Da gerade die Canon 5d Mark IV herausgekommen ist, wird auch die 5d Mark III erschwinglich. 1.500€ für maximal 30.000 Auslösungen wurde mir geraten, aber wenn man sich die angebotenen Kameras bei eBay und den einschlägigen Foren ansieht, dann scheint der Preis viel höher zu sein. Doch was ist der faire Preis? Mit ausreichend Daten kann dieser durch Regression ermittelt werden.
Gehen wir zunächst mal davon aus, dass eine Kamera umso günstiger wird, je mehr Auslösungen sie hat. 150.000 Auslösungen ist die erwartete Lebensdauer des Auslösers bei der 5d Mark III, ein neuer Auslöser inklusive Arbeit kostet ca 450€ (nicht verifiziert). Doch schauen wir uns erst mal an, wie die Daten aussehen. Ich habe von den verschiedenen Plattformen die Preise und Auslösungen von knapp 30 Angeboten herausgesucht, das berücksichtigt also nicht, wie gut die Kamera äußerlich ist oder welches Zubehör dabei ist. Diese Daten werden in R eingelesen und auf ihre Merkmale untersucht:
Wir haben einen Durchschnittspreis von 1.666€ und eine durchschnittliche Anzahl von Auslösungen von 85.891. Das ist weit entfernt von den 1.500€ bei 30.000 Auslösungen. Auch beim Median sieht es nicht viel besser aus. Nun starten wir die Regression und bilden ein Regressions-Modell mit der Funktion lm und schauen uns die Details an mit dem Befehl summary(MODELLNAME):
Hieraus können wir schon eine Funktion bilden:
Preis = -0,001749x+1816 wobei x die Anzahl der Auslösungen ist. Eine Kamera mit 30.000 Auslösungen sollte also 1.763,53€ kosten, eine Kamera mit 100.000 Auslösungen immer noch 1.614€. Schauen wir uns noch den Plot dazu an:
Wie man schön sehen kann haben wir einige Ausreißer dabei (übrigens nicht wegen tollen Zubehörs oder einer Wartung etc), die das Modell etwas “verbiegen”. Eine Kamera mit knapp 400.000 Auslösungen und einem Preis von immer noch 1.000€ hatte ich bereits rausgenommen.
Leider kann man die Anzahl der Auslösungen nicht automatisiert aus den Portalen auslesen, da sie immer vom Benutzer manuell eingegeben wird. Ansonsten könnte man für jedes Kameramodell ein schönes Tool daraus bauen
Heutige Prozessoren haben meist mehr als einen Kern, aber die meisten Programme nutzen nur einen. Oft ist es egal, der Rechner ist auch so schnell genug. Aber dann kommt man manchmal in Bereiche, wo man sich ärgert, dass man nur einen Kern nutzen kann. Vor allem bei den UNIX-Befehlen, die als GNU-Version zum Teil mehrere Kerne ausnutzen können, langweilt sich ein Teil meiner Mac-CPU während der andere zu 100 Prozent ausgelastet ist. In meinem Beispiel geht es um eine Text-Datei mit 8.6 GigaByte (nicht MegaByte :-), die ich sortieren und verarbeiten muss. Was wäre, wenn man mehr als einen Kern nutzen könnte?
Wie viele Kerne hat mein Mac überhaupt? Einmal Terminal öffnen und dann
sysctl -n hw.ncpu
eingeben, schon wird die Anzahl der Kerne ausgespuckt. Naja, nicht ganz. Es ist die Anzahl der Threads. Mein MacBook Air hat einen Dual-Core-Prozessor, es werden aber 4 Kerne angezeigt. Und leider kann die Mac OS X-Version von sort nur einen Kern nutzen. Abhilfe schafft Homebrew:
…und schon hat man die GNU-Version von sort, die mit gsort aufgerufen werden kann. gsort versteht den Parameter –parallel=n, mit meinen vier Kernen also…
gsort –parallel=4 datei.txt
Und siehe da, ich habe über 350% CPU-Auslastung Achtung: Das funktioniert nicht, wenn gsort in einer Pipe auf den Output eines anderen Befehles wartet.
