[Dies ist die Neuauflage eines älteren Artikels]
Wie bei Google Trends bin ich immer wieder überrascht, wie schnell Rückschlüsse aus Daten gezogen werden, ohne dass einmal überlegt wird, woher die Daten eigentlich kommen und wie plausibel sie sind. Vor allem bei Similar Web ist das erstaunlich, denn Google hat ja die Suchdaten und kann Trends daraus ablesen, aber woher kann eigentlich Similar Web Daten darüber haben, wie viele Besucher eine Webseite oder eine App hat? Wie zuverlässig sind diese Daten? Ist die Zuverlässigkeit ausreichend, um daraus wichtige Business-Entscheidungen zu treffen?
Der Vorfahr von SimilarWeb
2006 hatte mein früherer Kollege Matt Cutts einmal untersucht, wie zuverlässig die Daten von Alexa sind (Alexa war früher mal ein Amazon-Service, der nichts mit Spracherkennung zu tun hatte). Dieser Dienst sammelte Daten mit einer Browser-Toolbar (sowas gibts heute auch nicht mehr), d.h. es wurde jede Seite protokolliert, die ein Nutzer sich ansah. Da die Alexa-Daten vor allem für Webmaster interessant war, hatten vor allem diese die Toolbar installiert, und so wurden also vor allem Seiten protokolliert, die für Webmaster interessant waren. Sie waren verzerrt.
Wenn man den Traffic von Nutzern mitschneidet, dann muss man auch irgendwie zusehen, dass die Nutzerschaft irgendwie der Netzpopulation entspricht, über die man etwas herausfinden will. Das heißt nicht, dass die Similar Web-Daten komplett wertlos wären. Wenn man zwei Modeseiten miteinander vergleicht, dann sind diese eventuell gleich “uninteressant” für die Webmaster-Population (ein Vorurteil, ich weiß), und dann könnte man zumindest diese miteinander vergleichen. Aber man könnte nicht eine Modeseite mit einer Webmaster-Tool-Seite vergleichen. Aber selbst das sind nur Vermutungen, genau weiß man es nicht. Für ein so teures Tool eigentlich unglaublich.
Woher aber bekommt nun Similar Web die Daten? Auf ihrer Webseite geben sie 4 Quellen an:
- Ein internationales Panel
- Crawling
- ISP-Daten
- Direktmessungen
Datensammlung über ein Panel

Das Panel wird nicht genauer erklärt, aber wenn man nur minimal recherchiert, so findet man schnell Browser-Extensions. Diese sind wohl die Nachfolger der früheren Browser-Toolbars. Welchen Vorteil bietet die Similar Web-Extension? Sie bietet genau das, was Similar Web auch bietet: Man kann mit einem Klick sehen, wie viele Benutzer die gegenwärtig angeschaute Seite hat, woher sie kommen, und so weiter. Dabei funkt die Similar Web-Extension nicht nur nach Hause, wenn man sich gerade die Daten für eine Seite anzeigen lässt, sondern bei jeder Seite, die man sich anschaut.
Wenn man dann einmal überlegt, für wen solche Daten interessant sind und wer sich dann eine solche Extension installiert, dann sind wir bei der Datenqualität von den Alexa Top Sites angekommen. Webmaster, Marketingmenschen, Suchmaschinenoptimierer, all diese Menschen haben eine höhere Wahrscheinlichkeit diese Extension zu installieren als zum Beispiel ein Teenie oder meine Mutter.
Crawling
Was genau Similar Web crawlt ist mir immer noch ein Rätsel, insbesondere wieso ein Crawling Aufschluss darüber geben kann, wie viel Traffic eine Seite hat. Genau genommen verursacht man ja nur Traffic mit einem Crawler Similar Web sagt dazu, “[we] scan every public website to create a highly accurate map of the digital world”. Vermutlich werden hier Links ausgelesen, vielleicht auch Themen automatisiert erkannt.
