Nachdem ich im ersten Teil erklärt habe, was Data Science ist und was es in diesem Bereich schon zum Thema SEO gibt, nun der zweite Teil, wo wir uns etwas genauer damit beschäftigen, was die linguistische Verarbeitung eines Dokuments durch eine Suchmaschine für eine Auswirkung auf SEO-Konzepte wie Keyword Density, TF/IDF und WDF/IDF hat. Da ich auf der SEO Campixx live Code gezeigt habe, biete ich hier alles zum Download an, was das Nachvollziehen der Beispiele noch erlebnisreicher macht Das geht übrigens auch ohne die Installation von R, hier ist der komplette Code mit Erklärungen und Ergebnissen zu finden.
Für diejenigen, die es in R nachvollziehen wollen
(Bitte überspringen, wenn Du das nicht in R selber nachbauen möchtest)
Ich empfehle die Nutzung von RStudio zusätzlich zu R, weil der Umgang mit den Daten damit für Neulinge etwas einfacher ist (und für Profis auch). R gibts beim R Project, RStudio auf rstudio.com. Erst R installieren, dann RStudio.
In der ZIP-Datei befinden sich zwei Dateien, ein Notebook und eine CSV-Datei mit einem kleinen Text-Corpus. Ich verweise in diesem Text ab und zu auf das Notebook, aber das Notebook kann auch so durchgearbeitet werden. Wichtig: Bitte nicht die CSV-Datei mit dem Import-Button einlesen, denn dann wird eine Library geladen, die die Funktionalität einer anderen Library zunichte macht.
Das Notebook hat den großen Vorteil, dass sowohl meine Beschreibung, der Programm-Code als auch das Ergebnis im gleichen Dokument zu sehen sind.

Um den Programm-Code auszuführen, einfach rechts oben in der Ecke auf den grünen Pfeil klicken, und schon funktioniert es
Was ist TF/IDF bzw. WDF/IDF?
(Bitte überspringen, wenn die Konzepte klar sind!)
Es gibt Menschen, die TF/IDF (Term Frequency/Inverse Document Frequency) bzw WDF/IDF (Word Document Frequency/Inverse Document Frequency) besser erklären können als ich, bei WDF/IDF hat sich Karl mit einem unglaublich guten Artikel hervorgetan (und übrigens in diesem Artikel auch schon gesagt, dass “eigentlich kein kleiner bzw. mittelgroßer Anbieter von Analyse-Werkzeugen eine derartige Berechnung für eine große Anzahl an Benutzern anbieten kann … ;-“).
Eine simplifizierte Erklärung ist, dass die Term Frequency (TF) die Häufigkeit eines Terms in einem Dokument ist, die Inverse Document Frequency (IDF) dagegen die Bedeutung eines Terms misst in Bezug auf alle Dokumente eines Corpus, in denen der Begriff vorkommt (Corpus ist der Begriff der Linguisten für eine Kollektion von Dokumenten; das ist nicht dasselbe wie ein Index).
Bei TF wird, vereinfacht und dennoch noch immer viel zu kompliziert ausgedrückt, die Anzahl des Vorkommens eines Begriffes gezählt und dann in der Regel normalisiert, indem diese Zahl durch die Anzahl aller Wörter im Dokument geteilt wird (diese Definition ist in dem Buch “Modern Information Retrieval” von Baeza-Yates et al zu finden, der Bibel der Suchmaschinenbauer). Es gibt aber weitere Gewichtungen der TF, und WDF ist eigentlich nichts weiter als eine solche andere Gewichtung, denn hier wird die Term Frequency um einen Logarithmus zur Basis 2 versehen.
Bei der IDF wird die Anzahl aller Dokumente im Corpus durch die Anzahl der Dokumente geteilt, in denen der Begriff auftaucht, und das Ergebnis wird dann um einen Logarithmus zur Basis 2 versehen. Die Term Frequenz oder die Word Document Frequency wird dann mit der Inverse Document Frequency multipliziert, und schon haben wir TF/IDF (oder, wenn wir WDF anstatt TF verwendet haben, WDF/IDF). Die Frage, die sich mir als Ex-Mitarbeiter von mehreren Suchmaschinen stellt, ist aber, was genau hier ein Begriff ist, denn hinter den Kulissen wird eifrig an den Dokumenten herumgewerkelt. Dazu mehr im nächsten Abschnitt “Crash-Kurs Stemming…”.