Im September 2015 stand ich für Google auf einer großen Bühne in Berlin und zeigte neben der Sprachsuche auch die Vorteile der neuen Features von Google Trends. Es ist ein nützliches Werkzeug, bietet aber auch viel Potential für Missverständnisse, mit denen hier aufgeräumt werden soll. Suchanfragen werden in <> Klammern gesetzt.
Dieser Text wurde am 27. Mai 2020 aktualisiert, da Google die Hilfe zu Google Trends überarbeitet hatte.
1. Missverständnis: Die Basis der Daten von Google Trends
Google Trends basiert nicht auf allen Suchanfragen, die bei Google eingegeben werden, sondern auf einem repräsentativen Sample:
Google Trends-Daten spiegeln die Suchanfragen wider, die Nutzer jeden Tag bei Google stellen. Möglicherweise umfassen sie jedoch auch unregelmäßige Suchaktivitäten wie z. B. automatisierte Suchanfragen mit dem Ziel, unsere Ergebnisse zu verfälschen. […] Obwohl wir Mechanismen zur Erkennung und Filterung solcher Aktivitäten haben, werden diese Suchanfragen aus Sicherheitsgründen mitunter in Google Trends gespeichert: Würden wir diese grundsätzlich herausfiltern, wüssten die Ersteller solcher Anfragen, dass wir ihnen auf der Spur sind. Dies würde es dann wiederum erschweren, solche Aktivitäten aus anderen Google-Suchprodukten herauszufiltern, bei denen eine möglichst genaue Abbildung der reellen Daten entscheidend ist. Aus diesem Grund sollten Nutzer von Google Trends-Daten verstehen, dass diese kein exaktes Abbild der Suchaktivitäten darstellen.
Google Trends filtert bestimmte Arten von Suchanfragen heraus, zum Beispiel […] Suchanfragen von wenigen Personen: Trends analysiert nur Daten für beliebte Suchbegriffe. Begriffe mit niedrigem Suchvolumen erscheinen daher als 0
Eine Definition, ab wann ein Begriff beliebt ist existiert nicht. Und nur mal so nebenbei: Ist noch niemandem aufgefallen, dass bei den populärsten Suchbegriffen, die in Zeitungen auf Basis von Google Trends veröffentlicht werden, nie hormongesteuerte Begriffe auftauchen? 🙂 Die erste Erkenntnis: Wir reden hier von Trends, nicht mehr und nicht weniger.
2. Missverständnis: Linien und Suchvolumina – Es existieren keine absoluten Zahlen
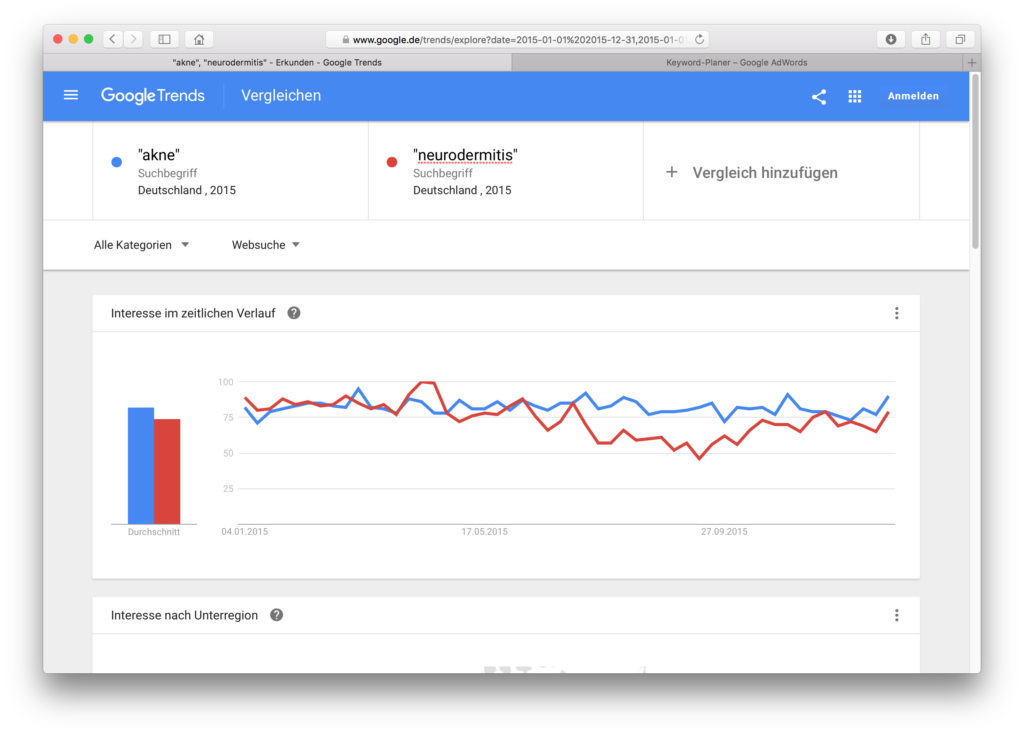
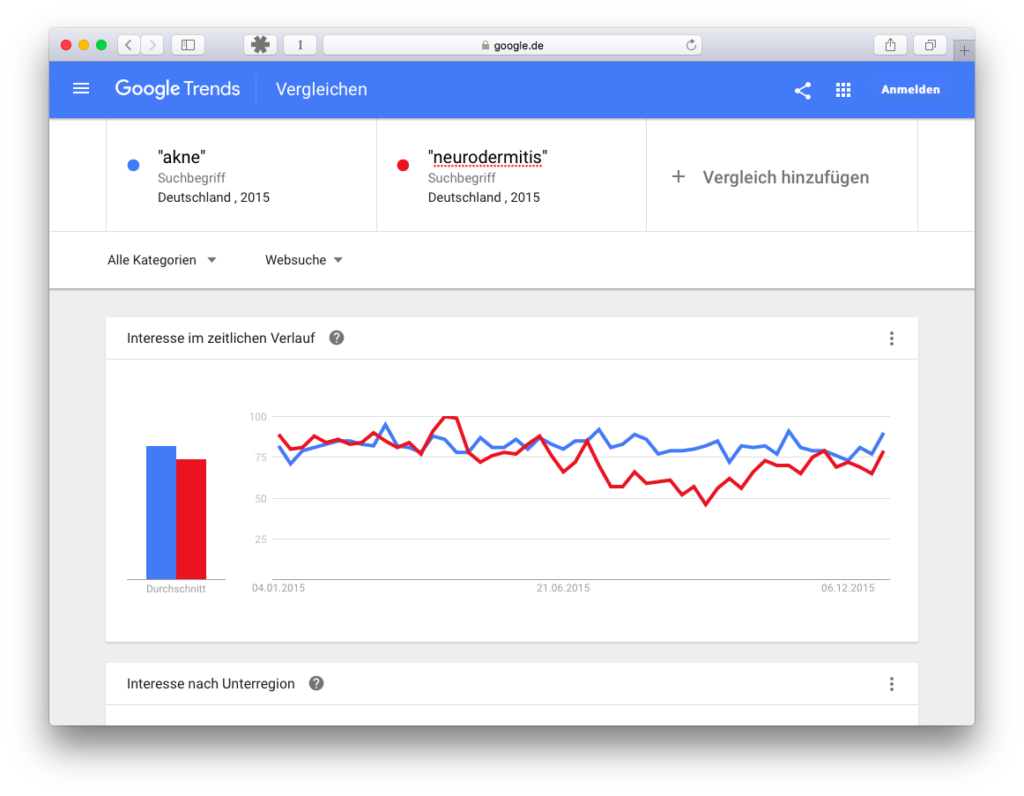
Dies ist das größte und das fatalste Missverständnis. Wenn eine Kurve über der anderen liegt, dann bedeutet das nicht, dass häufiger nach dem einen Begriff gesucht wurde als nach dem anderen. Die Linien geben keine absoluten Zahlen wieder. In diesem Beispiel suchen wir nach Akne und nach Neurodermitis (ich erkläre weiter unten, warum ich das in der Maske in Anführungszeichen schreibe) für das Land Deutschland im Jahr 2015. Akne und Neurodermitis wechseln sich ab beim Suchinteresse, Akne scheint aber häufiger ein höheres Suchinteresse vorweisen zu können:
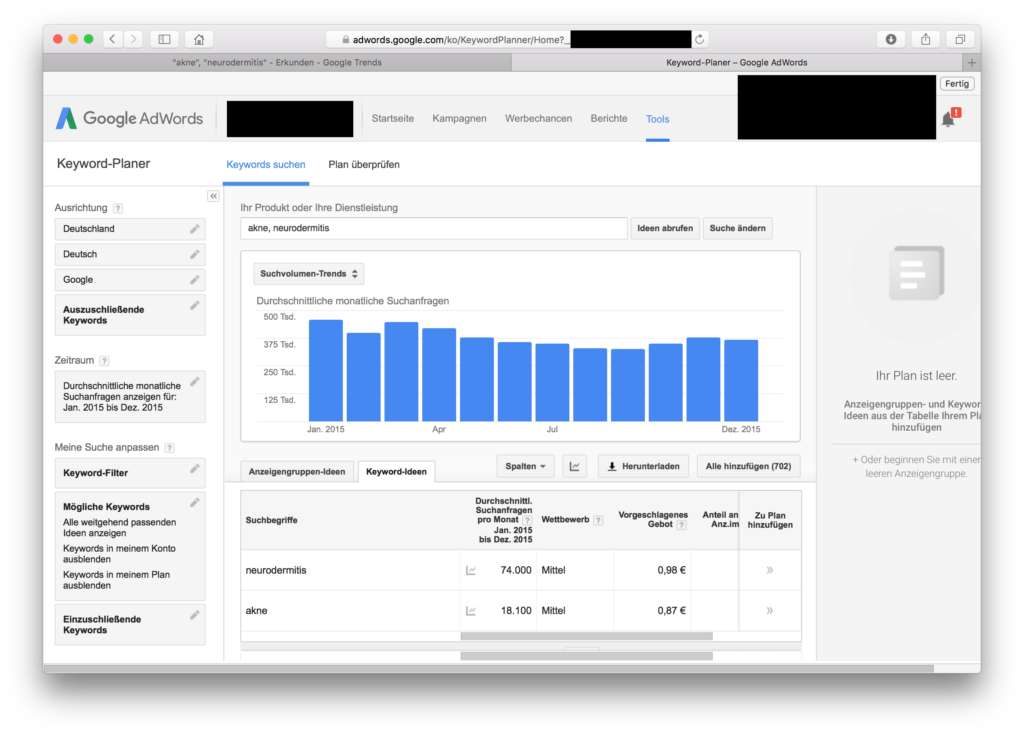
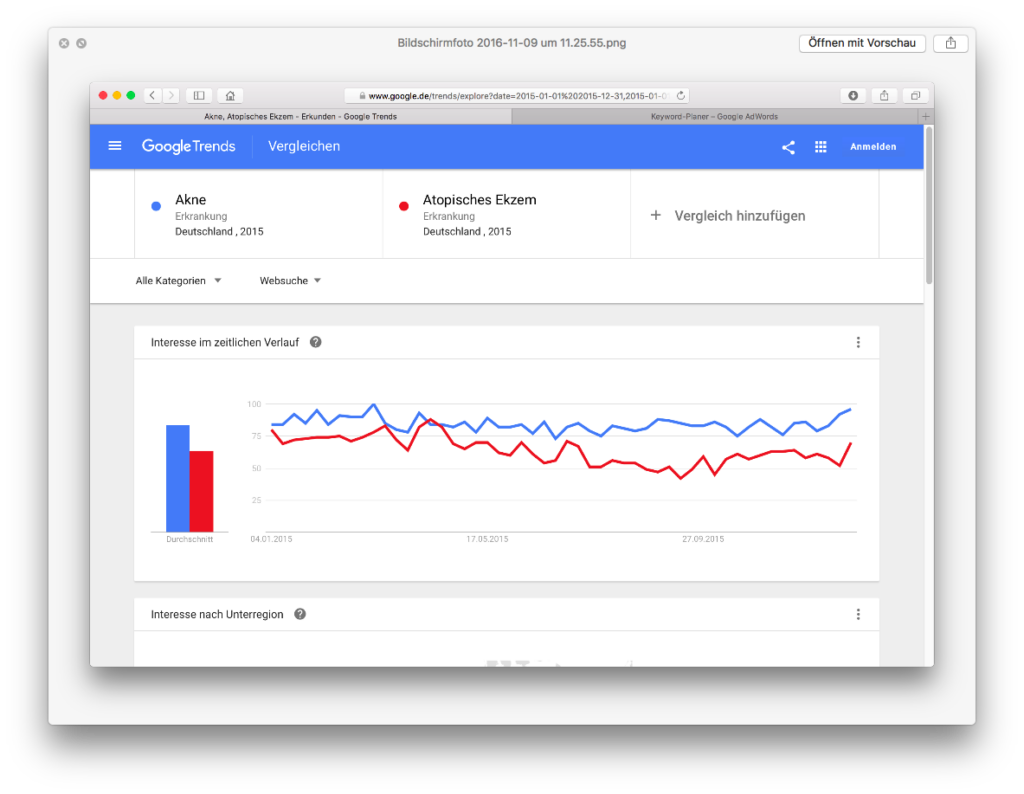
Und dann schaue ich mir die Daten einmal im Google AdWords Keyword Planer an, für den gleichen Zeitraum, für das gleiche Land:
Interessant ist hier nicht die Grafik (ich hab den Screenshot nur gemacht, damit man sieht, dass ich im gleichen Land für den gleichen Zeitraum suche), sondern die beiden Zeilen darunter, wo wir das durchschnittliche Suchvolumen pro Monat sehen. Neurodermitis liegt weit über Akne, 74.000 zu 18.100.
