Manchmal zeigt R Ergebnisse in wissenschaftlicher Notation an, was nicht schlimm wäre, wenn die Exponentenbasis sich nicht unterschiede:

Verhindern lässt sich das ganz einfach, indem man format(x, scientific=FALSE) hinzufügt:

Tom Alby
Manchmal zeigt R Ergebnisse in wissenschaftlicher Notation an, was nicht schlimm wäre, wenn die Exponentenbasis sich nicht unterschiede:
Verhindern lässt sich das ganz einfach, indem man format(x, scientific=FALSE) hinzufügt:
Manchmal erinnert man sich an irgendwelche Sendungen, die vor Jahrzehnten im Fernsehen liefen, und in einer von diesen Sendungen war Chris Howland zu sehen, der die Funktionsweise eines Microwriters erläuterte. Wenn man nach googled, dann findet sich nichts, was ich nun mit diesem Beitrag ändere. Denn Chris Howland war sehr an Computern interessiert, und ein kleines Video habe ich dann doch noch gefunden, wenn auch nicht das uralte Video mit Chris Howland, aber ab Minute 7:19 erzählt der Moderator vom Microwriter und auch von Chris Howland:
Ende der 70er Jahre erfunden konnten sich diese Geräte nie durchsetzen, was man vielleicht besser versteht, wenn man sieht, wie sie zu benutzen waren:
Die AMIs von Louis Aslett sind nützlich, um kurz mal einen RStudio-Server auf einer AWS EC2-Instanz zu starten. Allerdings enthalten diese AMIs nicht immer die aktuelle Version von R oder RStudio. Diese beiden Befehle helfen, sowohl R als auch RStudio upzudaten:
sudo apt-get install gdebi-core<br /> wget https://download2.rstudio.org/rstudio-server-1.1.442-amd64.deb<br /> sudo gdebi rstudio-server-1.1.442-amd64.deb
echo "deb http://cran.stat.ucla.edu/bin/linux/ubuntu `lsb_release -sc`/" | sudo tee --append /etc/apt/sources.list.d/cran.list<br /> sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9<br /> sudo apt update<br /> apt list --upgradable
Mein mittlerweile vierter Artikel zum Thema Scalable Capital und mein zweiter zu Quirion. Unter meinem ersten Artikel zu Scalable Capital sammeln sich eine Vielzahl von Kommentaren, selbst von einem der Scalable Capital-Gründer, und ich bin ehrlich gesagt immer wieder erstaunt, wie sich manche Anleger nach nur wenigen Monaten Erfahrung mit Scalable Capital oder anderen Robo Advisorn ein Urteil erlauben. Genau das aber wird gesucht: Erfahrungen Scalable Capital ist das häufigste Suchwort, mit dem Nutzer von Google auf diese Seite kommen. Zeit für ein Update.
Nachdem ich mit der Performance des im Mai 2016 eröffneten 10% VaR-Depots bei Scalable Capital nicht besonders zufrieden war, hatte ich im August 2017 ein zweites mit 20% VaR sowie ein Depot bei Quirion, dem Robo-Advisor der Quirin Privatbank, eröffnet. Bei beiden Anbietern sind 10.000€ Mindesteinsatz erforderlich, bei Quirion gab es damals noch ein Angebot, dass bis 10.000€ keine oder verringerte Gebühren erhoben werden.
Der Quirion-Roboter wurde mittlerweile sogar Sieger bei der Stiftung Warentest, die im Heft 8/18 RoboAdvisor testete. Scalable Capital bekam lediglich ein “befriedigend”. Angeblich weil das Portfolio ein Übergewicht bei bestimmten Assetklassen aufgezeigt hatte.
Nun habe ich selbst keine guten Erfahrungen mit der Stiftung Warentest gemacht, sei es, dass eines der Produkte, an denen ich selbst gearbeitet hatte, unfair getestet wurde (und die Tester inkompetenter waren, als ich es für möglich gehalten hätte), sei es, dass ich einem Testbericht folgte und ein Produkt kaufte, das grotesk schlecht war. Seitdem bin ich was die Stiftung Warentest betrifft sehr vorsichtig geworden.

Und auch hier haben sich meine Erfahrungen nicht mit denen der Stiftung Warentest gedeckt, auch wenn diese Institution für die meisten Deutschen der Weisheit letzter Schluss ist. Dennoch: Nach einem Jahr habe ich das Depot bei Quirion wieder aufgelöst, meine beiden Scalable Capital-Portfolios werde ich behalten.
Das Quirion-Depot hatte mit einem 50%/50%-Anteil von Anleihen zu Aktien meiner Meinung nach ausreichend Potential, brachte es aber in diesem einen Jahr nur auf 1,95% zeitgewichtete Rendite. Transaktionen habe ich keine beobachten können, das Depot wirkte statisch auf mich, aber vielleicht habe ich hier auch was übersehen. In der FAQ steht, dass das Depot mindestens einmal im Jahr aktualisiert wird. Merkwürdig übrigens diese Aussage in den FAQ:
Bei quirion vertraust du die Verwaltung deines angelegten Geldes den quirion-Vermögensverwaltern an, um Zeit für andere Dinge zu haben und dich nicht täglich mit neuen Marktentwicklungen und Anlageentscheidungen beschäftigen zu müssen.
Kein Wort von einem RoboAdvisor. Genaueres wie der Robo Advisor hier funktioniert, habe ich nicht gefunden. Dazu mehr weiter unten.
Ganz anders Scalable Capital, hier sind einige Transaktionen pro Monat zu sehen, und zwar in beiden Portfolios. Und die Ergebnisse? Mein gleichzeitig gestartetes 2. Portfolio bei Scalable Capital mit 20% VaR brachte es auf 3,70% zeitgewichtete Rendite nach einem Jahr, die Entwicklung ist in der Grafik zu sehen. Der Aktienanteil liegt hier bei 67%.
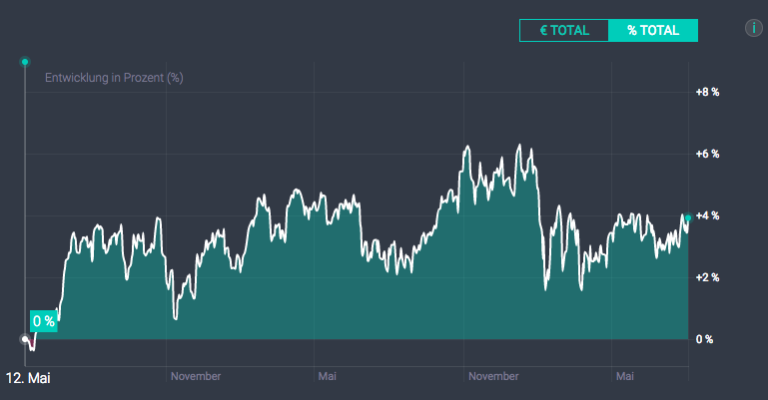
Mein über 2 Jahre altes 1. Portfolio bei Scalable Capital mit 10% VaR hat sich in den über 2 Jahren nicht unbedingt besser entwickelt, aber hier sind auch zwei verschiedene Investmentansätze implementiert. Der Aktienanteil liegt hier bei 34%. Die zeitgewichtete Rendite beträgt 3,92%, allerdings war ich hier nie im Minusbereich wie bei dem risikofreudigeren Portfolio; natürlich kann das auch am Zeitpunkt gelegen haben.
Insgesamt eine aus meiner Sicht überschaubare Performance, schließlich waren wir letztes Jahr schon um die 4% bei meinem älteren Portfolio, aber immer noch besser als die von Quirion. Natürlich ist ein Jahr nicht viel Zeit. Aber ich bin noch nicht fertig mit meinem Vergleich.
Wie bei den bisherigen Vergleichen ist auch immer noch mein Finanzberater im Rennen, der die gleiche Summe bekommen hat wie jedes meiner Portfolien bei Scalable Capital. Und das zweite Jahr hintereinander gewinnt er den Vergleich mit einer zeitgewichteten Rendite von 10,36%. In dem Tool wird auch eine zeitgewichtete Rendite p.a. angegeben, was ich für extrem wertvoll und eigentlich auch notwendig halte. Diese liegt bei 5,30%. Laut seinen Angaben ist das Geld auch mit einem Verlustrisiko von -10% investiert, ich kann daher also mit dem 10% VaR-Portfolio von Scalable Capital vergleichen. Allerdings geht hier auch seine Gebühr von 1% runter. Damit ich nicht weiter Fragen bekomme, ob ich nicht selber Investment-Tipps geben kann (kann ich nicht!), hier der Link zum XING-Profil meines Beraters; die Reklame hat er sich verdient
Hier sollte noch erwähnt werden, dass meines Wissens nach keine Umschichtungen vorgenommen wurden. Mit anderen Worten: Wie bei quirion regiert die ruhige Hand, anders als bei quirion sind die Ergebnisse aber besser.
Entweder ist mein Anlageberater ein besonders Guter oder die Robo Advisor sind noch nicht da, wo sie sein sollten, oder vielleicht sogar beides. Ich weiß es nicht. Auch scheinen sich die Robo Advisor-Ansätze von quirion und Scalable Capital grundsätzlich zu unterscheiden: Während quirion eher eine Art Assistent anbietet, der auf Basis von Regeln eine Anlagestrategie auswählt, die von Menschen vorher konfiguriert zu sein scheint, verwendet Scalable Capital meiner Meinung nach das innovativere Konzept und empfiehlt dem Investment-Team Portfolio-Umschichtungen; auch hier traded der Algorithmus noch nicht selbst, denn das darf er anscheinend noch nicht. Das ist meiner Meinung nach trotzdem der bessere Ansatz, und er hat sich in diesem einen Jahr, das zugegebenermaßen kurz ist, auch gegen Quirion durchgesetzt. Sehr gut wird der Unterschied zwischen den RoboAdvorsor-Ansätzen in den FAQ von SC erklärt.
Aber auch bei Scalable Capital ist nicht alles Gold, was glänzt. Was mich an Scalable Capital nervt: Ebenso wie bei Quirion wird keine zeitgewichtete Rendite p.a. angegeben. Warum nicht? Und warum darf man in der Android App keine Screenshots erstellen? Absoluter Quatsch! Und wie oben schon geschrieben, knapp 4% in mehr als zwei Jahren in dem älteren Portfolio sind keine herausragende Leistung meiner Meinung nach, insbesondere wenn man sich die Ergebnisse meines Finanzberaters anschaut.
2 Jahre sind immer noch keine lange Zeit im Finanzbereich. 1 Jahr erst recht nicht. Noch gewinnt der Mensch in meinem Vergleich.
Übrigens, wenn Sie sich über diesen Link bei Scalable Capital anmelden, dann bekommen Sie und ich einen kleinen Bonus 🙂
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Berner says
Marc says
Mark Alexander says
Vorab: Ich bin kein komplett ausgebildeter Statistiker oder Marktforscher. Zwar beschäftige ich mich leidenschaftlich mit Zahlen und versinke auch in meiner Freizeit in Statistikbüchern, aber je mehr man weiß, desto mehr weiß man, was man nicht weiß. Die Weisheit habe ich nicht mit Löffeln gefressen, und ich bin immer dankbar, wenn Schlauere Feedback geben. Ich glaube aber, dass jeder einigermaßen klar denkende Mensch ohne Statistik-Grundkurs verstehen kann, wann Daten nicht sinnvoll erhoben wurden oder falsche Ableitungen erstellt werden.