Crash-Kurs Stemming, Komposita und Proximity
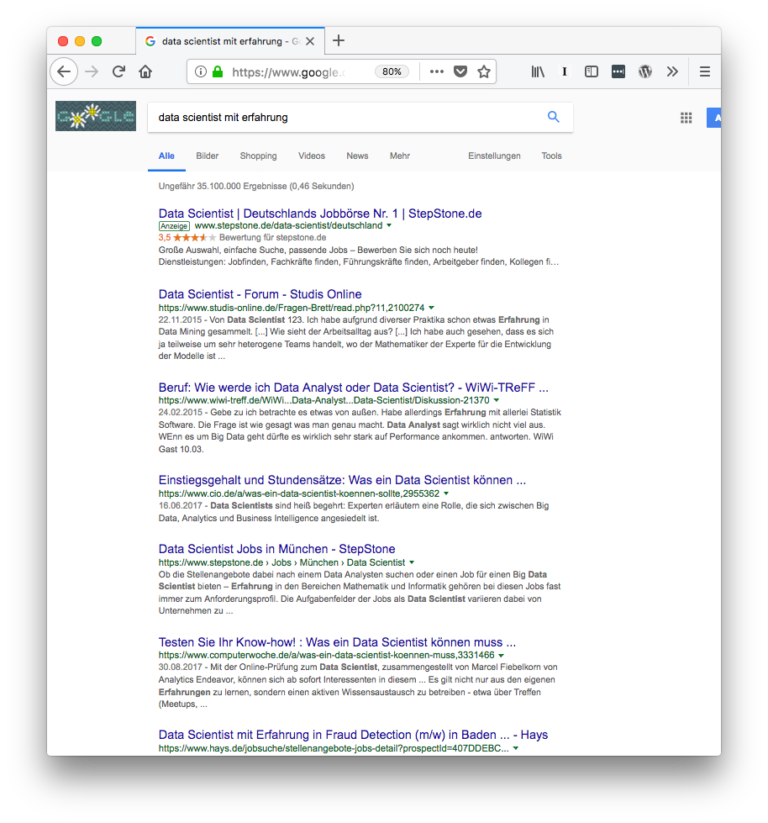
Jeder hat schon die Erfahrung gemacht, dass man nach einem Begriff sucht und dann eine Ergebnisseite bekommt, auf der der Begriff auch in abgewandelter Form zu finden ist. Das liegt zum Beispiel daran, dass ein Stemming durchgeführt wird, bei dem Wörter auf ihren Wortstamm reduziert werden. Denn nicht nur im Deutschen wird konjugiert und dekliniert, auch andere Sprachen verändern Wörter je nach Person, Tempus etc. Um den Recall zu erhöhen wird also nicht nur nach dem exakten Begriff gesucht, sondern auch Varianten dieses Begriffes (den Begriff “Recall” hatte ich im Vortrag nicht verwendet, er beschreibt im Information Retrieval, wie viele passende Dokumente für eine Suchanfrage gefunden werden). So werden für die Suchanfrage “Data Scientist mit Erfahrung” auch Dokumente gefunden, die zum Beispiel die Begriffe “Data Scientist” und “Erfahrungen” enthalten (siehe Screenshot links).