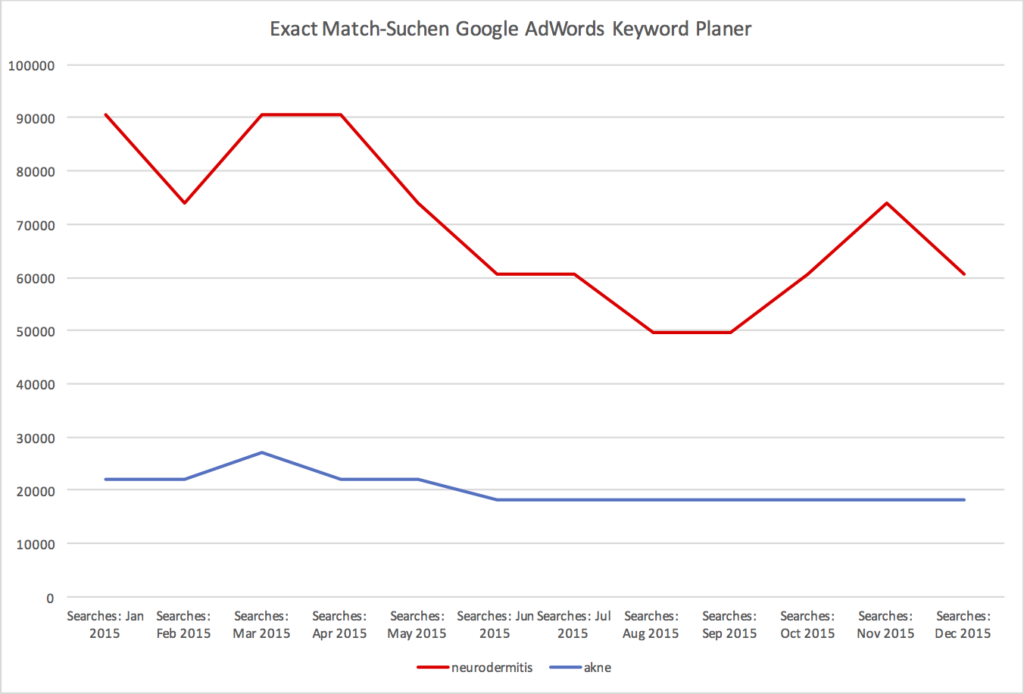
Durchschnittswerte können uns in die falsche Richtung führen, also schauen wir uns auch noch die Daten auf die einzelnen Monate geplottet an:
Wir sehen zu der Google Trends-Grafik eine Ähnlichkeit, nämlich dass die Suchen für Neurodermitis ab Mai bzw Mitte des Jahres runtergehen und ab September wieder hoch. Und, das wird später wichtig, Neurodermitis kommt bei Google Trends an die 100 dran, Akne erreicht diesen Punkt aber nie. Ansonsten berühren sich die Kurven der AdWords-Daten nicht ein einziges Mal wie in Google Trends. Sie sind weit auseinander. Zweite Erkenntnis also: Wir können anhand von Google Trends-Daten nicht behaupten, dass ein Begriff häufiger gesucht wird als ein anderer (dafür wird Google Trends allerdings häufig mißbraucht). Google Trends bietet keine absoluten Zahlen. Sorry.
3. Missverständnis: Was ist eine Suchanfrage?
Gibt man bei Google ein oder im Google AdWords Keyword Planer, so sucht man nur nach diesem Begriff. Gibt man bei Google Trends ein, so wird automatisch auch nach anderen Begriffen mitgesucht, selbst wenn man nicht ein Thema ausgewählt hat, sondern nur diesen Suchbegriff (siehe die [Hilfe][4]). So kann man zwar etwas einschränken, indem ein Begriff in Anführungszeichen gesetzt wird (“akne creme”), aber das schränkt nur ein, dass nicht nach gesucht wird, es könnte aber miteingeschlossen werden. Welche Suchbegriffe miteingeschlossen werden, wird nicht gesagt. Ein “Exact Match” existiert nicht, siehe wieder [die Hilfe][5].
Schauen wir uns einmal die Unterschiede an:
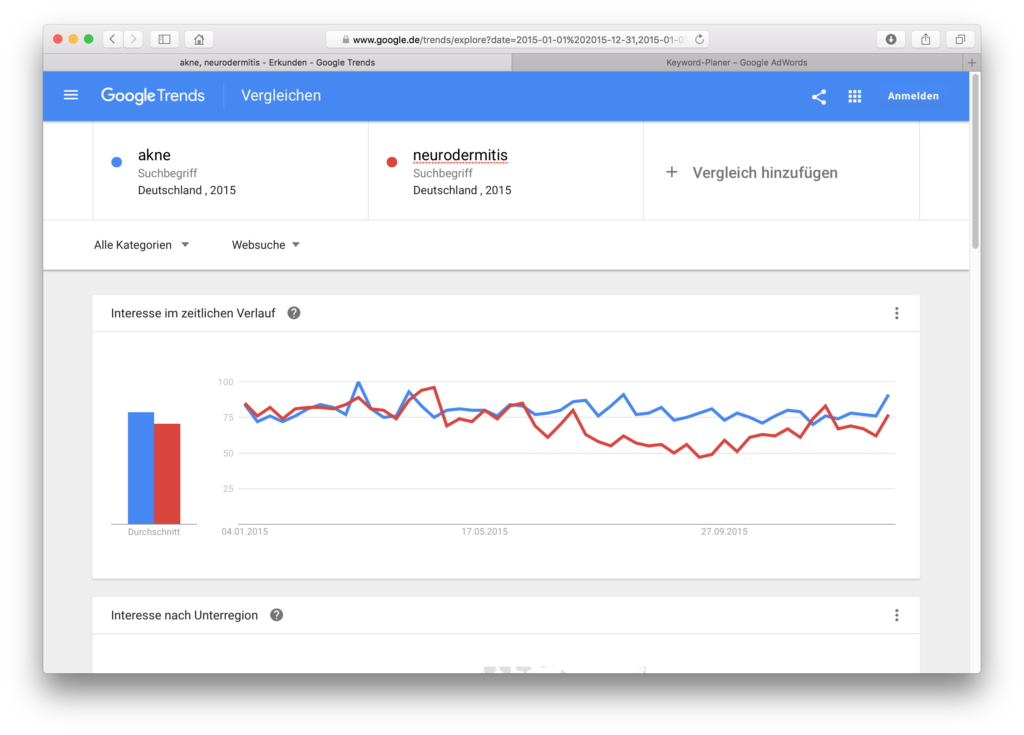
In diesem Beispiel vergleichen wir die Suchbegriffe und . Fügen wir Anführungszeichen hinzu, dann sehen die Kurven etwas anders aus:
Keine riesengroße Änderung, aber es gibt einen Unterschied, den wir uns wieder für später merken: Geben wir die Begriffe ohne Anführungszeichen ein, dann kommt an die 100, mit Anführungszeichen kommt an die 100.
Verwunderlich ist es schon, denn bei einem Einwortbegriff, wo keine Synonyme mitgesucht werden, kann es auch keine unterschiedlichen Reihenfolge für die Wörter in der Suchanfrage geben. Dieses Phänomen können wir uns nicht erklären.
Schauen wir uns zuletzt noch an, was passiert, wenn wir das automatisch identifizierte Thema “Erkrankung” auswählen (Hinweis: Google macht aus automatisch , was die medizinische Bezeichnung für Neurodermitis ist):
Hier werden die Trend-Daten von Begriffen aggregiert, die in die Gruppe der Erkrankung passen. Das “Suchinteresse” an Neurodermitis kommt zwar im Februar 2016 an das Thema Akne heran, aber Akne als Thema scheint ein größeres Suchinteresse zu haben als Neurodermitis. Auch hier wissen wir nicht, welche Begriffe in der Gruppe zusammen gefasst werden. Es könnte also sein, dass die unterschiedlichen Daten daher kommen, dass in Google Trends für beide Begriffe zusätzliche Begriffe einbezogen werden, für den Begriff Akne aber Begriffe, deren Suchinteresse anders gestaltet ist und darum das Resultat verändert. Sehr plausibel klingt das aber nicht. Dritte Erkenntnis: Google Trends-Daten sind nicht vergleichbar mit AdWords-Daten, weil die Eingabe unterschiedlich interpretiert und angereichert wird und wir bei Google Trends nicht wissen womit.
Die Unterschiede zwischen AdWords und Trends sind somit aber wahrscheinlich immer noch nicht erklärt. Was könnten andere Gründe sein?
4. Missverständnis: Alles, was steigt oder fällt, ist ein Trend in Google Trends
Jetzt wird es etwas mathematisch. Google Trends bietet keine absoluten Zahlen, alle Daten werden auf einer Skala von 0 bis 100 abgebildet. Und jetzt erinnern wir uns wieder an die beiden Hinweise oben, als eine der beiden Suchanfragen-Kurven die 100 berührte. Das Berühren der 100 hat eine große Bedeutung, denn von diesem höchsten Punkt des Suchinteresses aus wird alles andere berechnet!