Auf diese These bin ich durch die Postings von Andre Alpar und Karl Kratz aufmerksam geworden. Sie stammt von Best4Planning, hier die ganze Studie “Qualität ist wichtiger als Likes”. Anders als die sehr geschätzen Kollegen Andre und Karl halte ich best4planning nicht für eine Satireseite, die b4p-Ableitung aus den Daten aber für zumindest mutig. Wenn man jetzt mal von den Haarwuchsmitteln in den Kleinanzeigen einer Zeitung absieht, die typische “10 Kilo in 2 Tagen abnehmen” oder “Millionäre wollen nicht, dass sie dieses Video sehen”-Reklame auf Facebook & Co spricht nicht für Social. Zumindest subjektiv würde ich die These also bestätigen. Die Eintrittshürde für Werbung im Netz ist wunderbar niedrig, in Print kostet sie nun mal vorab viel Geld. Ob die Automotive-Werbung für sauberen Diesel in Print heute noch als glaubwürdig wahrgenommen wird lassen wir mal dahingestellt, aber jeder Idiot kann in Online-Medien für wenig Geld ein Produkt anbieten. Von daher würde ich die Daten aus b4p, dass Werbung in Print glaubwürdiger ist, nicht anfechten.
Anders sieht es mit der Interpretation aus. Ist glaubwürdig gleichzusetzen mit kaufanregender? Ich halte das zunächst für eine Misinterpretation der Daten. Doch das Problem liegt meiner Meinung nach an der Grafik, denn als Quelle wird das Glaubwürdigkeits-Merkmal genannt: Es gibt auch das Merkmal “kaufanregend”:

So ergibt das also Sinn. Ich weiß zwar nicht, wie sie jetzt auf 28,1% gekommen sind, da ich unter Print sowohl Tageszeitungen als auch Magazine etc verstehe, aber vielleicht haben sie einfach (34+22)/2 gerechnet und sind somit auf die Zahl gekommen (intern werden sie wohl Nachkommastellen haben). Wie auch immer, die Erklärung in der Grafik ist unglücklich. Denn so denkt man (also ich zumindest), dass aus vertrauenswürdig das Merkmal kaufanregend abgeleitet wird.
Gehen wir mal einen Schritt weiter. Die Daten sind über alle Altersstufen verteilt, wie sieht es aus, wenn wir mal nach Altersklassen teilen?

