Über Personas habe ich mich ja schon an anderer Stelle ausgelassen, in diesem Artikel geht es um die datengetriebene Generierung von Personas. Ich halte mich an die Definition des Persona-Erfinders Cooper und sehe eine Persona als Prototyp für eine Gruppe von Nutzern. Dies kann auch fürs Marketing interessant sein, denn schließlich lässt dich damit eine bedürfnis- und erfahrungsorientierte Kommunikation zum Beispiel auf einer Webseite erstellen. Personas sind keine Zielgruppen, aber dazu an anderer Stelle mehr.
Wie erstellt man eine datengetriebene Persona?
Den perfekten allgemeingültigen Weg für datengetriebene Personas habe ich auch noch nicht gefunden. Externe Daten sind nicht für alle Themen vorhanden, der ursprüngliche Ansatz von 10-12 Interviews schwierig, und interne Daten haben den Nachteil, dass sie ja nur die Daten derjenigen beinhalten, die man schon kennt, nicht derjenigen, die man vielleicht noch erreichen möchte. Die Wahrheit liegt im Zusammenlegen verschiedener Datenquellen.
Datengetriebene Persona meets Webanalyse
Webanalyse-Daten bieten einiges an Nutzungsverhalten, und je nachdem wie eine Seite aufgebaut ist (zum Beispiel ob sie schon auf die verschiedenen Bedürfnisse unterschiedlicher Personas ausgerichtet ist), lässt sich nachvollziehen, inwieweit sich die verschiedenen Nutzergruppen tatsächlich wie erwartet verhalten. Oder man versucht daten-getriebene Personas aus dem Nutzungsverhalten auf der Webseite zu generieren. Alles unter der Einschränkung, dass die Nutzer die Seite ja erst einmal finden müssen, es ist also nicht sicher, dass wirklich alle Personengruppen tatsächlich auf diese Seite zugreifen und deswegen wichtige Personas übersehen werden. In diesem Artikel geht es um einen Spezialfall dieser automatisierten Persona-Generierung aus Webanalyse-Daten, der aus algorithmischer Sicht und der dazugehörigen Visualisierung spannend ist. Über Erfolge berichtet bekanntlich jeder gerne, hier mal ein Fall, wo der Misserfolg zeigt, in welche Richtung weitere Arbeit gehen könnte.
Die Erfahrungen aus dem Web Mining werden nur selten mit Personas in Verbindung gebracht, obwohl schon vor mehr als 10 Jahren einiges an Forschung dazu betrieben worden ist; für eine Übersicht siehe zum Beispiel Facca und Lanzi, Minining interesting knowledge from weblogs: a survey, aus dem Jahr 2004 (2005 veröffentlicht). Wurden früher vor allem Weblogs (nicht Web-Blogs!) verwendet, also vom Server geschriebene Logdateien, so haben wir heute durch Google Analytics & Co die Möglichkeit, viel “bessere” Daten verwenden zu können.
Reintroducing: Assoziations-Regeln
Aber was genau ist besser? Wir können in GA & Co besser Menschen von Bots unterscheiden (von denen es mehr gibt als man denkt), Wiederkehrer werden zuverlässiger erkannt, Geräte etc. Die Frage ist, ob man die zusätzlichen Daten unbedingt verwenden muss für grundlegende datengetriebene Personas. Denn Assoziationsregeln, über die ich schon mal in einem Beitrag über das Clustering mit Google Analytics und R geschrieben habe und die auch von Facca und Lanzi erwähnt werden, können bereits grundlegende Gruppen von Nutzer identifizieren (ich hatte in dem anderen Artikel bereits erwähnt, dass ich für einen der Schöpfer des Algos, Tomasz Imilinski, mal gearbeitet hatte, aber eine Anekdote mit ihm muss ich noch loswerden: In einem Meeting sagte er mal zu mir, dass man oft denke, etwas sei eine low hanging fruit, ein schneller Erfolg, aber, “Tom, often enough, the low hanging fruits are rotten”. Er hat damit so oft Recht behalten.). Die Gruppen identifizieren sich durch ein gemeinsames Verhalten, die Co-Occurence von Seitenaufrufen zum Beispiel. In R funktioniert das wunderbar mit dem Package arules und dem darin enthaltenen Algo apriori.