Aber es wird noch komplizierter: Zunächst einmal ist das Suchinteresse das Suchvolumen für einen Begriff geteilt durch das Suchvolumen aller Begriffe. Da wir die Basis nicht kennen (also wie viele Suchen es insgesamt gab an dem Tag) und sich diese Basis jeden Tag ändert, kann es sein, dass sich die Linie des Suchinteresses für einen Begriff ändert, obwohl jeden Tag gleich oft nach diesem Begriff gesucht wird. Der Zeitpunkt, an dem das Maximum dieser Ratio Suchbegriff/Alle Suchbegriffe erreicht wird, wird zum Maximum, also 100 im Google Trends-Diagramm, und alle anderen Werte, auch die von Vergleichsbegriffen, werden normalisiert davon abgeleitet. Und nur für den gewählten Zeitraum. Wird dieser geändert, so wird auch das Maximum wieder neu berechnet. Dies führt zu Unterschieden, die dazu verleiten könnten, dass man sich genau den Zeitraum aussucht, der zu dem passt, was man gerne verkaufen möchte Beispiele:
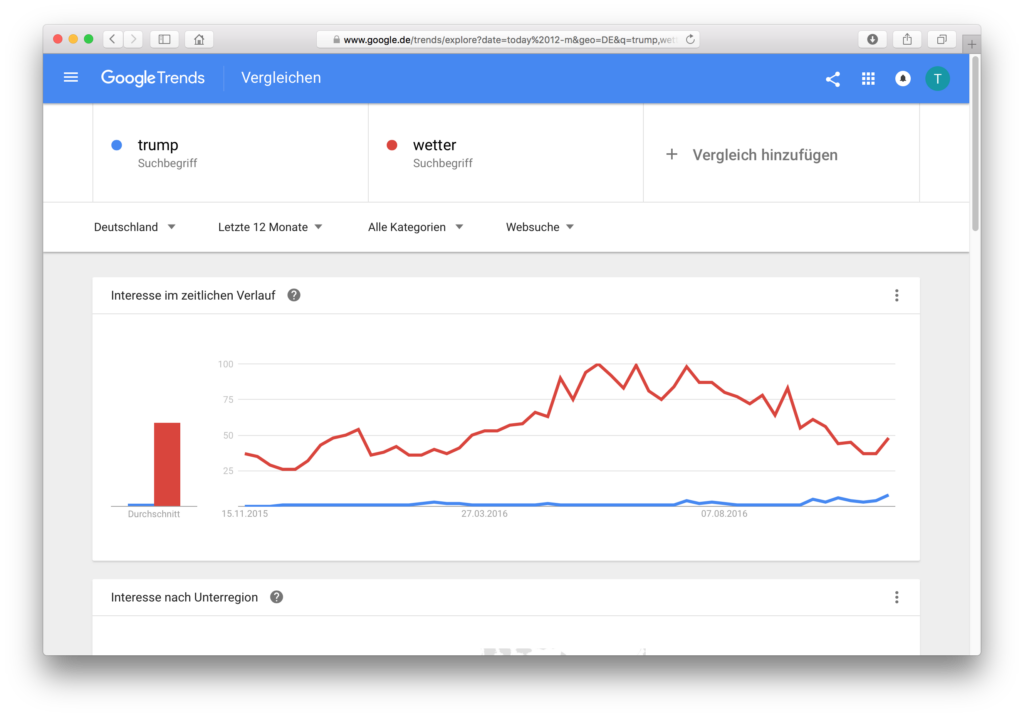
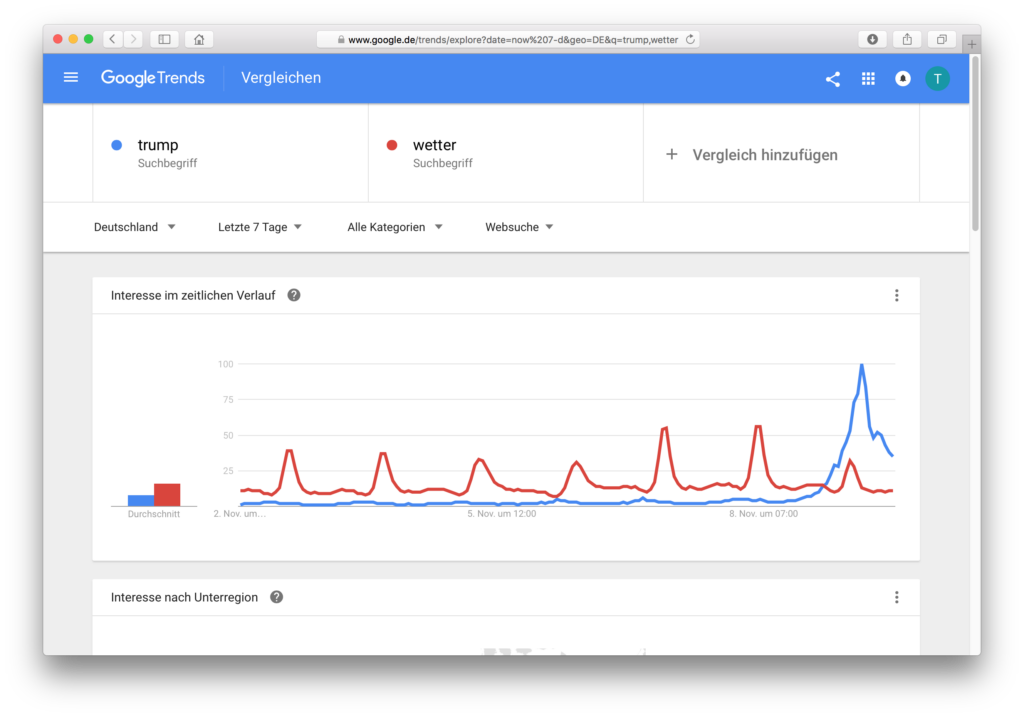
Fehlinterpretation: Im Vergleich zum Wetter ist das Interesse an Trump kaum gestiegen in den letzten 12 Monaten
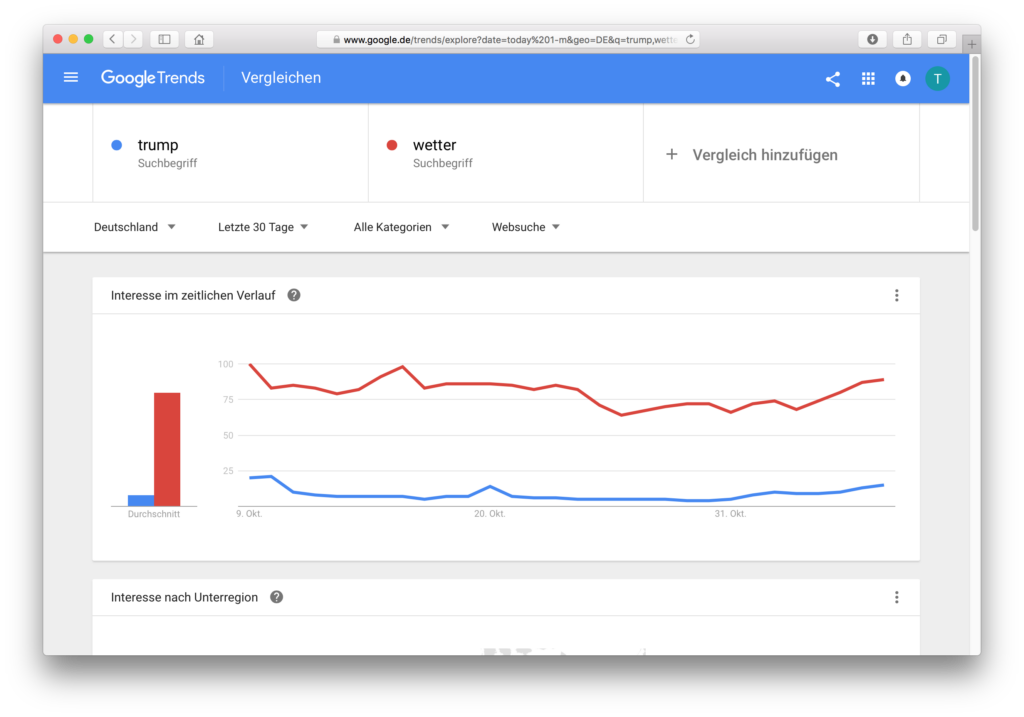
Fehlinterpretation: In den letzten 30 Tagen ist das Interesse an Trump nicht so stark gestiegen wie das an Wetter. Tatsächlich sind die Daten von Google Trends aber noch nicht aktualisiert, der Wahltag sowie der Vortag fehlen.
Das Diagramm für die letzten 7 Tage: Können wir nun behaupten, dass Trump häufiger gesucht wurde als das Wetter?
Diese letzten Grafiken sind sehr schön weil sie einleuchtend zeigen, dass die Deutschen nicht unbedingt weniger nach dem Wetter gesucht haben, aber die Suchanfragen zum Begriff Trump am 9.11 einen deutlich höheren Anteil in der Population aller Suchen hatte im Vergleich zu den 6 Tagen davor. Von diesem einen Maximum wird alles andere berechnet. Über 30 Tage hinweg hatte das Wetter aber ein Maximum (EDIT: Weil der Tag nach der Wahl noch nicht drin war und es auch zwei Tage später nicht ist! Dank an Jean-Luc für diesen Hinweis!), und dann wird von da aus gerechnet. Darum können sich diese Daten so unterscheiden.
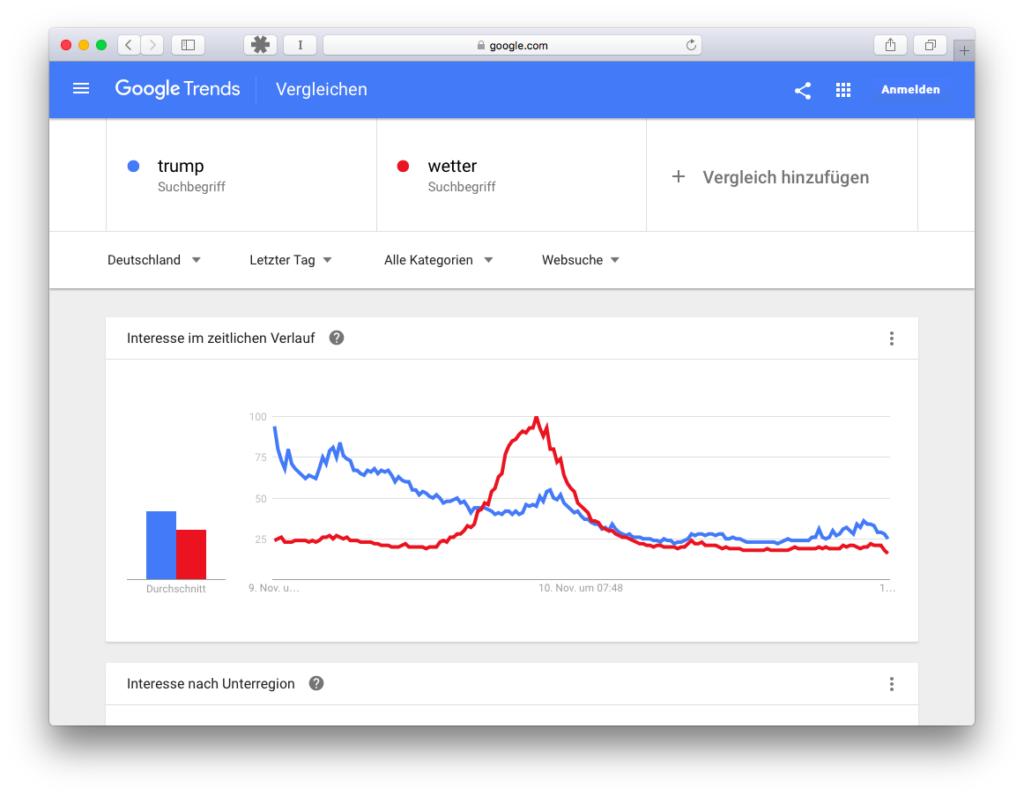
Edit: Schaut man einen Tag nach der Wahl und schaut nur auf den letzten Tag (also Daten, die ca 10 Minuten alt sind), dann sieht das Ergebnis so aus:
Wieder ist das Wetter höher, obwohl Trump nah dran kommt. Oder? Nun ja, ich habe diesen Screenshot abends erstellt, und der Peak an Trump-Suchen fand wohl vor mehr als 24 Stunden statt. Es ist sehr wahrscheinlich, dass ich ein anderes Bild bekommen hätte, wenn ich heute morgen die gleiche Abfrage getätigt hätte.