Wow. Der demographische Faktor hat anscheinend gut zugeschlagen. Wenn ich jetzt nicht alles falsch gemacht habe, dann stimmt die Aussage, dass Ältere Werbung in Print vertrauenswürdiger und kaufanregender finden, Jüngere eher in Social Media. Wie bei Karl auf FB bereits kommentiert sind 65% der Befragten mindestens 40 Jahre alt, 49% mindestens 50, da unter 14 nicht befragt wird. Wir haben also einen Überhang der Älteren, die auch eher Print nutzen. Nun sind die unter 14-Jährigen natürlich nicht so stark in Social vertreten und auch nicht in Print, aber die Altersentwicklung in DE tut ihr Übriges dazu, dass die Zahl so stimmen mag. Das wird uns Hardcore-Onlinern nicht gefallen, lieber Andre, lieber Karl, aber außerhalb unserer Bubble sind tatsächlich Menschen, die keine telepathische Verbindung ins Netz haben.
Wenn man noch mal genauer hinschaut: 28.1% der Befragten finden laut Grafik Werbung in Print glaubwürdig. 28.1%. Das ist weniger als ein Drittel. Letztendlich könnte man auch sagen, Joa, Werbung bei Print ist für die Mehrheit der Befragten nicht glaubwürdig, aber bei Social noch viel weniger!
Fazit: Zahlen ok, Interpretation schwierig, wenn man es nicht differenziert sieht. Die Aufregung um die Aussage ist zu verstehen, denn sie stimmt zwar, aber ein Durchschnitt über die Gesamtpopulation ist immer noch ein Durchschnitt, und der ist in der Regel suboptimal, da er nichts über die Verteilung sagt.
Nun kann man mit b4p auch viel Mist machen. Vor allem dann, wenn man nicht versteht, wie die Daten gesammelt werden. Aber das haben wir auch bei Google Trends. Oder bei Similar Web. A fool with a tool is a fool. Punkt. Natürlich können wir es uns einfach machen und sagen, dass sowieso jede Marktforschung gelogen ist, aber das wäre nicht fair, denn es gibt genug Marktforscher, die sich verdammt viel Mühe geben.
Wie aber entstehen die Daten von b4p? Tatsächlich wurden für diese Studie 30.121 Menschen befragt, das sind sehr viel mehr Menschen als die in der Einschaltquote Beteiligten, zu denen ich auch mal gehört hatte, und es ist eine gute Basis. Hierzu gab es zwei Befragungswellen, alles hier nachzulesen. Ich sehe keinen Grund, das anzuzweifeln, nur weil Verlage die Auftraggeber sind. Denn man kann in den Daten auch so rumwühlen, dass manches nicht so wirklich schick aussieht für Print.
Die technische Messung fand mit 10.231 Teilnehmern im GfK Crossmedia Link Panel statt, denen auch eine anscheinend etwas gekürzte Form des Fragebogens zugeschickt wurde. Dann wurden diese Daten aus dem Panel und den Interviews sozusagen “übereinander” gelegt. Das ist ein übliches Verfahren. Daraus ergeben sich aber auch Konsequenzen. Beispiel: Ich baue mir eine Zielgruppe in b4p aus Menschen über 50, die selbständig sind in einem Baubetrieb usw. Aus n=30.121 wird dann ganz schnell n=12, die befragt wurden. Das ist schon schwierig, aber nun gut. Wenn ich mir dann aber die Mediennutzung ansehe, dann kann es sein, dass diese ja aus dem Drittel der Befragten des GfK-Panels stammt, also müsste ich korrekterweise 12:3 rechnen und wäre bei 4. Schwierig. Leider sagt die b4p-Seite nichts über solche Fälle, gibt keinerlei Hilfestellungen. Aber ich würde meine Werbe-Millionen nicht auf Basis solcher Daten investieren, wenn n so klein ist. Bedeutet das, dass b4p unseriös ist? Nein. Das Problem sitzt vor dem Bildschirm, denn die kleine Zahl links oben, die für die Fallzahl steht, ist nun mal sehr klein und wird deswegen auch gerne mal übersehen. Was wäre auch die Alternative? Gar nichts?
Wo ich tatsächlich Bauchweh habe, das sind die Fragen, zumindest die, die veröffentlicht sind, und da habe ich nur eine gefunden: “Denken Sie nun einmal an die Tage von Montag bis Samstag. An wie vielen von diesen 6 Werktagen sehen Sie im Allgemeinen morgens zwischen 6:00 Uhr und 9:00 Uhr Sendungen im Fernsehen? Denken Sie bitte auch daran, dass der Samstag oft anders abläuft als die anderen Werktage”. Aufgrund der sozialen Erwünschtheit: Wer mit ausreichend Gehirnzellen gibt denn freiwillig zu, dass er sich morgens schon mit Frühstücksfernsehen zuballert? Ich hoffe aber, dass solche Fragen durch weitere Kontrollfragen abgesichert sind.
Fazit: b4p ist für viele Anliegen eine gute Anlaufstelle. Wichtig ist, die Daten mit anderen Datenquellen und dem gesunden Menschenverstand abzusichern.
Gibt es Alternativen zu b4p? Wenige. Manche schwören auf Statista, aber bei der unreflektierten Nutzung von Befragungen stirbt ebenso ein Statistik-Einhorn wie bei b4p (das ist der Grund, warum Ihr keine Einhörner mehr seht). Statista ist natürlich eine extrem coole Seite mit tollen Daten, aber auch hier lohnt sich ein Blick in die Details, von wem die Studie eigentlich stammt. Zum Beispiel diese Studie vom Februar 2018, die uns sagt, dass 14% der mindestens 60-Jährigen auf Pinterest sind. Auch 14% der 50-59-Jährigen. n bei beiden Gruppen um die 600. Wow. Klingt super für Pinterest. Dummerweise muss man für Statista zahlen, wenn man die Quelle haben will, aber das hat netterweise jemand für mich getan. Die ganze Studie stammt vom Faktenkontor. Erhebung durch Toluna. Toluna? Was ist das? Eine Webseite, auf der man etwas dafür bekommt, wenn man an Umfragen teilnimmt. Hm. Wir haben also nicht zufällig aus den mindestens 60-Jährigen Menschen ausgewählt, die wir befragen, sondern einfach nur die genommen, die eh schon online sind und dann auch noch dieses Portal kennen usw. Dumm nur, dass nur 55% der über 65-Jährigen überhaupt im Internet sind laut destatis. Wir haben also eine eh schon online-affine Gruppe befragt, deren Wahrscheinlichkeit bei Pinterest zu sein dementsprechend höher ist. Ich wäre zumindest sehr vorsichtig, bei Rentnern als Zielgruppe nun Pinterest zu empfehlen und diese Zahl von 14% irgendwo zu verwenden.
Fazit: Schau Dir genau an, wie die Daten erhoben wurden.
Das Problem sind nicht die Daten, solange man versteht, woher sie kommen und wie sie erhoben wurden. Aber das will man gar nicht genau wissen manchmal, weil man eine Meinung hat und sich diese dadurch belegt, dass man nur die Daten auswählt, die die eigene Meinung bestätigen (und da bin ich nicht von ausgenommen). Man nennt das den Bestätigungsfehler. Darüber habe ich auch an anderer Stelle schon mal geschrieben. Oder man hat nicht die Zeit, Daten zu überprüfen. Oder manchmal auch nicht den Willen. Man sieht nur eine Zahl, hat eine eigene Meinung und schießt dann los. Ich wünsche mir manchmal mehr Differenzierung. So mal ganz nebenbei. Aber einfache Antworten sind immer besser zu kommunizieren.
Übrigens, ein schönes Buch, das ich gerade lese: Thomas Bausch – Stichprobenverfahren in der Marktforschung. Gibts gebraucht für weniger als 5€ bei Amazon.
Ich bin jetzt seit über 20 Jahren im IT-Bereich, davon einige Zeit als Entwickler, und wenn ich ein immer wiederkehrendes Muster sehe, dann, dass diejenigen, die versuchen unnötigen Druck auf Entwickler oder Techniker auszuüben, fast immer das Gegenteil erreichen. Das verstehen sie meistens nicht, weil sie sich im Recht sehen. Aber es ist eigentlich ganz einfach zu verstehen.
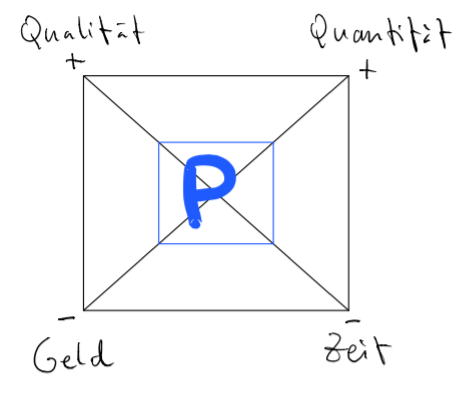
In diesem Artikel werde ich mich eines Instruments bedienen, dessen Urheber ich nicht kenne, und ich wäre superdankbar, wenn das jemand aufklären könnte. Irgendwann vor 20 Jahren brachte mir das mal ein IBMler oder so bei, und ich finde es immer noch beeindruckend.
Das Instrument funktioniert so: In der Grafik ist ein Projektgegenstand als Quadrat aufgezeichnet mit 4 Dimensionen, Qualität, Quantität, Geld und Zeit. Und in der Mitte ist die Produktivität des Teams, P. Wenn ich etwas ändern möchte, zum Beispiel den Liefergegenstand in weniger Zeit erhalten, dann muss ich die Fläche von P anders verteilen, denn die Fläche von P bleibt immer gleich. Ich kann also P auf der Achse der Zeit nach unten schieben (daher das Minus für weniger) und muss dann aussuchen, wie viel ich von den anderen Parametern Qualität, Quantität und Geld ich modifizieren möchte, damit die Fläche von P gleich bleiben kann. Ich kann zum Beispiel sagen, ok, dann gehe ich bei der Quantität runter (Richtung -), oder bei Quantität runter und bei Geld hoch, wie auch immer. Aber ich muss halt irgendwo was ändern, um die Änderung eines Parameters ändern zu können. Das ist ganz gut zu sehen in dem zweiten Bild.