Datengetriebene Personas mit Google Analytics & Co.
Wie bereits in dem früheren Artikel erwähnt: Eine Standard-Installation von Google Analytics ist nicht ausreichend (ist sie sowieso nie). Entweder hat man die 360-Variante oder “hackt” die kostenlose Version (“hacken” in Bezug auf “tüftlen”, nicht “kriminell sein”) und zieht sich die Daten via API. Bei Adobe Analytics können die Daten aus dem Data Warehouse gezogen werden oder auch über eine API. Einfach Google Analytics verwenden und daraus Personas ziehen ist also nicht möglich bei diesem Ansatz. Man muss außerdem nachdenken, welches Datum aus GA am besten verwendet wird neben der Client ID, um Transaktionen zu repräsentieren. Das kann von Website zu Website ganz unterschiedlich sein. Und wenn man ganz geschickt sein will, dann ist ein PageView allein vielleicht nicht Signal genug.
Hier geht es aber zunächst um die Visualisierung und welche Einschränkung der apriori-Ansatz hat für die automatisierte Generierung von datengetriebenen Personas. Für die Visualisierung arbeite ich mit dem Package arulesViz. Die daraus entstehenden Grafiken sind nicht ganz einfach zu interpretieren, wie ich an der HAW, aber auch mit Kollegen erlebt habe. Wir sehen hier unten die Visualisierung von Assoziationsregeln, die aus den Daten dieser Seite gewonnen werden, und zwar mit dem GA-Datum pagePathLevel1 (der bei mir leider gleichzeitig ein Artikel-Titel ist). Hier fällt bereits eines auf: Ich kann hier eigentlich nur zwei Gruppen identifizieren, und das ist ganz schön dürftig.
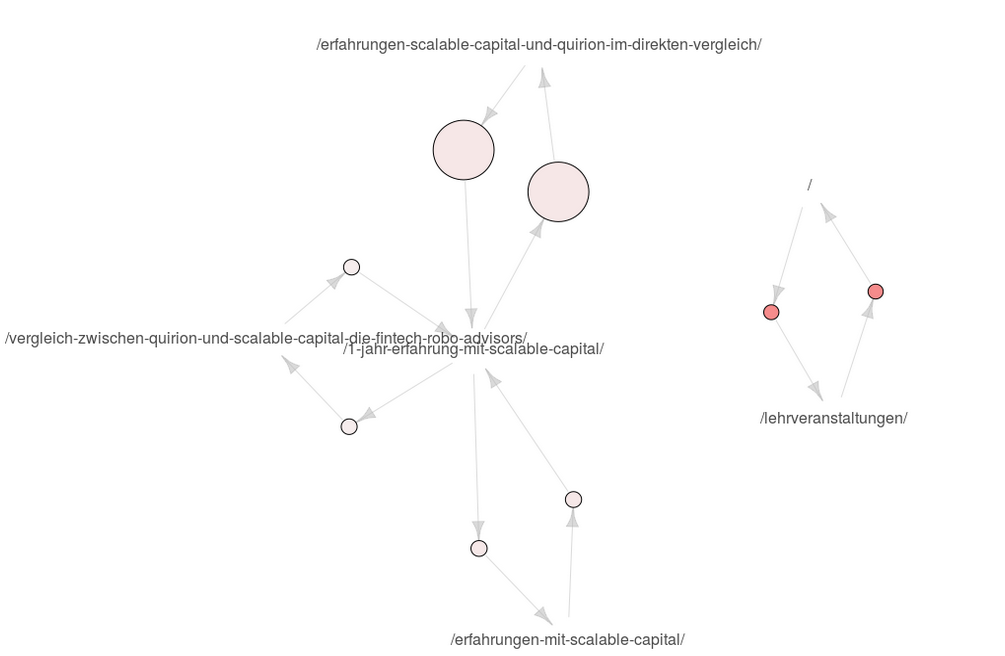
Was sehen wir hier genau? Wir sehen, dass Nutzer, die auf der Homepage sind, auch in den Bereich Lehrveranstaltungen gehen und umgekehrt. Der Lift ist hier hoch, der Support nicht so. Und dann sehen wir, dass sich Nutzer zwischen meinen vier Artikeln über Scalable Capital bewegen, mit ungefähr gleichem niedrigen Lift, aber unterschiedlich hohem Support. Lift ist der Faktor, um den die Co-Occurence von zwei Items höher ist als deren wahrscheinliches Auftreten, wenn sie unabhängig voneinander wären. Support ist die Häufigkeit. Der Support war beim Erstellen der Assoziationsregeln auf 0.01 definiert worden, die Konfidenz ebenso auf 0.01. Für Details siehe meinen ersten Artikel.