ISP-Traffic
Leider sagt Similar Web nicht, von welchen ISPs sie Traffic-Daten bekommen. In Deutschland ist es wahrscheinlich verboten, aber in irgendwelchen Ländern wird es sicherlich erlaubt sein, dass ein Internet Service Provider die Kollegen von Similar Web alles aufzeichnen lässt, was an Traffic durch ihre Kabel läuft. Das wäre natürlich eine sehr gute Datenbasis. Nur ist nicht jeder ISP gleich. Würden wir den Daten vertrauen, wenn zum Beispiel AOL noch existierte und nur deren Nutzer gemessen würden? Schlimmer noch, an keiner Stelle macht SimilarWeb transparent, wo ISP-Daten einfließen.
Direktmessungen
Hier wird es spannend, denn Firmen können ihre Web Analyse-Daten, in diesem Fall Google Analytics, direkt mit Similar Web verbinden, so dass die von Google Analytics gemessenen Daten für alle Similar Web-Nutzer zur Verfügung stehen. Dann steht bei der Site “verified”. Warum sollte man das tun? Man bekommt dafür nichts geschenkt, stattdessen könne man dadurch mit mehr Werbeeinnahmen rechnen oder seine Marke stärken. Ziemlich schwache Argumente, finde ich, dennoch finden sich einige Seiten, die das dennoch tun.
Wie zuverlässig sind die Similar Web-Daten wirklich?
Natürlich sind die Direktmessungen zuverlässig. Schwierig wird es bei allen anderen Datenquellen. Diese machen die Mehrzahl der Messungen aus. Nur ein Bruchteil der Similar Web-Daten basiert nach meinem Sample aus Direktmessungsdaten. Aber hier könnte man sicherlich auf Basis der genau gemessenen Daten und der ungenau gemessenen Daten Modelle erstellen. Wenn ich weiß, wie die Daten von spiegel.de genau sind und wie die ungenau gemessenen Daten aussehen, dann könnte ich zum Beispiel den Panel-Bias berechnen und für andere Seiten ausgleichen. Und das könnte ich auch mit allen anderen Daten tun. Aber funktioniert das wirklich? Schauen wir uns mal eine Messung von Similar Web an, für eine meiner Seiten:

Anscheinend schwankt die Anzahl der Besucher zwischen so gut wie nix und 6.000 Nutzern. Es gibt keine eindeutigen Muster. Und nun schauen wir uns die echten Zahlen von Google Analytics an:
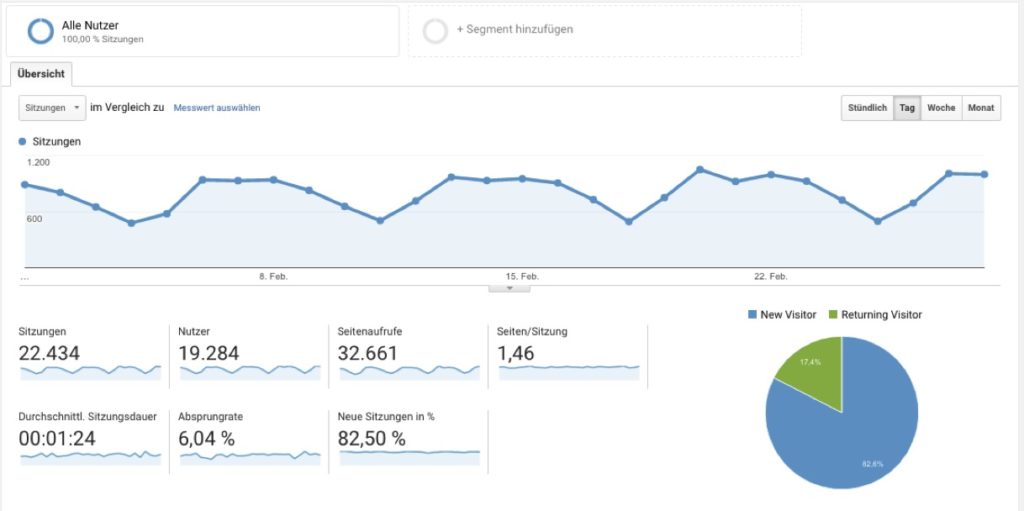
Es ist derselbe Zeitraum. Und dennoch sind die eindeutigen Traffic-Muster aus den Google Analytics-Daten nicht in den Similar Web-Daten zu erkennen. Die Daten sind einfach falsch.