Im Vortrag habe ich live “gestemmt”, und zwar mit dem SnowballC-Stemmer. Dieser ist nicht unbedingt der beste Stemmer, aber er liefert einen Eindruck davon, wie das mit dem Stemming funktioniert. In dem R-Notebook zu diesem Beitrag ist der Stemmer leicht erweitert, denn dummerweise stemmt der SnowBallC immer nur das letzte Wort, so dass der Stemmer in eine Funktion gepackt wurde, die dann einen ganzen Satz komplett stemmen kann:
| > stem_text(„Dies ist ein toller Beitrag“) [1] „Dies ist ein toll Beitrag“ > stem_text(„Hoffentlich hast Du bis hierhin gelesen.“) [1] „Hoffent hast Du bis hierhin geles.“ |
Es sind aber nicht nur Varianten eines Begriffes. Gerade wir Deutschen sind Weltmeister im Erfinden neuer Wörter, indem wir sie durch das Zusammensetzen von anderen Wörtern “komponieren”. Nicht umsonst werden diese Wortschöpfungen Komposita genannt.Ein Beispiel für die Verarbeitung von Komposita findet sich in dem Screenshot rechts, wo aus dem Länderdreieck das Dreiländereck wird. Zunächst einmal klingt das ganz einfach, man trennt einfach Begriffe, die als einzelnes Wort stehen könnten, und indexiert diese dann. Allerdings ist es nicht ganz so einfach. Denn nicht jedes Kompositum darf getrennt werden, weil es getrennt eine andere Bedeutung bekommt. Denken wir zum Beispiel an “Druckabfall”, wo das Abfallen des Drucks auch als Druck und Müll interpretiert werden könnte

Am Beispiel des “Data Scientist mit Erfahrung” wird auch ein weiteres Verfahren der Suchmaschinen deutlich: Begriffe müssen nicht zusammen stehen. Sie können weiter auseinander stehen, was manchmal für den Suchenden extrem nervig sein kann, wenn einer der Begriffe in der Suchanfrage in einem völlig anderen Kontext steht. Die Proximity, also die Nähe der Begriffe, kann ein Signal für die Relevanz der im Dokument vorhandenen Begriffe für die Suchanfrage sein. Google bietet Proximity als Feature an, wie Proximity als Ranking-Signal verwendet wird, ist nicht klar. Und hiermit ist nur die textliche Nähe, noch nicht die semantische Nähe gemeint. Natürlich wird noch viel mehr prozessiert in der lexikalischen Analyse, abgesehen vom Stop Word Removal etc. Aber hier geht es erst einmal nur um einen kleinen Einblick.
Wir sehen hier also gleich drei Punkte, die die meisten SEO-Tools nicht können: Stemming, Proximity und Decompounding. Wenn man also in den Tools über Keyword Density, TF/IDF oder WDF/IDF redet, dann in der Regel auf Basis von Exact Matches und nicht den Varianten, die eine Suchmaschine mit verarbeitet. Bei den meisten Tools wird das nicht deutlich; so kann das allseits beliebte Yoast SEO Plugin für WordPress nur den Exact Match verwenden und berechnet dann eine Keyword Density (Anzahl des Begriffes im Verhältnis zu allen Wörtern des Dokuments). ryte.com sagt aber zum Beispiel:
Darüber hinaus berücksichtigt allein die Formel WDF*IDF nicht, dass Suchbegriffe auch in einem Absatz gehäufter vorkommen können, dass Stemming-Regeln gelten könnten oder dass ein Texte verstärkt mit Synonymen arbeitet.
Solange die SEO-Tools das also nicht können, können wir also nicht davon ausgehen, dass diese Tools uns “echte” Werte geben, und genau das hat der liebe Karl Kratz auch schon gesagt. Es sind Werte, die auf Basis eines Exact Match errechnet wurden, wohingegen Suchmaschinen eine andere Basis nutzen. Vielleicht ist das auch komplett egal, weil alle nur die SEO-Tools nutzen und darauf optimieren, das schauen wir uns im nächsten Teil an Es gibt aber noch weitere Gründe, warum die Tools uns nicht die ganze Sicht bieten, und diese schauen wir uns im nächsten Abschnitt einmal genauer an.
Können wir TF/IDF oder WDF/IDF überhaupt richtig messen?