Denn hier wurde das genau durchgeführt: Weniger Zeit, dafür aber auch weniger Quantität. Vollkommen logisch, oder?
Nun ist es aber so, dass manche denken, sie könnten P vergrößern, indem sie Druck ausüben. Das ist manchmal auch so. P kann temporär vergrößert werden. Und wenn wir ehrlich sind, wenn man das nicht akzeptiert, dann ist man in dieser Branche falsch. Gehört dazu. Weil man zum Beispiel weiß, dass von einem Launch-Datum sehr viel abhängt. Weil man selber viel investiert hat an Herzblut und sein Baby zum Laufen bekommen möchte. Er muss also gar nicht immer von außen kommen, der Druck. Denn wenn ein Entwickler die Notwendigkeit sieht, dann wird sie oder er immer alles dafür tun, dass es funktioniert. Ist so eine Art Ehrencodex. Ich kann schlecht damit leben, wenn ich nicht richtig abgeliefert habe, obwohl ich es versprochen habe. Und mir sind dann auch die Nachtschichten egal.
Allerdings kann P nicht ewig vergrößert werden. Irgendwann ist der Ofen aus. Man kann nicht mehr. Oder man sieht nicht mehr ein, warum immer so schlecht geplant wird. Oder, noch schlimmer, man sieht nicht, warum überhaupt P vergrößert werden muss, wenn Gründe angeführt werden, die am Ende des Tages nicht wirklich sinnvoll oder sogar übertrieben sind. Ich habe während der Dotcom-Zeit mal zufällig mitbekommen, dass eine Produktmanagerin sagte, dass der Druck auf mein Team immer hoch bleiben müsse. Das war nicht für meine Ohren bestimmt. Aber sie hatte auch nicht eingesehen, warum das nicht gesund ist. Irgendwann gehen die Leute. Und dann gehen meistens die Besseren. Die, die nicht gut sind und auch nicht bereit sind, die Extra-Meile zu gehen, die bleiben. Und die, die bereit sind zu investieren, weil sie ihren Job verdammt gerne machen, die gehen. Weil sie es nicht einsehen. Ständiger Druck bringt also nichts, ganz im Gegenteil. Kurzfristig vielleicht, aber man zahlt zigfach drauf, weil die Besten gehen. Und dann ist P noch kleiner. Und es dauert lange, bis ein neuer Kollege so eingearbeitet ist, dass P wieder auf dem alten Stand ist.
Schlimmer noch, man macht sich sich als Druckgeber auch noch unglaubwürdig. Vor allem wenn es dann heißt “Wir müssen doch zusammenhalten im Team.” Das ist so wie “Mensch, ja, Du trägst mich zwar auf Deinen Schultern, aber wir müssen zusammenhalten, also geh doch noch mal weiter.” Manchmal meinen diese Menschen es auch gar nicht so. Sie haben selber Deadlines und sie geben den Druck auch noch weiter. Ok. Aber wenn ein Team eh schon sehr viel zu tun hat und dann noch jemand kommt, dann darf man sich auch nicht wundern, dass P eben nicht größer geht, wenn es eh schon freiwillig (!) vom Team vergrößert wurde. Und dann wird das eben irgendwann nicht mehr getan.
Hinzu kommt, dass jede Eskalation nur noch mehr Zeit kostet. Jede E-Mail, wann etwas fertig wird, jedes Meeting, nichts führt dazu, dass der Tag mehr Stunden hätte. Im Gegenteil. Man klaut den Menschen, die die Arbeit tun müssen, einfach nur noch Zeit, die sie eigentlich bräuchten, um ihre Aufgaben zu erfüllen. Jedes “Ich brauche das aber unbedingt heute noch” bedeutet eben nicht, dass der Tag dadurch mehr Zeit hätte oder andere Deadlines aufgegeben werden können. Das müsste eigentlich auch dem Druckgeber klar sein. Aber so wird es eben gerne gespielt. Mit dem gegenteiligen Effekt.
Wie kann man das lösen? Ich zeichne zum Beispiel immer gerne dieses Quadrat auf. Und erkläre, dass P nur temporär vergrößert werden kann, wenn ich glaubhaft machen kann, warum. Manche Entwickler erhöhen P intrinsisch. Aber eben auch nicht ewig. Und ich werde mich immer vor mein Team stellen, wenn P eben nicht weiter sinnvoll erhöht werden kann und der Druckgeber auch noch unfair spielt. Die Erfahrung zeigt auch, je weiter der Druckgeber verständnistechnisch von dem entfernt ist, was die Entwickler tun, desto größer der unnötige Druck. Erfahrungen aus 20 Jahren. Trotz aller neuen Methoden, Prozesse… nichts hat die Gültigkeit von diesem Quadrat verändern können. Take it or leave it.
Das Zeitalter der sinnvollen Webanalyse hat gerade erst begonnen. Mehr und mehr Unternehmen verstehen, dass PageViews kein geeigneter KPI sind, um den Erfolg der Content-Investments zu überprüfen. Und dennoch naht das Ende dessen, was wir gerade liebgewinnen, bevor es zu schön werden kann.
Dies ist kein weiterer Click-Bait-Artikel darüber, wie Maschinen uns die Jobs wegnehmen werden. Natürlich wird Machine Learning die einfachen Analysten-Jobs eliminieren. Wir sehen heute schon, dass Google Analytics in der kostenlosen Variante selbständig Anomalien entdeckt. Fragen an die Daten können per gesprochener Sprache gestellt werden. Und da die Herausforderung meistens darin besteht, dass die richtigen Fragen an die Daten gestellt werden, wird auch das über die selbständige Analyse abgedeckt werden. In der 360er Variante bietet Analytics den neuen Analyze-Modus. Analysen werden mehr und mehr automatisiert erstellt werden können. Und das ist gut so. Denn auch wenn wir viel Erfahrung einbringen und wissen, welche Segmente zu untersuchen sich lohnt, eine Maschine kann einfach alle Kombinationen durchrechnen und auf Segmente kommen, die wir als Menschen niemals gefunden hätten. Das Stochern im Heuhaufen hat damit ein Ende. Und es ist effizienter, wenn Maschinen diese Suche unternehmen. Es bleibt schon jetzt nicht mehr dabei, dass nur Informationen aus Daten generiert werden – schon jetzt werden Handlungen abgeleitet. Das, was für die meisten Nutzer am schwierigsten ist, aus den Daten zu lernen, was man eigentlich tun müsste, wird auch von der Maschine interpretiert und artikuliert werden können.
So einfach ist es nicht, werden die Kutscher der Web Analyse sagen: Man kann nur dann etwas Sinnvolles aus den Daten ziehen, wenn diese sinnvoll erhoben wurden. Und in den meisten Fällen ist das nicht der Fall, dass sinnvolle Daten erhoben werden. Solange in vielen Fällen eine Standard-Installation eines Web Tracking-Tools Anwendung findet, gibt es noch viel zu tun. Doch wenn wir uns den heutigen Google Tag Manager einmal genauer ansehen, dann wird klar, dass viele Nutzerinteraktionen heute auch schon automatisch getracked werden können. Klicks auf Links. Scroll-Tiefe. Element-Visibilität. Was heute noch eingerichtet werden muss, könnte morgen schon automatisch erfolgen. Und es wäre der logische nächste Schritt. Gehen wir also davon aus, dass irgendwann in naher Zukunft das Einrichten eines Tag Management wegfallen wird. Je nachdem wie viel man zahlt, werden Events mehr oder weniger granular gemessen. Und zwar nur die, von der die Maschine gelernt hat, dass sie für ein definiertes Ziel wichtig sind.
Die Komplexität der Daten-Akquise wird wegfallen, und die Analyse wird wegfallen. Was wird dann noch überbleiben? Eine digitale Strategie auszuarbeiten, die auf Basis von Daten gestaltet ist? Das sehe ich nicht im Markenkern der Webanalysten. Die manuelle Webanalyse ist eine Brückenqualifikation, der Tankwart der Analytics-Lösungen. Denn in spätestens 5 Jahren, 2023, werden die großen Kunden schon mit der Webanalyse-KI arbeiten und nicht mehr mit einem teuren, eitlen Webanalysten.
Was sollen wir tun, wir “Web-Analyse-Helden”? Entweder qualifizieren wir uns weiter, vom Tankwart zum Modulhersteller. Oder wir verkaufen die Süßigkeiten drumherum. Die McJobs der Webanalyse. Und die können auch in Indien abgefackelt werden. Uns bleibt nur die Möglichkeit, mit Hilfe von Data Science Lösungen zu entwickeln, die für Google Analytics und Co zu nischig sind, um sie als erstes zu belegen. Wir werden noch wenige Jahre mit Implementierungen und Schulungen Geld verdienen können, aber spätestens 2023 ist Schluss damit.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Maik says
danke für deinen Beitrag, der eine für viele neue Sichtweise bietet. Aus unserem Gespräch im Rahmen unserer Podcastaufnahme weiß ich ja durchaus schon, dass du da einen sehr datengetriebenen Ansatz hast und auch die Zukunft der Webanalyse eher dem Machine Learning unterordnest.
Wie so viele Disziplinen, die aktuell im (Online-) Marketing existieren, so gehört auch die Webanalyse zu den – meine ich – immer noch aufsteigenden Trends. Denke mal an SEA, SEO, Affiliate Marketing, E-Mail-Marketing, … das alles boomt. Immer noch. Obwohl etwa SEO schon vor längerer Zeit ständig totgeredet wurde – und Google immer mehr Kompetenz zugeschrieben bekam, die Dinge schon „alleine“ zu können. Sicherlich, Google IST besser geworden. Doch die Menschen/Unternehmen mit ihren Websites sind es nicht. Und so ähnlich sehe ich das auch bei der Webanalyse.