Was nehmen wir aus diesem Missverständnis mit?
Der Zeitraum der Beobachtung ist immens wichtig, und man sollte keiner Trends-Grafik glauben, ohne sich mehrere Zeiträume angeschaut zu haben
Alle Beobachtungen gehen vom Maximum aus und sind dann relativ von diesem Maximum aus zu sehen, sind aber gleichzeitig abhängig vom Gesamtvolumen aller Suchanfragen, das wir nicht kennen.
Es ist vielleicht nicht so offensichtlich in den Grafiken, aber in der 7-Tage-Grafik wird auf Stundenbasis gerechnet, in der 30-Tage-Grafik auf Tagesbasis, in der 12-Monate-Grafik auf Wochenbasis. Der Google AdWords Keyword Planer liefert Daten auf Monatsbasis aus. Auch deswegen sind die Daten nicht vergleichbar.**
Learning: “Die letzten 30 Tage” bedeutet nicht unbedingt, dass auch wirklich die letzten 30 Tage drin sind
5. Missverständnis: Ohne Benchmark ist Google Trends wertlos aka Alles, was steigt oder fällt, ist ein Trend in Google Trends, Teil 2
Kommt darauf an, wie man Trend definiert. Nach dem Brexit-Votum fand ein Journalist durch Google Trends heraus, dass die Briten erst nach dem Votum gegoogelt hätten, was der Brexit denn bedeutet, viele Zeitungen schrieben darüber, und erst [nachdem ein Datenanalyst geschaut hatte][13], was da wirklich geschah, ruderten alle zurück. Ja, es wurde mehr danach gesucht, basierend auf… siehe das 4. Missverständnis Aber im Vergleich zu einer populären Suchanfrage war da nur ein Zucken. Daten müssen immer in einen Kontext gesetzt werden, um ein Gefühl dafür zu bekommen, was das wirklich bedeutet. Ich nutze, obwohl ich kein Fußballfan bin, gerne die Suchanfrage , aber auch , um zu schauen, wie relevant ein Begriff wirklich ist.
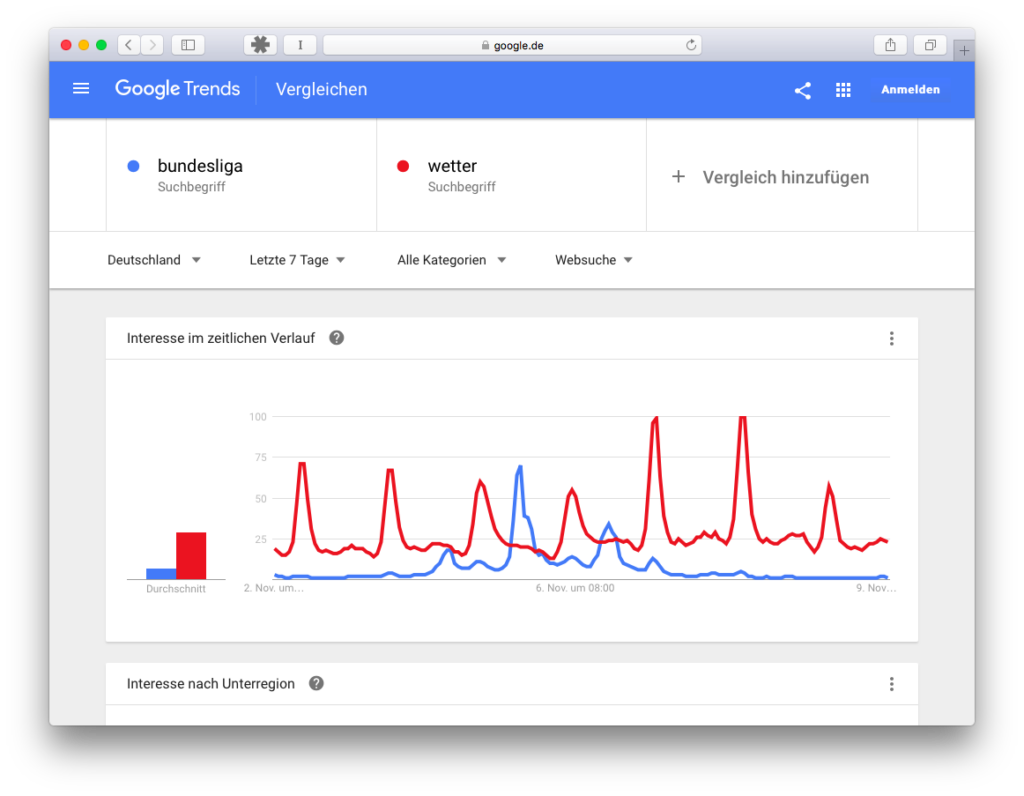
Nach dem Wetter wird immer gesucht, allerdings ist auch hier eine gewisse Saisonalität zu beobachten, Bundesliga wird vorrangig von einem Teil der Bevölkerung gesucht, und das auch nur saisonal, aber auch hier können interessante Beobachtungen gemacht werden.
Wir sehen hier wunderbar das Freitagsspiel (erste kleine Delle in der blauen Kurve), die Samstags-Spiele (größte Delle in der blauen Kurve) und dann wieder kleinere Dellen für die Sonntagsspiele. Das Wetter hat hier die höchsten Ausschläge, vor allem am Montag und am Dienstag (vielleicht wegen des Schnees?). Wurde also häufiger nach dem Wetter gesucht? Nein, nicht unbedingt! Da hier auf Stundenbasis gerechnet wird wird alles vom Maximum am 8.11., 5 und 6 Uhr gerechnet, zu dieser Zeit war das Suchinteresse (Suchanfrage/alle Suchanfragen) am höchsten, und alles andere wird relativ berechnet. Es kann also theoretisch sein, dass am Samstag nachmittag häufiger nach Bundesliga gesucht wurde als nach Wetter am 8.11., die Gesamtpopulation der Suchanfragen aber höher war! Was nehmen wir mit? Wir benötigen immer einen Bezugspunkt, einen Benchmark, etwas, womit wir das Suchinteresse vergleichen können. Und am besten wissen wir auch etwas über diesen Bezugspunkt, wie zum Beispiel in diesem Fall, dass es geschneit hat, und es deswegen Ausreißer gab.
6. Bonus-Missverständnis und Auswirkungen von Fehlinterpretationen
Ein großes Missverständnis ist, abgesehen von der Funktionsweise von Google Trends, die Annahme, dass Nutzer wirklich ALLES nur bei Google suchen. So hat Google einige Suchanfragen an Amazon verloren, und wenn man sich das eigene Suchverhalten ansieht, dann geht man nicht mehr für jede Suche zu Google, sondern gleich dahin, wo man weiß, dass man sofort findet, was man sucht. Sei es die Buchhandlung um die Ecke mit Online-Bestellservice, sei es der Pizzadienst oder Klamottenladen. Tatsächlich spiegeln sich manche Trends erst gar nicht in den Google-Tools, weil sie auf Pinterest und anderen Plattformen stattfinden. Es kann also nicht von Google-Suchanfragen auf die Bedürfnisse und Wünsche aller Menschen geschlossen werden.
Was kann Schlimmes passieren, wenn man die Daten fehlinterpretiert? Meine Erfahrung zeigt, dass schlimmstenfalls lieber falsche Daten genommen werden als gar keine zu haben. Das führt dazu, dass Budget-Entscheidungen eventuell falsch getroffen werden. Es kann aber noch schlimmer werden. Wenn zum Beispiel wissenschaftliche Artikel Google Trends verwenden, hier für Analysen im Finanzmarkt oder hier in der Gesundheitsforschung, ohne zu verstehen, wie das Tool funktioniert. Wenn Wissenschaftler das nicht einmal verstehen beziehungsweise sich nicht die Zeit dafür nehmen, die Funktionsweise zu überprüfen, wie kann man das von dem Normalanwender verlangen? Das Journalismus-Beispiel wurde bereits im vorherigen Abschnitt beschrieben, auch hier würde man erwarten, dass Journalisten etwas genauer recherchieren. Angeblich soll Mark Twain mal gesagt haben:
Never let the truth get in the way of a good story.