Nun sagt bereits die Definition von IDF aus, warum ein Tool, das TF/IDF ausspuckt, ein kleines Problem hat: Es weiß nicht, wie viele Dokumente mit dem Begriff im Google-Corpus sind, es sei denn, diese Zahl wird auch aus den Ergebnissen “gescraped”. Und hier haben wir es eher mit Schätzungen zu tun. Nicht umsonst steht bei den Suchergebnissen immer “Ungefähr 92.800 Ergebnisse”. Stattdessen nutzen die meisten Tools entweder die Top 10, die Top 100 oder vielleicht sogar einen eigenen kleinen Index, um die IDF zu berechnen. Hinzu kommt, dass wir ja auch noch die Anzahl ALLER Dokumente im Google-Index benötigen (beziehungsweise aller Dokumente eines Sprachraums, worauf mich Karl Kratz noch mal aufmerksam machte). Laut Google sind dies 130 Billionen Dokumente. Wir müssten also, ganz vereinfacht, so rechnen (ich nehme mal TF/IDF, damit der Logarithmus nicht alle abschreckt, aber das Prinzip ist das gleiche):
TF/IDF = (Häufigkeit des Begriffes im Dokument/Anzahl der Wörter im Dokument)*log(130 Billionen/”Ungefähr x Ergebnisse”),
wobei x die Anzahl ist, die Google pro Suchergebnis anzeigt. So, und dann hätten wir eine Zahl pro Dokument, aber wir wissen ja nicht, auf welchen TF/IDF- oder WDF/IDF-Wert die Dokumente kommen, die nicht unter den untersuchten Top 10 oder Top 100 Ergebnissen sind. Es könnte sein, dass auf Platz 967 ein Dokument ist, dass bessere Werte aufweist. Wir sehen nur unseren Ausschnitt und vermuten, dass dieser Ausschnitt uns die Welt erklärt.
Und hier kommt kurz die Chaos-Theorie ins Spiel Wer Jurassic Park gesehen (oder sogar das Buch gelesen) hat, der erinnert sich vielleicht an den Chaos-Theoretiker, im Film gespielt von Jeff Goldblum. In Jurassic Park spielt die Chaos-Theorie eine große Rolle, denn es geht darum, dass komplexe Systeme ein Verhalten aufweisen können, das schwer vorhersehbar ist. Und so werdem weite Teile des Parks von Videokameras überwacht, bis auf 3% des Areals, und genau dort pflanzen sich die Dinosaurierweibchen fort. Denn diese können ihr Geschlecht wechseln (was zB Frösche auch können). Übertragen auf TF/IDF und WDF/IDF bedeutet das: wir sehen nicht 97% des Areals, sondern weniger als 1% (die Top 10 oder Top 100 der Suchergebnisse) und wissen aber nicht, was im Rest unserer Suchergebnisseite schlummert. Dennoch versuchen wir auf Basis dieses kleinen Teils etwas vorherzusagen.
Heißt das nun, dass TF/IDF oder WDF/IDF Quatsch sind? Nein, bisher habe ich nur gezeigt, dass diese Werte nicht unbedingt etwas damit zu tun haben, was eine Suchmaschine intern für Werte hat. Und das ist nicht mal eine neue Information, sondern bereits von Karl und manchen Toolanbietern auch so dokumentiert. Daher schauen wir uns im nächsten Teil etwas genauer an, ob wir eine Korrelation zwischen TF/IDF bzw WDF/IDF und Position auf der Suchergebnisseite finden können oder nicht.
Say it with data or it didn’t happen
In dem beigefügten R-Notebook habe ich zur Veranschaulichung ein Beispiel gewählt, dass uns alle (hoffentlich) an die Schule erinnert, und zwar habe ich einen kleinen Corpus von Goethe-Gedichten gebastelt (hier habe ich wenigstens keine Copyright-Probleme, bei den Suchergebnissen war ich mir nicht ganz so sicher). Etwas mehr als 100 Gedichte, eines davon kann ich nach 30 Jahren immer noch auswendig. In diesem kleinen wunderbaren Corpus normalisiere ich erst einmal alle Wörter, indem ich sie alle klein schreibe, entferne Zahlen, entferne Punkte, Kommata, etc und entferne Stopwörter.