So lange eine Disziplin noch nicht in der Breite (vor allem Mittelstand und kleine Unternehmen) angekommen ist, sind fünf Jahre ein, wie ich finde, zu kleiner Zeitraum, um Veränderungen in der Breite zu erzielen. In der Spitze (z. B. Konzerne) sehe ich das etwas anders, aber die Masse muss es mitbekommen – ansonsten ist die Veränderung eher eine der lokalen Maxima. Vielleicht bedeutet das aber auch, dass wir dann alle für Amazon arbeiten.
Ich gebe dir Recht, wenn du sagst, dass Maschinen Anomalien oder Cluster in den Daten wesentlich besser erkennen können als jeder Mensch es je könnte. Doch die Frage ist: Was machen am Ende wir, die Menschen, damit? Und da braucht es nun mal – vermutlich deutlich länger als 2023 – nach wie vor Menschen, die das in ein „Tun“ übersetzen, nachdem sie es zuvor mit Ihrer Strategie abgeglichen haben.
Haken an der Sache: Maschinelles Lernen braucht Daten – möglichst viele sogar. Und IMHO haben wir am 25. Mai in der Hinsicht einen ordentlichen Schritt nach hinten gemacht. Vielleicht haben wir – bzw. diejenigen, die die DSGVO beschlossen haben – Europa damit sogar ziemlich ins Abseits gestellt. Und die Regelungen der Verordnung und die Ängste der Menschen vor Missbrauch der Daten sorgen dafür, dass es vorläufig so bleibt. Das ist für viele Unternehmen schon eine ziemliche Bremse.
Zudem, auch wenn sich das natürlich in den nächsten Jahren durchaus ändern kann und sicher auch wird: KI oder ML ist derzeit noch kein „Massenphänomen“. Jeder spricht zwar darüber und erahnt vielleicht die Möglichkeiten, aber tatsächlich ist da draußen noch nicht überall „Hurra“ zu hören. Es fehlt an Systemen, die mehr Daten erheben, (aktuell) Menschen, die sich damit auskennen und letztlich auch oftmals an Wissen, was man damit alles anfangen kann.
Du sagtest völlig zurecht: Es braucht die richtigen Fragen. Ohne die ist KI noch deutlich länger als 2023 hilflos. Doch um die richtigen Fragen zu stellen, braucht es Menschen mit Verständnis für Zahlen, Business, Strategien und Umsetzungskenntnis. OK, vielleicht heißen die irgendwann nicht mehr Webanalyst (genauso wie es dann keine reinen SEOs mehr geben mag und die SEAler, deren Job allesamt die Google KI übernommen hat), doch die Webanalyse selbst wird Teil eines vielleicht neuen Berufsbildes sein, das AUCH das Verständnis der Webanalyse voraussetzt – und dafür braucht es immer noch Menschen, die den ganzen Tag nichts anderes machen. Schulungen werden dann vielleicht eher auf Strategien abzielen.
Ich sehe Webanalysten und Data Scientists da auf mehr oder weniger getrennten Schienen unterwegs. Der Webanalyst ist für mich häufig näher am Business und dem, was aus Zahlen folgt. Das reine Daten-Aufbereiten und Co. – da bin ich mir sicher – wird sicher irgendwann einfach wegfallen.
In dem Zuge vielleicht noch ein Hinweis auf einen super Artikel, den ich neulich verschlungen habe und uns ohnehin in 50 Jahren nur noch chillen lässt. Hier der Link: https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
Naja, und über allem, was du und ich sagen steht ja noch eine Sache: Vielleicht haben wir in 5-10 Jahren auch kein Internet mehr, sondern etwas noch Cooleres.
Danke, dass du das Thema hier mal in deinen Blog bringst. Und Doppel-Dank für die Analogie mit dem Tankwart. Love it. Volltanken, bitte. Maik
Tom Alby says
jeder Austausch mit Dir hilft mir, meine Gedanken zu sortieren und zu hinterfragen, und dafür bin ich Dir wie immer sehr dankbar.
Der Grund, warum ich das Ende des Web Analysten innerhalb weniger Jahre prophezeie, ist keine reine Effekthascherei. Ich glaube daran. Und das aus den folgenden Gründen:
Ja, vielleicht ist 2023 sportlich. Aber wenn Google irgendwas macht, dann etwas Skalierbares. Und auch wenn AdWords Express am Anfang nicht so toll funktioniert hat, mehr Daten werden dafür sorgen, dass es funktionieren wird.
Darf es zum Volltanken noch ein Snickers sein?
Tom
Maik says
die Legende von Sissa ibn Dahir ist ein tolles Beispiel. Andererseits sind genau bei exponentiellen Steigungen gerade zu Beginn die Steigungen noch nicht so hoch, dass sie solche Umwerfungen provozieren. Aber du hast Recht: Wenn skalierbar, dann Google.
Und tatsächlich, der Beitrag, den ich verlinkt habe, beschreibt unter anderem genau dieses Wachstum – in mitunter erschreckenden, weil unglaublich riesigen, Dimensionen. Und natürlich hat jeder Mühe, der versucht, das zu verstehen. Wie ist es wohl, wenn es noch in diesem Jahrhundert Maschinen geben wird, die 1 Million Mal intelligenter sind als wir Menschen. I cannot imagine …
Das Gute ist ja, dass wir beide uns hier nicht wirklich darüber unterhalten OB es (die Ablösung bestimmter Jobs) passieren wird, sondern eigentlich nur WANN. Insofern bin ich in vielen Punkten bei dir. Letztlich zählt auch nicht, ob Webanalysten- oder Data-Scientist-Jobs eher wegfallen als andere, sondern eher, was unsere künftige Aufgabe sein wird. Ob es in Zukunft noch Menschen braucht, die „analytisch“ denken und mit „Kreativität“ an Lösungsansätze herangehen.
Und ja, ich sehe auch, dass SEO an vielen Stellen „überdenkbar“ (würde ich das mal wohlwollend nennen) geworden ist. Zumindest in der Art und Weise, wie es von vielen SEOs betrieben wird. (Dein Begriff „Heilpraktiker“ trifft es ganz gut, finde ich).
Auch in dieser Spezialdisziplin gilt für mich immer mehr: Es braucht Leute, die sich mit einer sinnvollen Informationsarchitektur (technisch und inhaltlich) im Hinblick auf ihre Nutzer auseinandersetzen und Verbesserungen tätigen. Dafür braucht es (derzeit noch) Verständnis für Menschen, Werte – und solide Daten, um Verbesserungen zu messen. Vielleicht werden Websites in 5 Jahren aber auch komplett von Maschinen gebaut. Vielleicht gibt es in 10 Jahren aber auch keine Websites mehr, sondern nur noch VR. Who knows?
Eine Sache noch: Ich hoffe, dass die Entwicklungen in den nächsten Jahren/Jahrzehnten nur so schnell vorangehen, dass wir Menschen eine Chance haben, unsere Rolle in der „neuen Welt“ zu finden – und nicht komplett überrollt werden. Denn wenn Maschinen irgendwann alles können, was wir Menschen können, und das auch noch viel besser, dann werden wir hier auf der Welt zwar sicherlich eine Menge Probleme lösen können – jedoch auch viele neue haben, was unsere Aufgaben angeht. Und gerade die Komponente „exponentiell“ ist da irgendwie – so lustig das klingen mag – unberechenbar.
Snickers? Ja, gerne. Zum Mitnehmen, bitte. Maik
Christian Hansch says
was meinst du am Ende deines Artikels genau mit der Qualifizierung zum Modulhersteller? Ich glaube auch, dass wir Web-Analysten in 5-10 Jahren abgelöst werden, aber eigentlich muss ich ja noch knapp 20-25 Jahre arbeiten. Hypothese: In Zukunft ist es noch wichtiger, die richtigen Fragen zu stellen mit ggf. den richtigen Nebenbedingungen, damit die Maschine die richtige Antwort „ausspucken“ kann.
Ich finde die GA – App mit dem aufzeigen der Anomalien auch super. Ich frage mich aber, wie die Maschine die diversen Ziele favorisieren soll und nicht immer wird nur der monetäre Output maximiert, manchmal auch die Kommunikation, die schwer messbar ist.
Beste Grüße Christian
P.S.: Schade, dass ich deinen Vortrag auf der Campixx nicht gesehen habe, dann könnte ich besser verstehen oder mit diskutieren, wieso SEO tot sein soll.
Christian Hansch says
Wer hier öfter mitliest, der weiß, dass Sistrix eines meiner absoluten Lieblings-Tools ist (ich verlinke mal ganz dreist als bestes SEO Tool), allein schon wegen der schlanken API, dem absolut liebenswürdigen Johannes mit seinen wirklich schlauen Blog-Posts sowie der Unaufgeregtheit, mit der die Toolbox immer wieder überzeugt. Natürlich sind auch alle anderen Tools klasse, aber Sistrix ist sowas wie meine erste große Tool-Liebe, die man nicht aus seinem SEO-Gedächtnis verbannen kann oder will. Und auch wenn die folgenden Daten eventuell am Lack kratzen könnten, eine richtige Delle haben sie in meiner Sistrix-Präferenz nicht verursacht.
Aber genug der Lobhudelei. Worum gehts? Wie schon in dem Post über keywordtools.io oder den am Rande erwähnten Ungenauigkeiten in den Google AdWords Keyword Planner-Daten beschrieben, ist es eine Herausforderung, verlässliche Daten über das Suchvolumen von Keywords zu bekommen. Und wer immer noch glaubt, dass Google Trends absolute Zahlen liefert, nun ja… Sistrix bietet hierfür einen Traffic-Index von 0-100, der auf Basis von verschiedenen Datenquellen berechnet wird, womit eine höhere Genauigkeit entstehen soll. Doch wie genau sind die Zahlen hier? Nebenbei will ich außerdem zeigen, warum Boxplot ein wunderbarer Weg sind, Daten zu visualisieren.
Als Datenbasis dienen hier 4.491 Suchanfragen aus einem Sample, wo ich sowohl die Sistrix- als auch die Google AdWords Keyword Planner-Daten habe. Es ist übrigens nicht das erste Sample, was ich gezogen habe, und die Daten sehen überall ungefähr gleich aus. Es liegt also nicht an meinem Sample. Schauen wir uns also zunächst einmal die reinen Daten an:

Wie wir sehen, könnte man eine Kurve in diesen Plot hineinzeichnen, die Relation scheint schon mal nicht linear zu sein. Aber vielleicht haben wir es hier nur wegen des Ausreißers ein verzerrtes Bild? Schauen wir uns den Plot ohne den Riesen-Ausreißer an:

Vielleicht haben wir hier immer noch zu viele Ausreißer, wir nehmen mal nur die unter einem Suchvolumen von 100.000 pro Monat:

Tatsächlich sehen wir hier eine Tendenz, dass es rechts weiter nach oben geht, zwar keine deutliche Linie (ich habe auf eine Regressionsanalyse verzichtet), aber wir sehen auch, dass wir bei einem Traffic-Wert von 5 Werte haben, die über die Indexwerte von 10,15,20,25 und 30 hinausgehen, sogar bei 50. Schauen wir uns das arithmetische Mittel der Suchvolumina an (mit Ausreißern), so sehen wir wieder die Kurve:

Der Median ignoriert die Ausreißer innerhalb der kleineren Werte:

Sehen wir uns die Daten also im Median an, so sehen wir zumindest bei den höheren Werten eine korrekte Tendenz mit Ausnahme des Wertes bei dem Sistrix-Traffic-Wert von 65 oder 70. Allerdings ist die Streuung um diese Werte sehr unterschiedlich, wenn man die Standardabweichungen für jeden Sistrix-Traffic-Wert plottet:

In der Streuung sehen wir kein Muster. Es ist nicht so, dass die Streuung mit einem höheren Index-Wert zunimmt (was zu erwarten wäre), tatsächlich ist sie bei dem Index-Wert von 5 schon höher als bei 10 etc. Die höchste Streuung sehen wir bei dem Wert von 60.
Weil Boxplots einfach eine wunderbare Angelegenheit sind, schieße ich den auch noch hinterher:

Hier sind die Daten einmal umgedreht (weil sie mit den Sistrix-Daten auf der X-Achse nicht wirklich gut erkennbar waren). Die Box zeigt jeweils an, wo 50% der Daten liegen, also bei einem Suchvolumen von 390 zum Beispiel liegen 50% der Daten zwischen dem Sistrix-Wert von 5 und 25 zu liegen, der Median wird durch den Strich in der Box gekennzeichnet und liegt bei 15. Die Größen der Boxen nehmen am Anfang zu, danach sind sie wieder unterschiedlich groß, was auf eine geringere Streuung hinweist. Bei manchen Datenpunkten sehen wir kleine Kreise, die R als Ausreißer berechnet hat. Wir sehen also gerade bei den geringen Suchvolumina Ausreißer. Fast alles, was wir oben geplottet hatten, kriegen wir hier in einem Plot visualisiert. Boxplots sind einfach wunderbar.
Bedeutet das nun, dass die Traffic-Daten in Sistrix unbrauchbar sind? Nein, das bedeutet es nicht. Denn wie in der Einleitung beschrieben sind auch die Keyword Planner-Daten nicht immer korrekt. Nichts Genaues weiß man also nicht. Wer die Keyword Planner-Daten als Nonplus-Ultra sieht, der wird sich mit den Sistrix-Daten nicht zufrieden geben können. Hilfreich wäre, wenn es mehr Transparenz gäbe, wo die Daten genau herkommen. Offensichtlich wären angebundene GSC-Daten sehr hilfreich, da sie echte Impressions zeigen. Meine Handlungsempfehlung ist, sich mehrere Datenquellen anzusehen und die Overlaps sowie die Abweichungen getrennt anzusehen. Das ist unbefriedigend, da es kein Automatismus ist. Aber “a fool with a tool is still a fool”.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Hanns says
Tom Alby says
martin says
Ich verstehe tatsächlich auch nicht, wie das technisch funktionieren soll. Wie soll Sistrix an die Suchanfragen kommen, die pro Keyword über Google laufen? Ist ja nicht so, als würde Google Sistrix bei jedem Request kurz informieren.
Das einzige was ich mir vorstellen kann ist, dass sie sich die Daten für jedes Keyword aus dem AdsPlanner ziehen. Aber … das als „eigenes Suchvolumen“ darzustellen, ohne Hinweis woher die Daten kommen, fände ich schon grob fahrlässig.
Woher könnten sie noch Daten bekommen?
Tom says
die Antwort ist halt nicht 1 oder 0, das kommt auch in dem Artikel heraus. Du kannst Dich auch nicht auf die AdPlanner-Daten verlassen. Sistrix bekommt auch noch Daten von Kunden, die die Search Console-Daten dort verknüpft haben, da Du ja die Impressions Deiner Seite für ein Keyword sehen kannst. Aber all das natürlich nicht für jedes Keyword. Und daher kommen Ungenauigkeiten zustande.
BG
Tom
Nachdem der Google AdWords Keyword Planner nur noch für Konten mit ausreichend Budget granulare Daten ausspuckt, ist die Suche nach Alternativen groß. Rand Fishkin glaubt, dass Google Trends die Rettung sei, hat aber anscheinend nicht verstanden, dass Google Trends normalisierte, indexierte sowie Keyword-erweiterte Daten und keine absolute Zahlen liefert. In einem Punkt aber hat er Recht, auch der Keyword Planner liefert nicht wirklich genaue Daten, wie ich in diesem Artikel festgestellt hatte.
Natürlich ist das eine unbefriedigende Situation. Kein Wunder, dass Alternativen wie keywordtool.io beliebt sind. Doch wie genau sind deren Daten? Denn ich habe keinen Hinweis darauf gefunden, woher sie die Daten haben, und das macht mich zunächst einmal sehr misstrauisch. Woher sollten sie die Daten haben, wenn nicht über die API? Und hier ist der Zugriff limitiert. Auf Initiative meines geschätzten Kollegen Christian habe ich mich dann etwas genauer damit beschäftigt. Zum einen hat er nachgefragt, woher keywordtool.io die Daten hat (darauf gab es keine zufriedenstellende Antwort). Zum andern hat er einen Test-Account besorgt Ein erster Vor-Test brachte enttäuschende Ergebnisse, die Zahlen waren komplett anders als die von AdWords. Allerdings war sich der Kollege nicht mehr sicher, ob er die gleichen Einstellungen gewählt hatte wie ich in AdWords, so dass ich den Test dann noch mal alleine durchgeführt habe.
Beim ersten Keyword-Set aus dem Pädagogik-Bereich war die Überraschung nach dem Vor-Test groß: Bis auf wenige Ausnahmen hatten alle Keywords das exakt gleiche Suchvolumen. Die wenigen Ausnahmen bestanden darin, dass keywordtool.io keine Zahlen ausspuckte, der Keyword Planner jedoch schon. Hier handelte es sich aber um lediglich 2 von knapp 600 Keywords. Auch beim zweiten Keyword-Set zum Thema Akne ergab sich dasselbe Bild. Die Suchvolumina passten ganz genau bis auf wenige Ausnahmen. Interessanterweise handelte es sich bei beiden Keyword Sets eher um Themengebiete, die nicht unbedingt durch hohes Suchvolumen auffielen, zum Teil reden wir hier von 20 Suchanfragen pro Monat. Es ist also sehr wahrscheinlich, dass die Google AdWords API hier direkt angezapft wird, anders sind diese genauen Zahlen nicht zu erklären. Das würde auch erklären, warum man nur 10 Sets à maximal 700 Keywords abfragen kann (mehr als 700 Keywords gehen beim Keyword Planner auch nicht, dafür aber mehr als 10 am Tag). Somit wäre keywordtool.io eine gute Alternative… wenn nicht…
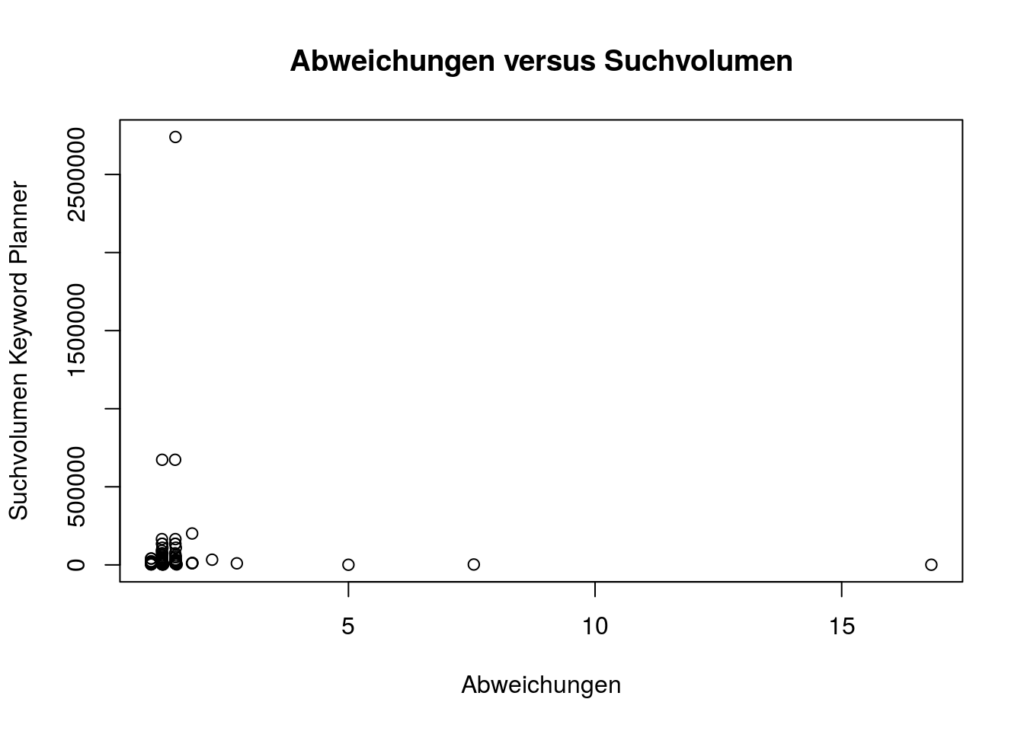
Das dritte Keyword Set zeigte dann ein anderes Bild, die Abweichungen sind dramatisch. Anders als bei den bisherigen Keywords reden wir hier von High Volume Keywords wie . Leider ist aber kein Muster zu erkennen, wie man schön auf dem Plot sehen kann, bis auf das Muster, dass keywordtool.io immer höher und nie niedriger liegt. Keywords mit hohem Suchvolumen können genau so gut daneben liegen wie Keywords mit geringem Suchvolumen. Es ist auch nicht so, dass es immer die gleiche Abweichung wäre, wir reden von Keywords, wo die Zahlen genau passen, und Keywords, die eine Abweichung vom 16-fachen des von Google berichteten Volumens haben. Es existiert auch keine Reihenfolge in irgendeiner Weise. Die Abweichungen sind komplett zufällig. Und sie sind viel zu groß, als dass man sie ignorieren könnte.
Natürlich wird das viele nicht davon abhalten, keywordtool.io dennoch zu nutzen, schließlich sagt man sich dann gerne “Joa, passt ja meistens” oder “Ist doch besser als nix”. Ob es wirklich besser ist, das stelle ich mal in Frage. Ich würde auf Basis solcher Abweichungen keine Entscheidungen treffen wollen. Da ist dann eher der Keyword Planner die bessere Option, auch wenn er nur gestaffelte Werte abliefert, sofern man nicht ausreichend Budget mitbringt.
Die Daten des dritten Sets stehen übrigens hier in einem R Notebook zur Verfügung.
Der letzte Teil dieser Serie über Suchmaschinenoptimierung/SEO und Data Science auf Basis meines Vortrags bei der SEO Campixx. Die Daten und den Code habe ich via Knit in ein HTML-Dokument überführt, das mein Notebook inklusive Daten nachvollziehbar macht. In dem Notebook sind auch ein paar mehr Untersuchungen drin, allerdings habe ich alles auf Englisch dokumentiert, da dies nicht nur für Deutsche interessant ist. Wer also alle Ergebnisse in einem Dokument lesen möchte (ohne die TF/IDF, WDF/IDF oder Stemming-Beispiele), schaut sich bitte das Data Science & SEO Notebook an. Speed und andere Faktoren sind in den vorherigen Teilen zu lesen.

Zunächst einmal ein Nachtrag: Uns fehlte ja das Alter für einige Domains, und diese Daten habe ich nun aus einer anderen Quelle bekommen. In unserem Sample waren die meisten Domains ja älter, und meine Sorge war, dass die fehlenden Domains eventuell sehr viel jünger waren und daher das Durchschnittsalter fälschlicherweise nach unten gezogen würde. Fast 20% der Domains fehlten.
Tatsächlich ist es so, dass die fehlenden Domains jünger sind. Lag der Median bei unserem löchrigen Datensatz bei 2001, liegt er bei den fehlenden Domains bei 2011. Führt man die Daten zusammen, liegt er aber dennoch wieder bei 2001, nur der Mean hat sich von 2002 auf 2003 geändert. Somit war die Anzahl der fehlenden Daten nicht so hoch, dass diese gegenläufige Tendenz einen großen Einfluss gehabt hätte. Natürlich könnte man nun entgegenhalten, dass diese andere Quelle einfach ganz andere Zahlen hat, aber bei einer Stichprobe der Domains, für die bereits ein Alter vorhanden war, konnte das nicht verifiziert werden. Und schaut man sich nun den Plot für die Beziehung zwischen Position auf der Suchergebnisseite und Alter einer Domain an, so haben wir also auch nichts Neues herausgefunden:

Boxplots sind eine wunderbare Angelegenheit, denn sie zeigen auf einen Blick unglaublich viel über die Daten. Die Box zeigt an, wo sich 50% der Daten befinden, der dicke Strich in der Mitte den Median, und die Breite der Box die Wurzel aus der Sample-Menge. Selbst nach mehreren Bier ist hier kein Muster zu erkennen, außer dass die Boxen alle ungefähr auf der gleichen Höhe sind. Google hatte ja bereits gesagt, dass das Alter einer Domain keine Rolle spielt.
Ein weiterer Mythos, und an diesem ist toll, dass wir ihn relativ einfach aufklären können, denn die Daten können wir uns selber crawlen. Übrigens eignet sich R nicht soooo super zum Crawlen; zwar gibt es das Paket rvest, aber wenn man wirklich nur den Content haben will, dann kommt nix an Pythons Beautiful Soup dran. Netterweise kann man in den RStudio-Notebooks auch Python ausführen Als Text wird hier also nur der tatsächliche Text genommen, nicht der Quellcode. Navigationselemente und Footer zählen allerdings mit rein, wobei wir bei Google davon ausgehen können, dass der tatsächliche Content extrahiert werden kann. Der folgende Plot zeigt das Verhältnis zwischen Content-Länge und Position:

Wie wir sehen, sehen wir nix, bis auf einen interessanten Ausreißer mit mehr als 140.000 Wörtern in einem Dokument (http://katalog.premio-tuning.de/), der auf Platz 3 für das Keyword “tuning kataloge” rankte. Ansonsten ist keine Korrelation zu beobachten. Eine allgemeingültige Aussage wie “mehr Text = bessere Position” lässt sich somit nicht ableiten. Der Median für die Anzahl Wörter liegt bei 273, der Mean bei 690. Nur zur Erinnerung, wir befinden uns hier in den Top 10. Wie die Kollegen von Backlinko auf 1.890 Wörter für das durchschnittliche 1. Platz-Dokument gekommen sind, würde mich tatsächlich sehr interessieren. Zwar haben sie weit mehr Suchergebnisse angesehen (was bedeutet “1 million search results”? Genau das, also ungefähr 100.000 Suchergebnisseiten, also die Ergebnisse für ungefähr 100.000 Suchanfragen?), aber welchen Durchschnitt sie verwendet haben, verraten sie nicht. Wie man schon in meinen Zahlen sehen kann, gibt es einen großen Unterschied zwischen dem Median und dem Mean, also dem arithmetischen Mittel, das die meisten Menschen als Durchschnitt bezeichnen. Nicht umsonst sage ich immer, dass der Durchschnitt der Feind der Statistik ist Vielleicht sind Texte in den USA aber auch länger? Aber da uns die Zahlen nicht zur Verfügung gestellt werden… und auch nicht die Methoden… nun ja, irgendwann habe ich mal gelernt, dass man zu seinen Ergebnissen sowohl die Daten als auch die Software zur Auswertung beifügen muss, damit wirklich alles nachvollziehbar ist.

