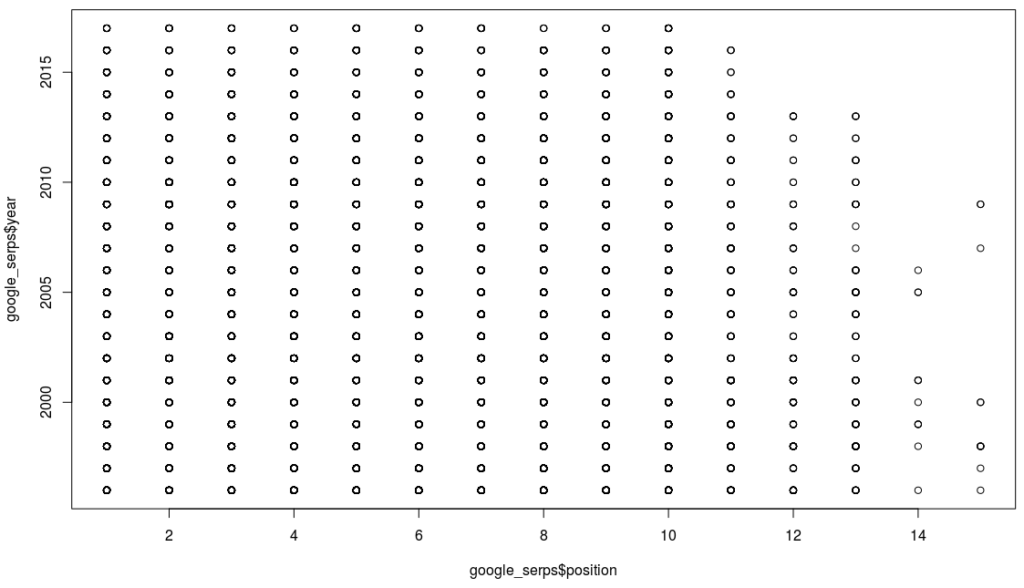
Auch hier sehen wir nix, und wenn wir uns die Korrelation berechnen lassen, dann bestätigt sich das:
cor.test(google_serps$position,as.numeric(google_serps$year)) Pearson’s product-moment correlation data: google_serps$position and as.numeric(google_serps$year) t = 1.1235, df = 44386, p-value = 0.2612 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.003970486 0.014634746 sample estimates: cor 0.005332591
Ich habe nicht nur keine Korrelation, sondern liege auch außerhalb des Konfidenzniveaus. Das Ergebnis ist aber mit viel Vorsicht zu genießen, denn wie oben schon erwähnt kann es sein, dass unsere Auswahl einfach nicht repräsentativ ist, denn vermutlich wird nicht jede Domain die gleiche Chance gehabt haben in die Domain-Alter-Datenbank von Sistrix zu kommen. Wir müssten diese Daten also ergänzen und eventuell auch die Daten von Sistrix überprüfen (ich habe nicht herausfinden können, woher Sistrix die Daten hat); leider habe ich auch kein Muster identifizieren können, denn manchmal zeigt die eine Quelle ältere Daten an, manchmal eine andere Quelle. Im Prinzip müsste man alle Datenquellen nehmen und dann immer das älteste Datum nehmen. Nur leider lassen sich die meisten Quellen auch nicht so einfach scrapen Und somit haben wir nicht nur fehlende, sondern auch zum Teil fehlerhafte Daten. Und das ist kein untypisches Problem im Data Science Bereich.
Zwischengedanken
Da ich schon bald die 2.000 Wörter zusammen habe (und ich die Korrelation Wörter/”bis zum Ende des Artikels gelesen” für mein Blog kenne), werde ich die nächsten Ranking-Faktoren im nächsten Blogpost begutachten. Wichtig: Wir sehen hier zwar, dass wir für angeblich sehr wichtige Ranking-Faktoren keine Evidenz finden, dass sie tatsächlich einen Einfluss haben. Aber das bedeutet nicht, dass das wirklich stimmt:
- Wir haben zum Teil fehlende und fehlerhafte Daten
- Wir haben eventuell kein valides Sample
- Und Google hat ein dynamisches Ranking, was bedeutet, dass für manche Queries einige Signale mit der Position korrelieren, für andere nicht. Die Holzhammer-Methode, die wir hier angewandt haben. ist sicherlich nicht zielführend.
Beispiel:
cor.test(google_serps$position[google_serps$keyword==“akne vitamin a”],google_serps$secure2[google_serps$keyword==“akne vitamin a”]) Pearon’s product-moment correlation data: google_serps$position[google_serps$keyword == “akne vitamin a”] and google_serps$secure2[google_serps$keyword == “akne vitamin a”] t = -4.6188, df = 8, p-value = 0.001713 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.9645284 -0.4819678 sample estimates: cor -0.8528029
Auch wenn das Konfidenzintervall hier sehr groß ist, es bewegt sich für diese Suchanfrage “akne vitamin a” immer noch im Bereich einer mittleren bis starken Korrelation (es korreliert negativ, weil die Positionen von 1 bis 10 oder weiter hoch gehen). Es gilt also auch die Segmente oder “Regionen” zu identifizieren, wo bestimmte Signale eine Wirkung haben. Dazu mehr im nächsten Teil über Data Science und SEO.