Fazit
Kann man Similar Web dann überhaupt nutzen? Ich rate komplett davon ab, sofern die erhobenen Daten nicht aus einer Direktmessung stammen. Natürlich kann nun die Frage kommen, was man denn sonst verwenden soll. Die Gegenfrage ist, was man mit Daten anfangen kann, von denen man nicht sicher sein kann, ob sie überhaupt irgendwie stimmen. In der Statistik legt man sich sowieso schon selten fest, aber wenn nicht mal die Erhebung der Daten transparent ist, dann muss man die Finger davon lassen. Wenn ich eine Geschäftsentscheidung treffen muss, die eventuell viel Geld kostet, dann würde ich mich nicht auf diese Daten verlassen. Und “für einen ersten Blick…?” Wir wissen auch, dass aus einem “ersten Blick” schnell ein “Fakt” werden kann, weil es so gut in die eigene Argumentation passt. Womit wir wieder bei dem Bestätigungsfehler wären.
Kommentare (seit Februar 2020 ist die Kommentarfunktion von meinem Blog entfernt):
Konrad says
- August 2017 at 14:56 Zum Thema Crawling: Vielleicht crawlen die nicht geschützte AW Stats Installationen und andere Counter Dienste und nutzen dann die Daten um die Algos zur Hochrechnung zu trainieren? Ist natürlich alles sehr unpräzise. Die nutzen meines Wissens nicht nur die SimilarWeb Toolbar sondern kaufen auch Daten aus fremden Browser Addons ein. Adblocker könnten schon eine viel bessere Datenbasis liefern…
Tom Alby says
- August 2017 at 11:52 Das ist nirgendwo dokumentiert, und wenn sie das täten, dann würden sie sicherlich darüber schreiben, denn das würde ja mehr Vertrauen schaffen. Allerdings sind die AdBlocker-Nutzer auch kein verkleinerter Ausschnitt der Gesamtbevölkerung, d.h. ich könnte daraus nicht auf die Gesamtpopulation schließen.
Und welche Seiten haben noch AW-Stats und andere Counter Dienste?
Daniel Brückner says
- August 2017 at 09:14 Hi Tom,
bzgl. des Crawlings: „data“ bedeutet ja nicht unbedingt, dass es sich um Trafficdaten handelt.
bzgl. des Panels: Es könnte auch sein, dass sie Trafficdaten von anderen Browserextensions aufkaufen. Darauf aufbauend kann man schon eine Schätzung abgeben.
Aber insgesamt hast Du Recht, dass man die Zahlen mit Vorsicht genießen sollte.
Lg, Daniel
Tom Alby says 11. August 2017 at 17:22 Hallo Daniel,
bzgl. Panel: das ist so nicht richtig, denn bei welchen anderen Browser Extensions kannst Du sicher sein, dass sie von einem Ausschnitt der Bevölkerung installiert wird, der der GesamtSurfPopulation entspricht? Bei Extensions würde ich immer davon ausgehen, dass allein die Bereitschaft zur Extension-Installation Dich aus der breiten Masse heraushebt. bzgl. Crawling: Steht ja auch da.
BG
Tom
Jan says
- Oktober 2017 at 05:28 Busted Ich kann sehen, die Extention ist wertlos. Gibts denn sowas, dass funktioniert?
Tom Alby says
- Oktober 2017 at 19:05 Nein. Sorry.
Tom says
- Juli 2019 at 13:34 Toller Artikel, der mir aus der Seele spricht! Ich bin bei den Daten (außer den verifizierten Direktmessungen) auch extrem skeptisch. SimilarWebs offizielle Wischiwaschi-Formulierung zu dem Thema verstärkt meine Skepsis nur noch mehr.
Ehrlich gesagt frage ich mich, wie die es überhaupt geschafft haben, Investoren für sich zu gewinnen…