In diesem abschließenden Teil habe ich noch weitere Signale hinzugefügt, u.a. TF/IDF und WDF/IDF. Und wie man in der Korrelationsmatrix schön sehen kann, haben wir nirgendwo eine Korrelation. Im letzten Teil hatten wir aber auch schon gesehen, dass das nicht über alle Keywords gilt. In dem Histogramm der Korrelationskoeffizienten sahen wir sowohl positive als auch negative Korrelationen, aber keinen p-Wert. Schaut man sich nur die Korrelationskoeffizienten an, bei denen p < 0.05 ist, sieht das Bild wieder anders aus:

Wir haben also Keywords, wo die Backlinks eine Rolle spielen, und wir haben auch Keywords, wo die anderen Signale eine Rolle spielen. Wenn wir aus dem Keyword-Set eine Schlussfolgerung ziehen können, dann die, dass es keine allgemeingültige Regel gibt. Wie schon beim letzten Teil geäußert, benötigen wir die obige Korrelationsmatrix für jedes Keyword. Und genau das ist spannend, denn wir können für jedes Keyword einzeln oder vielleicht auch ein Thema schauen, wie sich die Ranking-Signale dort verhalten.

Und so sieht man für das Keyword “player update” (als Hash 002849692a74103fa4f867b43ac3b088 in den Daten im Notebook), dass einige Signale doch stärker hervortreten, siehe die Abbildung auf der linken Seite. Kann man nun sicher sein, dass man jetzt für dieses Keyword genau weiß, wie das Ranking funktioniert? Nein, kann man nicht (zumal wir hier noch nicht die p-Werte ausgerechnet haben). Aber wenn wir uns mehrere Keywords aus der gleichen “Region” (also ähnliche Werte in diesem Signal) anschauen, dann könnte tatsächlich etwas darin zu finden sein.
Leider auch nix. Und das war wohl der größte Streitpunkt auf der SEO Campixx. Ich nutze in diesem Beispiel erst einmal nur den Exact Match, also finde ich genau das eingegebene Keyword so im Text. Natürlich könnten wir jetzt weiter gehen und stemmen und auseinander gepflückte Keywords matchen lassen, aber um die Komplexität zu verringern, schauen wir und halt nur den Exact Match an. Schauen wir einmal hier:

Hier ist kein eindeutiges Muster zu sehen, und es gibt auch keine Korrelationen. Nur sehr wenige Beobachtungen schaffen überhaupt einen p-Wert unterhalb 0,05 sowie einen Korrelationskoeffizienten von mehr als 0.1. In diesem Keywordset kann nicht nachvollzogen werden, dass WDF/IDF etwas bringt, zumindest nicht für Exact Match. Ebenso wenig TF/IDF. Keyword Density hab ich nicht mal nachgeschaut.
Der letzte Teil meiner Präsentation von der SEO Campixx war eine Kurzzusammenfassung meiner Artikelserie über ein SEO-Reporting mit R und AWS (insbesondere der Teil über das handlungsrelevante Analysen und ein Reporting).
Noch einmal die wichtigsten Punkte:
Die emotionalen Reaktionen mancher Kollegen sind nicht unverständlich, denn schließlich werden manche Tools teuer bezahlt (es saßen ja auch Tool-Betreiber in meinem Vortrag, von denen einer sich zu der Aussage hinreißen ließ, dass man merke, dass ich lange nicht mehr als SEO gearbeitet hätte). Es ist ungefähr so als ob ich zu einem Christen gehe und sage, dass sein Jesus leider nie existiert hat. Das habe ich nicht gesagt. Ich habe lediglich gesagt, dass ich die Wirkung gängiger Praktiken anhand meines Datensatzes nicht nachvollziehen kann. Aber viele SEOs, die ich sehr schätze, haben mir gesagt, dass z.B. WDF/IDF für sie funktioniere. In der Medizin heißt es “Wer heilt hat Recht”, und am Ende des Tages kommt es auf das Ergebnis an, auch wenn nachgewiesen ist, dass Homöopathie nicht hilft.nUnd vielleicht kommen die guten Resultate dieser SEOs auch nur dadurch zustande, dass sie auch viele andere Dinge richtig machen, es dann aber auf WDF/IDF schieben.
Was mich als Daten-Mensch aber interessiert ist die Reproduzierbarkeit. In welchen Fällen funktioniert WDF/IDF und wann nicht? Hinzufügen möchte ich, dass ich keinerlei kommerzielles Interesse daran habe, irgendeinen Weg als gut oder schlecht zu bezeichnen, denn ich verkaufe kein Tool (mal sehen, vielleicht baue ich ja mal irgendwann eines) und ich verdiene mein Geld nicht mit SEO. Mit anderen Worten: Mir ist es so ziemlich sch***egal, was hier rauskommt. Die Wahrscheinlichkeit, dass ich einem Bestätigungsfehler unterliege, weil ich nur noch Fakten suche, die meine Meinung unterstützen, ist äußerst gering. Mich interessiert nur die Wahrheit in einer post-faktischen Welt. Und anders als zum Beispiel die Untersuchung von Backlinko stelle ich meine Daten und meinen Code zur Verfügung, damit das jeder nachvollziehen kann. Das ist Komplexität, und viele versuchen Komplexität zu vermeiden und suchen einfache Antworten. Aber auf schwierige Fragen gibt es nun mal keine einfachen Antworten, auch wenn das für Menschen viel attraktiver ist. Meine Empfehlung: Keiner Statistik glauben, die nicht die Daten und Methoden nachvollziehbar macht. Ich wünsche mir von allen Kritikern, dass sie auch die Daten und ihre Software offenlegen mögen. Hier geht es nicht um Eitelkeit.
Die Donohue–Levitt-Hypothese ist für mich ein gutes Beispiel: So wurde die Zero Tolerance-Vorgehensweise der New Yorker Polizei in den 90er Jahren dafür gelobt, dass die Kriminalität daraufhin signifikant zurück ging. Das ist bis heute eine weit verbreitete Meinung. Donohue und Levitt hatten die Zahlen untersucht, kamen aber auf eine andere Schlussfolgerung, nämlich dass dies eine Scheinkorrelation sei. In Wirklichkeit sei die Verbreitung der Babypille dafür verantwortlich gewesen, dass die jungen Straftäter erst gar nicht geboren werden, was sich dann in den 90er Jahren bemerkbar machte. Natürlich wurde auch das wieder angegriffen, dann wieder bestätigt, und dann fand auch noch jemand heraus, dass das Verschwinden des Blei-Anteils aus Benzin für die Verringerung der Jugendkriminalität verantwortlich sei (Lead-Crime-Hypothese). Allerdings sind das komplexere Modelle. Mehr Polizeiknüppel gleich weniger Kriminalität ist einfacher zu verstehen und wird deswegen auch immer noch verteidigt (und vielleicht ist ja auch ein bisschen was dran?). Aber auch hier, wer ein Modell sympathischer findet, der wird sich vor allem die Daten anschauen, die diese Meinung bestätigen.
Ich hätte noch viel mehr untersuchen können. Aber wie gesagt, ich mache das nebenbei. Lust auf mehr Daten zu dem Thema habe ich schon. Aber jetzt liegen erst mal wieder andere Datenberge hier Und dann wäre der nächste Schritt ein größerer Datensatz sowie Machine Learning, um Muster genauer zu identifizieren.