Warum aber sehe ich hier keine anderen Seiten? Mein Artikel über Google Trends ist ein sehr häufig gelesener Artikel, ebenso der über den Thermomix oder AirBnB. Es liegt also nicht daran, dass es nicht mehr Nutzergruppen gäbe. Der Nachteil dieses Ansatzes ist einfach, dass Nutzer mehr als eine Seite besucht haben müssen, damit überhaupt eine Regel hier entstehen kann. Und da einige Nutzer über eine Google-Suche kommen und anscheinend kein Interesse an einem zweiten Artikel haben, weil ihr Informationsbedürfnis vielleicht schon befriedigt ist oder weil ich diese nicht gut genug anpreise, sind hier in diesen Regeln anscheinend nur Studierende sowie Scalable Capital-Interessierte zu identifizieren.
Auswege aus dem apriori-Dilemma?
Bisher habe ich drei Lösungswege für dieses Dilemma identifiziert, und alle erfordern Mehrarbeit:
- Ich teste, ob ich Nutzer durch ein besseres relevantes Angebot dazu bekomme, dass sie sich mehr als eine Seite ansehen, zum Beispiel mit Google Optimize, und erhalte im Erfolgsfall bessere Daten.
- Ich nutze die apriori-Daten nur als Basis und merge sie mit anderen Daten (auch sehr schön, werde ich aber nicht hier behandeln)
- Ich setze den Support und die Konfidenz herunter.
Am schönsten ist der erste Ansatz, meiner Meinung nach, aber dieser erfordert Zeit und Gehirn. Und dass etwas herauskommt ist nicht gesagt. Der letzte Ansatz ist unschön, da wir hier halt mit Fällen zu tun haben, die seltener vorkommen und daher nicht unbedingt belastbar. Bei einem Support von 0.005 sieht die Visualisierung zwar anders aus:

Aber wieder habe ich das Problem, dass die Einzelseiten nicht auftauchen. Es ist also anscheinend extrem selten, dass sich jemand von dem Google Trends-Artikel zu einem anderen Artikel hinbewegt, so dass das Herabsenken des Support-Werts nix gebracht hat. Aus der Erfahrung kann ich sagen, dass dieses Problem mehr oder weniger stark auftaucht auf den meisten Seiten, die ich ansonsten sehe, aber es taucht immer irgendwie auf. Das Dumme ist, wenn man schon gute Personas ablesen kann, dann ist man eher geneigt, sich den Rest nicht mehr anzusehen, auch wenn der vom Umfang her sehr groß sein könnte.
Wir sehen in der Grafik außerdem ein weiteres Problem, denn die Nutzer im rechten Strang müssen von Pfeil zu Pfeil nicht dieselben sein. Anders ausgedrückt: Es ist nicht gesagt, dass sich Besucher, die Fotografie-Seiten und Lehrveranstaltungen ansehen, auch die Veröffentlichungen ansehen, auch wenn das in der Visualisierung so aussieht. Wenn A und B sowie B und C, dann gilt hier nicht A und C! Um dies zu lösen, müssten die Assoziationsregeln in der Visualisierung noch eine ausschließende Kennzeichnung haben. Die existiert nicht und wäre eine Aufgabe für die Zukunft.
Fazit
Der Weg über Assoziationsregeln ist spannend für die Erstellung Daten-getriebener Personas mit Google Analytics oder anderen Webanalyse-Tools. Er wird momentan in der Regel aber nicht ausreichend sein, da a) das Problem von Eine-Seite-Besuchern hier nicht gelöst wird, b) die Regeln nicht ausreichend über unterschiedliche Gruppen informieren, die nur Überschneidungen haben und c) er eh nur über diejenigen Gruppen etwas aussagen kann, die bereits auf der Seite sind. An a) und b) arbeite ich momentan nebenbei, über Gedanken von außen freue ich mich dabei immer