7. Wie kann man Google Trends sinnvoll nutzen?
Wer absolute Zahlen benötigt kann nur den Google Ads Keyword Planer nutzen. Punkt. Alternativen wie keywordtool.io oder Tools mit integriertem Suchindex wie Sistrix liefern nur zum Teil richtige Daten.
Was hat Google Trends also was der Google Ads Keyword Planner nicht hat? Google Trends ist unfassbar aktuell, Daten sind innerhalb weniger Minuten drin. Man kann das Suchinteresse der Vergangenheit auf Stundenbasis nachvollziehen. Und zwar für mehr als 10 Jahre, anders als der Keyword Planner, wo es nur die letzten 4 Jahre sind.
Google Trends kann also sehr gut in Kombination mit dem Keyword Planer verwendet werden, zum Beispiel um zu verstehen, wann die besten Zeiten sind, um Kampagnen stärker auszusteuern.
Zusammenfassung
Der Mechanismus “Ich gebe zwei Begriffe in Google Trends ein und sehe, welcher populärer ist” funktioniert so einfach nicht. Das wird aus den Köpfen schwer herausbekommen zu sein, denn das Interface ist wunderbar intuitiv und verleitet förmlich zu dieser Interpretation, und komplett falsch ist sie ja auch nicht. Schwierig ist es, wenn auf Basis dieser Daten folgenschwere Entscheidungen getroffen werden sollen, hier sind zusätzliche Daten notwendig. Keyword Planer-Daten stehen nicht mehr jedem zur Verfügung, sind aber eh nicht direkt vergleichbar, da Google Trends-Daten nicht reine Begriffe vergleichen.
Und dennoch ist Google Trends mehr als nur eine Spielerei. Man muss bei all dem oben Gesagten nur etwas mehr Gehirnschmalz investieren, um eine richtige Story daraus zu bauen.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Jean-Luc Winkler says
November 2016 at 18:18 Hey Tom, sehr spannender Beitrag! Bei Absatz 4 betrachtest du die Daten „letzte 30 Tage“ und „letzte 7 Tage“. Die Daten der Darstellung „letzten 7 Tage“ beinhalten 7×24 Stunden ab der heutigen letzten vollen Stunde rückwirkend (Bsp: am 09.11. um 17:17 ist der letzte Datensatz vom 09.11. um 17;00h). Dieser Zeitraum umfasst den 09.11., an dem die -Kurve das starke Maximum anzeigt. Die Daten der Darstellung „letzte 30 Tage“ beinhalten 29 Tagessätze, beginnend ab vor-vor-gestern rückwirkend (Bsp: am 09.11. betrachtet, ist der letzte Datenpunkt der 06.11.). Somit ist der Tag, an dem die -Kurve am 09.11. das Maximum anzeigt nur in der „letzte 7 Tage“-Darstellung abgebildet, nicht in der „letzte 30 Tage“-Darstellung, richtig? Warten wir also noch bis übermorgen und gucken, ob dann ein Ausschlag in der -Kurve im Verhältnis zur -Kurve ist, der die -Kurve übersteigt. Beste Grüße, Jean-Luc
Tom says
November 2016 at 20:44 Sehr guter Punkt, ich ergänze das!
Olaf Kopp says
November 2016 at 11:23 Hi Tom, danke für diesen sehr erhellenden Beitrag. Mir sind die Differenzen zwischen Keyword Planer und Google Trends jetzt schon mehrmals über den Weg gelaufen. Ich finde es sehr ärgerlich, dass Google hier sehr Intransparenz und wie bei anderen Dingen auch nicht Konsistent ist was Datengrundlagen und weiteres angeht…
Tom says
November 2016 at 11:33 Hallo Olaf,
tatsächlich ist (fast) alles in der Hilfe erklärt, nur macht sich kaum jemand die Mühe, diese auch zu lesen, weil es halt so einfach aussieht
LG
Tom
A>utonomes Trading says 18. März 2017 at 22:13 gebt mal im Trends ein fixes Startdatum und ein variables Enddatum ein und ladet dieses im CSV herunter und vergleicht das mal. Die Daten ändern sich nach Lust und Laune „Prozentual“ hin und her. Und wenn man z.B. nur 14 Tage herunter lädt, die Summe von Sonntag bis Samstag bildet, so sollte doch der gleiche Prozentuale Unterschied wie bei den Wochendaten heraus kommen. Es ist also auch noch für den gleichen Datensatz der Zeitpunkt der Datenabfrage entscheidend. (historcial random statistic dates)
S>argon says 3. April 2018 at 18:51 Vielen dank! Ich war gerade am staunen wie ist Suchvolumen auf einmal weit unter 100 gefallen, nachdem ich schon für das Keyword Seite fast fertig habe… Jetzt weiß ich wo die ganzen Leute abgeblieben sind!
Google Analytics hatte letztes Jahr seinen 10. Geburtstag, und in den letzten mehr als 10 Jahren durfte ich einiges an Erfahrung sammeln, was man beim Einsatz von Web Analytics-Systemen beachten muss. Hier sind meine 10 Basic-Tipps, angefangen mit den absoluten Basics, den Abschluss bilden dann die Basics für diejenigen, die auch wirklich was mit ihren Daten anfangen wollen
Nutze ein Tag Management System, vor allem bei komplexeren Konfigurationen (zum Beispiel Cross-Domain Tracking) ist das unabdingbar. Aber selbst wenn nur die hier beschriebenen Basics umgesetzt werden sollen, ist ein Tag Management System wichtig. Die meisten Systeme bieten eine Preview an, so dass nicht am offenen Herzen operiert werden muss. Und wenn Du Deinem Web Analytics-Menschen keinen Zugang zum Verändern des Analytics-Codes geben willst, dann ist ein Tag Management System sowieso Pflicht.
Wo wir gerade dabei sind: Der Google Tag Assistant ist eine gute Ergänzung, wenn Du den Tag Manager und/oder Google Analytics nutzt.
Teste alles, was Du tust, mit den Echtzeit-Berichten, sofern es nicht über den Tag Manager und den Tag Assistant getestet werden kann.
Nutze die Adjusted Bounce Rate. Hieran führt nichts vorbei. Die Absprungrate ist normalerweise so definiert, dass ein Absprung gezählt wird, wenn ein Benutzer auf die Seite kommt und sie “sofort” wieder verlässt. “Sofort” ist dann je nach Definition und System irgendetwas zwischen 5 und 10 Sekunden. Bei Google Analytics ist es so, dass ein Bounce als solcher gezählt wird, wenn ein Benutzer auf eine Seite kommt und sich keine weitere Seite anschaut, egal wie lange er darauf war. Er ist also vielleicht gar nicht wirklich gebounced/abgesprungen, sondern hat sich die ganze Seite durchgelesen, und nachdem sein Informationsbedürfnis befriedigt war, ist er wieder gegangen. Bei manchen Content-Seiten ist das ein ganz normales Verhalten. Aber es ist eben nicht wirklich ein Bounce. Ein Bounce bedeutet für mich, dass ein Benutzer die Landing Page als irrelevant betrachtet hat und deswegen sofort wieder gegangen ist. Und das ist eine Baustelle, die man erst dann erkennt, wenn man die richtige Bounce Rate konfiguriert hat.
Sei Dir darüber im Klaren, was der Sinn Deiner Seite ist. Da wärst Du auch alleine drauf gekommen? Ich habe zu oft erlebt, dass es in einer Firma sehr unterschiedliche Ansichten darüber gibt, warum eine Webseite existiert. Manchmal konnten sich die Teilnehmer eines Workshops in 2 Stunden nicht einigen. Warum existiert die Seite? Welche Rolle spielt sie in der gesamten Business-Strategie Deines Unternehmens? Ist es Abverkauf? Ist es Branding? Ist es Monetarisierung via Werbung? Wolltest Du einfach nur ein www auf dem Briefkopf haben? Hat Deine Seite mehrere Ziele? Auch ok. Schreib alle auf.
Wie kannst Du nun messen, ob die Geschäftsziele erfüllt werden? Dafür definierst Du die KPIs. Beispiel: Du willst etwas verkaufen, dann ist Dein Ziel die Anzahl der Conversions. Oder? Bei genauerem Hinschauen hast Du wahrscheinlich ein Umsatzziel (z.B. 1.000€ am Tag), und da hilft Dir die Anzahl der Conversions wenig, sofern Du nicht bei jeder Conversion den gleichen Betrag einnimmst. Für das Umsatzziel gibt es mehrere Stellschrauben, Traffic, Conversion Rate, Warenkorbwert, Retouren. Daraus ergeben sich Unterziele, wie zum Beispiel 2.000 tägliche Benutzer, eine Conversion Rate von mindestens 1% (was übrigens ein guter Standardwert ist), und ein durchschnittlicher Warenkorb von 50€ sowie eine Retourenrate von 0% (was sehr unrealistisch ist, sofern Du kein digitales Produkt verkaufst). Kommst Du nicht auf die 1.000€, so musst Du anhand der genannten KPIs analysieren, warum das so ist. Bei Branding-Seiten hingegen haben wir andere Metriken. Du willst Nutzer, die nicht sofort wieder gehen (siehe Adjusted Bounce Rate oben). Du willst Nutzer, die sich mit Deiner Seite auseinander setzen, also könnten Time on Site oder Pages per Visit gute Metriken sein. Wenn Du vor allem Nutzer erreichen möchtest, die Dich noch nicht kennen, so ist die Metrik Anzahl Neuer Nutzer interessant. Aber auch hier: Setze Dir Ziele. Wenn Du keine Ziele hast, dann ist jede Zahl egal. Sind 300.000 Besucher gut oder wenig? Ist ein Wachstum von 2% gut oder nicht so gut? Komplett egal, wenn Du keine Ziele hast.