Zwar gibt es in R eine Library tm, mit der man TF/IDF wie auch TF (normalisiert)/IDF berechnen kann, aber, Skandal (!!!), nix zu WDF/IDF. Vielleicht baue ich dazu selber mal ein Package. Aber zu Veranschaulichungszwecken habe ich einfach mal alle Varianten selber gebaut und nebeneinander gestellt. Ihr könnt also in meinem Code selber nachvollziehen, was ich getan habe. Schauen wir uns mal die Daten an für die ungestemmte Variante:

Wir sehen hier schon einmal, dass sich das “Ranking” verändern würde, wenn wir nach TF/IDF oder TF (normalisiert)/IDF sortieren würden. Es gibt also schon mal einen Unterschied zwischen WDF/IDF und den “klassischen” Methoden. Und nun schauen wir uns die Daten einmal für die gestemmte Variante an:
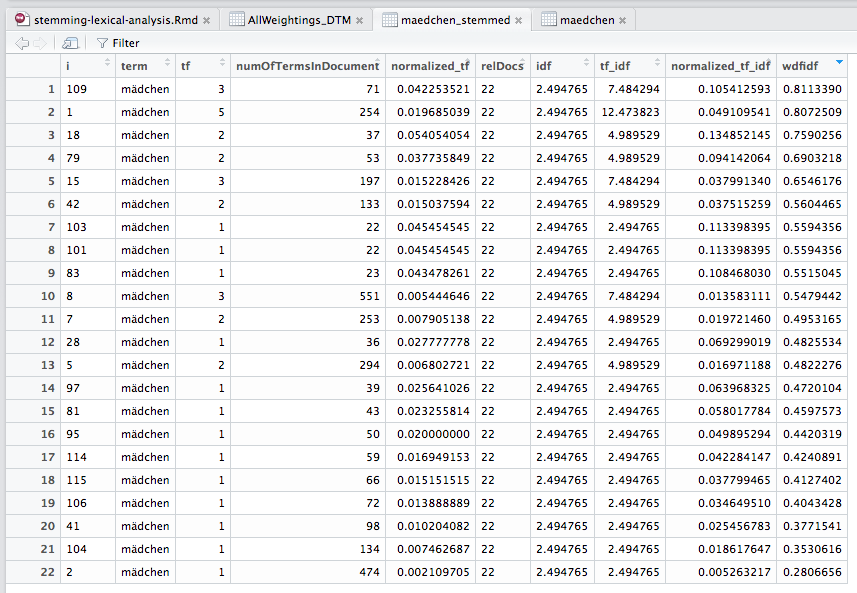
Wir sehen, dass sich zwei Dokumente in die Top 10 reingemogelt haben, und auch, dass wir plötzlich 22 anstatt 20 Dokumente haben. Das ist logisch, denn aus einem Begriff mit zwei oder mehr verschiedenen Stämmen kann nun einer geworden sein. Wir sehen aber auch sehr schnell, dass sich alle Zahlen verändert haben. Denn nun haben wir eine andere Basis. Mit anderen Worten, was auch immer SEOs aus WDF/IDF lesen, die Werte entsprechen mit hoher Wahrscheinlichkeit nicht dem, was tatsächlich bei Google passiert. Und noch mal: Das ist keine Neuigkeit! Karl Kratz hat das bereits gesagt, und auch einige Tools sagen das in ihren Glossaren. Nach meinem Vortrag aber wirkte es so als hätte ich gesagt, dass Gott nicht existiert
Und vielleicht ist es ja auch so, dass allein die Annäherung schon funktioniert. Das schauen wir uns in den nächsten Teilen über Data Science und SEO an.
War das schon Data Science?
Puh. Nee. Nicht wirklich. Nur weil man mit R arbeitet, heißt das noch nicht, dass man Data Science betreibt. Aber wir haben uns zumindest etwas warm gemacht, indem wir wirklich verstanden haben, wie unser Werkzeug tatsächlich funktioniert.