Das Standard-Dashboard von Google Analytics ist relativ sinnfrei. Was sagt das Verhältnis von neuen zu wiederkehrenden Nutzern aus? Was machst Du mit dieser Information? Ganz ehrlich: Mit keiner der im Standard-Dashboard aufgeführten Informationen kannst Du tatsächlich etwas anfangen. Auf ein richtiges Dashboard gehören die tatsächlich wichtigen KPIs. Nutze die Galerie (in Google Analytics). Viele Probleme sind schon von anderen Nutzern gelöst worden.
Web Analytics (wie auch Datenanalyse generell) beginnt mit einer Frage. Die Antwort ist nur so gut wie Deine Frage. Beispiele für gute Fragen: Welcher Akquise-Kanal bringt mir am meisten Umsatz (und, viel wichtiger, lohnt es sich mehr davon haben)? Was ist mit den Kanälen los, die weniger Umsatz bringen? Welche demographischen Zielgruppen “funktionieren” (je nach Ziel) am besten, und welche Inhalte passen nicht für diese Zielgruppen? Liest meine Zielgruppe die Texte der Website bis zum Ende? Welche Elemente meiner Webseite erhöhen die Wahrscheinlichkeit, dass ein Benutzer bounced? An den Fragen sieht man schon, dass Web Analytics keine einmalige Angelegenheit ist, sondern kontinuierlich erfolgen muss.
Segmentierung ist das Killer-Feature in der Web-Analyse. Fast jede Fragestellung kann durch Segmentierung beantwortet werden. Beispiel: Segmentierung nach Mobil versus Desktop, Demographien, Akquise-Kanälen. Ohne Segmentierung ist Analytics ein zahnloser Tiger.
Und zum Abschluss das Killer-Basic: Du willst keine Daten. Was Du willst sind Informationen, mit deren Hilfe Du entscheiden kannst, was Du tun mußt. Analytics bietet Dir Daten, daraus ziehst Du Informationen, und daraus entstehen Aktionen. Daten -> Information -> Aktion, das ist das absolute Analytics-Mantra. Wenn es keine Aktion gibt, dann brauchst Du die Daten auch nicht. Mein ehemaliger Kollege Avinash nutzt dafür den So what-Test. Wenn Du nach dreimaligem Fragen von “Na und?” keine Aktion aus einem Datum hast, dann vergiss den KPI. Ich würde noch einen Schritt weiter gehen: Wenn Du keine Frage hast (siehe Punkt 8), aus deren Antwort eine Aktion erfolgt, dann war die initiale Frage falsch.
Diese Liste ist nicht unbedingt vollständig, aber mit diesen 10 Punkten kommt man schon verdammt weit. Feedback immer erwünscht.
Ich hatte den Machern von Scalable Capital schon am Freitag nach der Wahl Twitter-Kudos dafür geschickt, dass sie die Daten im Interface mehrmals täglich aktualisiert und nicht nur wie sonst die Daten des Vortags angezeigt haben. Transparenz schafft Vertrauen, denn natürlich möchte man wissen, was der Algo mit dieser Situation jetzt macht. Und tatsächlich, am Tag nach dem Referendum ging es bei mir nicht ganz so tief runter, um genau zu sein, es ging gar nicht runter, sondern rauf. Vergleiche ich mein Portfolio mit dem Dax, so lag der Dax an “meinem ersten Tag” (an dem alle Anlagen vom Algo gekauft waren) bei 9890€, heute liegt er gerade aktuell bei 9.500€, gestern schloss er mit 9268€ ab, und mit diesem gestrigen Minus muss verglichen werden. Dem gegenüber steht bei mir im Scalable Capital-Interface eine “zweitgewichtete Rendite” von 1,39% und eine “einfache Rendite” von 1,37%. Natürlich ist der Vergleich etwas unfair, schließlich wäre die Alternative kein reines DAX-Portfolio, aber auch der Dow Jones und die Euro Stoxx haben sich nach unten entwickelt. Aber generell hat der Algo hier gewonnen.
Aber wie genau hat er das gemacht? So die Aussage in der Mail von letzter Woche:
Unser dynamisches Risikomanagement hatte bereits in den letzten Monaten die Kundenportfolios in konservativere Anlagen umgeschichtet, sodass die Auswirkungen der heutigen Kurseinbrüche deutlich gemindert werden. Insbesondere die derzeit auf Staats- und Unternehmensanleihen fokussierte Positionierung trägt zur Stabilisierung bei.
Was die Mail verschweigt ist, welche Signale dazu geführt haben, dass umgeschichtet worden ist. Aber das wird wahrscheinlich geheim bleiben, eben so wie die Coca Cola-Formel.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Christoph says
August 2016 at 23:55 Hallo Tom,
bin auch Kunde bei SC und wollte mal im Internet schauen was andere User so berichten
Bezüglich deiner Suche nach einem „faireren“ Vergleichs-Benchmark, SC selbst benutzt dazu eine Mischung aus MSCI World (genauer gesagt den iShares Core MSCI World ETF) und Euro-Tagesgeld (per 1-Tages EONIA Satz). Steht alles in den Vertragsbedinungen, Abschnitt C 4 bis 6. ( https://de.scalable.capital/app/api/pdf/static?type=scalable_terms_and_conditions )
Diese beiden Anlagen stellen nun, je nach Portfolio VaR-Level, in unterschiedlichen Gewichtungsverhältnissen die Benchmark dar, mit denen sie (zumindest selbst) die Performance ihrer aktiven Assetallocation-Strategie vergleichen. Da der Tagesgeld-Zinssatz ja schon seit längerem, nun sagen wir mal, „vernachlässigbar“ ist, kannst du dir ja relativ leicht die Rendite des Benchmarks im Kopf ausrechnen, indem man einfach die (für dein jeweiliges VaR-Level zutreffende) prozentual anteilig gewichtete Performance des MSCI World anschaut.
Aber natürlich ist auch dieser Benchmark noch nicht unbedingt der wirklich „passendste“. Da das Aktienportfolio von SC auch Emerging Markets umfassen kann, bietet sich als Index ja eher der MSCI ACWI an, genauso wie auch (da das SC-Portfolio ja auch einen wesentlichen Anteil an Anleihen umfassen kann) statt Euro Tagesgeld lieber sowas wie der Barclays Euro Aggregate Bond Index (oder gleich Global Aggregate, da auch amerikanische Anleihen vertreten sind) eine bessere Vergleichsgrundlage liefert.
Was die „geheimen Formeln des Algos“ angeht, nunja, direkt den vollständigen Sourcecode veröffentlichen werden sie sicher nicht können, aber im Whitepaper ( https://de.scalable.capital/wp-content/static/Whitepaper_ScalableCapital_DE.pdf ) ab Kapitel 4 bekommt man schon etwas tiefere Einblicke in die Theorie-Hintergründe ihrer verwendeten Modelle. Setzt allerdings auch schon etwas voraus, dass man mit den angewandten Begriffen etwas anfangen kann, für weniger mathematisch veranlagte Betrachter bleibt das wohl trotzdem nur eine Blackbox, der man nun entweder vertrauen muss oder eben nicht.
Mein Tipp, falls du technische Spezialfragen hast, ruhig einfach mal eine Mail ans Unternehmen schreiben. Hatte ich auch vor ein paar Monaten gemacht und bekam von den Geschäftsführern prompte und tiefgründige Antworten. Irgendwann, falls der Anbieter mal zu groß werden sollte dass sich der Chef nicht mehr persönlich um Einen kümmert, gibts dann nur noch die Standardformulare von der Servicehotline, also versuchs lieber früher als später
Bezüglich der Asset-Allocation, in der Tat wurde kurz vor dem Brexit eigentlich nicht viel mehr umgeschichtet, es ist also nicht so als ob sie da irgendwas speziell „vorausgesehen“ hätten, sondern man war eigentlich schon die ganze Zeit davor hauptsächlich in Anleihen investiert, denn bereits seit Mitte 2015 waren die Aktienmärkte eher in einer volatileren Seitwärts/Abwärtsphase. Das allein, ist ja auch keine Kunst – eine statische Anleihen-lastige Allocation, um die Aktienvolatilität im gewünschten Verhältnis einzugrenzen, kann ja auch jeder selbst bauen. Die Kunst besteht eher darin, dann später wieder in guten Phasen auch relativ zeitnah entsprechend zurückzuschichten in Aktien rein um die Rendite mitzunehmen. Da wird sich erst langfristig, dass heißt über mehrere Marktzyklen hinweg betrachtet, wirklich sagen lassen welchen Mehrwert SC beitragen kann. Ihr Anspruch besteht ja auch nicht darin, dir die „höchste“ Rendite überhaupt zu bringen (es wäre auch ziemlich unseriös, sowas behaupten zu können), sondern einfach nur die best-möglichste die eben unter Berücksichtigung deiner gewünschten Verlustgrenze zu erreichen ist. Das kann also heißen, dass dein SC-Portfolio in Börsen-Booms der reinen Aktienanlage durchaus hinterherhinkt, bzw ist zwangsläufig so weil deren raison d’être vor allem in der Downside-Protection (und erst danach in der Upside-Participation) liegt. Das sollte man halt vorher wissen bzw verstanden haben, um nicht fälschlicherweise auch mal „enttäuscht“ zu werden, denn es geht nicht darum, dass wenn die Börse um +20% steigt, Scalable Capital dir noch dazu +40% Mehrrendite darüber oder so verschafft – sondern eher dass, wenn die Börse mal um -40% fällt, du mit Scalable stattdessen dann davon nur -20% Verlust (oder noch weniger, je nach deinem Level) mitmachen musst.
Liebe Grüße, und wünschen wir uns beide dass das auch langfristig alles so funktioniert -Christoph
Meine Begeisterung für Number26 ist immer noch erhalten, auch wenn sich einiges geändert hat seit meinem ersten Artikel:
Benutzer können sich einen Dispo einrichten
Mittlerweile gibt es auch EC-Karten
Es gibt die Möglichkeit, bei Partnern wie REWE Geld einzuzahlen und auszahlen zu lassen
Unschön ist, dass man mit den Karten nicht wirklich überall zahlen kann. In London verweigerte ein Geldautomat die Zusammenarbeit mit der Kreditkarte, in Amerika zeigten mehrere Kartenlesegeräte eine Fehlermeldung. Man sollte also gerade im Ausland immer eine weitere Kreditkarte eines anderen Unternehmens dabei haben. In Deutschland wollten die Automaten der Nord-Ostseebahn die EC-Karte nicht akzeptieren, was laut Support daran liegt, dass den Number26-EC-Karten der Girocard-/EC-Chip fehlt. Das tut meiner Begeisterung dennoch kaum einen Abbruch, denn gerade in Amerika war es wunderbar in Echtzeit sehen zu können, wie viel da gerade vom Konto abging. Meine Miles-and-More-Kreditkarte hat selbst nach drei Tagen immer noch nicht alle Buchungen auf dem Online-Konto.
Ein weiteres Fintech, das ich gerade ausprobiere, ist Scalable Capital. Ich hege ein (un?)gesundes Mißtrauen gegenüber den von Banken und Finanzberatern empfohlenen Anlageprodukten, versteckte Kosten sind anscheinend ein Kavaliersdelikt, und in manche meiner Verträge möchte ich schon gar nicht mehr reinschauen, weil ich in jungen Jahren einfach keine Ahnung hatte. Kostentransparenz wäre also schon mal eine gewaltiger Vorteil, wenn es um ein neues Angebot auf dem Finanzmarkt geht. Die Gebühren bei Scalable Capital betragen 0.75% des investierten Vermögens plus durchschnittlich 0,25% Kosten für die ETFs, die bereits in den ETF-Kursen der Anbieter berücksichtigt sind. Moment mal, Gebühren bei ETFs? Ja, auch ETFs kosten Geld, allerdings in der Regel weniger als ein aktiv gemanagter Fonds. Diese Gebühren hätte man aber eh bezahlt, nur dass man sich dessen vielleicht gar nicht bewusst gewesen wäre. Für 0,75% ist somit alles außerhalb der ETFs bezahlt, das Depot (was es oft genug eh schon kostenlos gibt, nur nicht bei dem Kooperationspartner von Scalable Capital, der Baader Bank), die Transaktionen, das Gehirn, das die Entscheidungen trifft, sowie die Gehälter der Mitarbeiter. Da Scalable Capital eh erst ab 10.000€ Vermögen neue Kunden aufnimmt, sind das also mindestens 75€ pro Jahr.
Beleuchten wir das “Gehirn”, das die Anlageentscheidungen trifft, einmal genauer, denn das ist der eigentlich spannende Teil dieses Fintechs. Man kann sich normalerweise von einem Finanzberater etwas empfehlen lassen, und bis auf die wenigen unabhängigen Berater, die sich in Deutschland eh kaum durchgesetzt haben, ist es nicht unwahrscheinlich, dass eine Provision für das empfohlene Produkt fließt. Abgesehen von den dadurch entstehenden Kosten, die der Kunde trägt, stellt sich die Frage, ob das empfohlene Produkt tatsächlich das beste Produkt ist oder die zu erwartende Provision bei der Empfehlung nicht vielleicht auch eine Rolle gespielt hat. Und selbst wenn der Finanzberater sich davon überhaupt nicht beeinflussen ließe, wie kann sichergestellt sein, dass tatsächlich das beste Produkt empfohlen wird? Woher weiß der Finanzberater das? Und wie lange bleibt es das beste Produkt? Wie oft empfiehlt einem der Berater, doch mal umzuschichten, weil sich der Markt geändert hat? Hat man nicht gerade eine wirklich hohe Summe auf dem Konto, so dass man in den Genuss einer richtigen Vermögensberatung kommt, dann sind die Optionen für den Normalverbraucher bestenfalls suboptimal.
Warum also nicht die Anlageentscheidungen einem Algorithmus, einem RoboAdvisor, überlassen, der sich nicht davon beeinflussen lässt, wie viel Provision er erhält? (Auch das wäre natürlich rein technisch möglich… wie eine Private Auction im Realtime Bidding) Und außerdem sehr viel mehr Informationen verarbeiten kann, als ein Mensch imstande ist? Der außerdem skalierbar ist und nicht nach der Höhe des zu verwaltenden Vermögens priorisiert? Aktiv gemanagte Fonds zum Beispiel schlagen sich nicht unbedingt besser als passive Fonds, und wie es um das Denken allgemein steht, nun ja. Algorithmen könnten die besseren Anlage-Manager sein, und das ist die Idee von Scalable Capital (neben der Art der Strategie, siehe dazu weiter unten). Das Unternehmen wird stehen und fallen mit der Performance seiner Algorithmen. Das Grundprinzip hier ist, dass die Algorithmen nicht auf Renditen optimiert wurden, sondern auf die Vermeidung von Verlust, ausgehend davon, dass die meisten Modelle das Verlustrisiko unterschätzen sowie das Renditepotential überschätzen (“Asymmetrie der positiven und negativen Kursentwicklungen”). Das Whitepaper auf der Webseite erklärt das Prinzip sehr gut. Sich selber keine Gedanken mehr machen zu müssen und von einer Vermögensverwaltung profitieren zu können, die ansonsten nur wirklich Vermögenden vorbehalten ist, wäre ein zweiter gewaltiger Vorteil. Plus, da Scalable Capital selbst Vermögen verwalten darf, werden die Transaktionen auch gleich für einen durchgeführt. Wie das alles genau funktioniert, darüber haben andereschonviel geschrieben.
Aber zu den ersten Erfahrungen. So schnell wie Number26 klappte die Konto-Eröffnung nicht. Zwar kann man auch hier via Video-Chat die Anmeldung vornehmen, aber bis das Konto tatsächlich eröffnet und die initiale Anlagesumme vom Referenzkonto abgebucht und dem Baader-Tagesgeldkonto gutgeschrieben ist, vergeht eine gute Woche. Baader hat mir dann auch noch ein Passwort für die Webseite geschickt, das ich nicht mal lesen konnte, weil es so dünn gedruckt war, so dass mein Zugang nach drei Fehlversuchen gesperrt war. Die Telefon-Hotline war nett, wollte das Problem aber nicht sofort beheben, und auch der Rückruf blieb aus. Alles in allem klappte aber auch das irgendwann. Und dann dauert es auch noch ein paar Tage, bis Geld von diesem Konto abgebucht und die ersten Papiere eingekauft werden. Zumindest bei mir wurde auch nicht sofort alles investiert, sondern auf zwei aufeinander folgende Tage, wobei immer noch etwas Geld auf dem Tagesgeldkonto über blieb. Und zunächst ging der Wert meines Portfolios minimal runter, aber wie es nunmal ist bei solchen Geldanlagen: erst mal schlafen legen. Auch der DAX ging in diesem Zeitraum runter.
Die App wie auch die Webseite sind ästhetisch und funktional gestaltet, kein Schnickschnack, schnell ladend. Die App hat lediglich Informationswert, Auf der Webseite und mittlerweile auch in der App kann man Ein- und Auszahlungen veranlassen sowie die monatliche Sparrate verändern. Das Portfolio zeigt genau, in welche Produkte investiert wurde, auch hier herrscht absolute Transparenz. Aus irgendeinem Grund kann ich keine Screenshots erstellen aus der App, anscheinend ist das durch die App unterbunden.
Das Portfolio wird verglichen mit einem Durchschnittsportfolio, wobei nicht wirklich klar ist, wie sich dieses Durchschnittsportfolio gestaltet. In der Hilfe steht lediglich, dass es um repräsentatives Portfolio der letzten 15 Jahre handelt, aber woher wurde dieses Portfolio genommen? Und welche Relevanz hat diese Information? Ich kann mein Portfolio eh nicht ändern.
Insgesamt macht Scalable Capital einen guten Eindruck auf mich. Es wird einige Zeit dauern, bis die Qualität der Algorithmen bewertet werden kann, ab und zu werde ich hier ein Update geben.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Frieder says
Februar 2017 at 11:23 … ich habe von Juli 2016 bis heute bei 20.000 Euro Anlagesumme exakt 275 Euro Gewinn gemacht in der mittleren Risikostrategie. Einen Indexvergleich braucht man gar nicht heranzuziehen: Eine erbärmliche Performance der Alghorithmen!!
Komisch, dass Scalable überall über den grünen Klee gelobt wird. Ich brauche keinen Dienstleister mit guter Presseabteilung.
Fazit: Ich werde kurzfristig mein Geld dort wieder wegnehmen!!
Keine Empfehlung!
Tom says
Februar 2017 at 10:41 Frieder, lies den Beitrag noch mal: investieren und schlafen legen Bei mir sind es gerade 3,75%…