After I explained in the first part what data science is and what already exists in this area on the subject of SEO, now the second part, where we take a closer look at what the linguistic processing of a document by a search engine has on SEO concepts such as keyword density, TF/IDF and WDF/IDF. Since I showed Campixx live code at SEO, I offer everything for download here, which makes following the examples even more eventful. By the way, this is also possible without the installation of R, here you can find the complete code with explanations and results.
For those who want to recreate it in R
(Please skip if you don’t want to recreate this yourself in R)
I recommend using RStudio in addition to R, because handling the data is a bit easier for newbies (and for professionals as well). R is available at the R Project, RStudio on rstudio.com. First install R, then RStudio.
In the ZIP file there are two files, a notebook and a CSV file with a small text corpus. I refer to the notebook from time to time in this text, but the notebook can also be worked through in this way. Important: Please do not read the CSV file with the import button, because then a library will be loaded, which will nullify the functionality of another library.
The notebook has the great advantage that both my description, the program code and the result can be seen in the same document.

To execute the program code, simply click on the green arrow in the upper right corner, and it works
What is TF/IDF or WDF/IDF?
(Please skip if the concepts are clear!)
There are people who can explain TF/IDF (Term Frequency/Inverse Document Frequency) or WDF/IDF (Word Document Frequency/Inverse Document Frequency) better than me, at WDF/IDF Karl has distinguished himself with an incredibly good article (and by the way, in this article he has already said that “actually no small or medium-sized provider of analysis tools can offer such a calculation for a large number of users … ; -“).
A simplistic explanation is that the term frequency (TF) is the frequency of a term in a document, while the Inverse Document Frequency (IDF) measures the importance of a term in relation to all documents in a corpus in which the term occurs (corpus is the linguists’ term for a collection of documents; this is not the same as an index).
In TF, the number of occurrences of a term is counted, simplified but still far too complicated, and then normalized, usually by dividing that number by the number of all words in the document (this definition can be found in the book “Modern Information Retrieval” by Baeza-Yates et al, the bible of search engine builders). But there are other weightings of the TF, and WDF is actually nothing more than such a different weighting, because here the term frequency is provided by a logarithm to base 2.
In the IDF, the number of all documents in the corpus is divided by the number of documents in which the term appears, and the result is then provided with a logarithm to base 2. The Term Frequency or the Word Document Frequency is then multiplied by the Inverse Document Frequency, and we have TF/IDF (or, if we used WDF instead of TF, WDF/IDF). The question that arises to me as an ex-employee of several search engines, however, is what exactly is a term here, because behind the scenes the documents are eagerly tinkered with. More on this in the next section “Crash Course Stemming…”.
Crash Course Stemming, Composite and Proximity
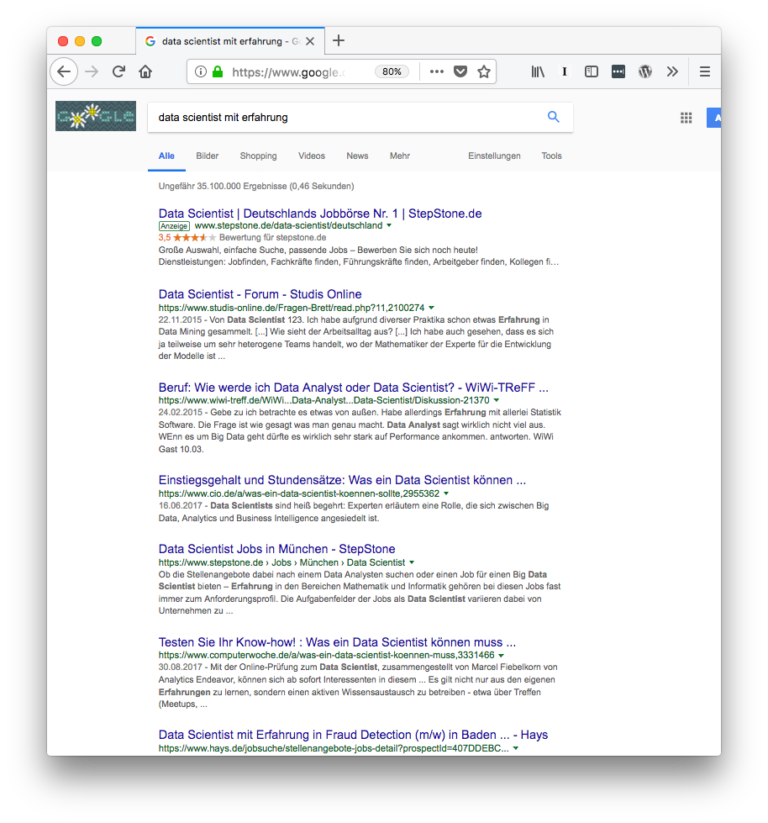
Everyone has had the experience that you search for a term and then get a results page where the term can also be found in a modified form. This is because, for example, stemming is carried out, in which words are reduced to their word stem. Because not only in German is conjugated and declined, other languages also change words depending on the person, tense, etc. In order to increase the recall, not only the exact term is searched for, but also variants of this term (I did not use the term “recall” in the lecture, it describes in the Information Retrieval how many suitable documents are found for a search query). For example, for the search query “Data scientist with experience”, documents are also found that contain the terms “data scientist” and “experience” (see screenshot on the left).
In the lecture, I “lifted” live, with the SnowballC-Stemmer. This is not necessarily the best stemmer, but it gives an impression of how stemming works. In the R-Notebook for this article, the Stemmer is slightly expanded, because unfortunately the SnowBallC only ever lifts the last word, so that the Stemmer has been packed into a function that can then handle a whole set completely:
| > stem_text(“This is a great post”) [1] “This is a great post” > stem_text(“Hope you’ve read this far.”) [1] “Hopefully you have read this far.” |
But they are not just variants of a term. We Germans in particular are world champions in inventing new words by “composing” them by putting them together with other words. It is not for nothing that these neologisms are called compounds. An example of the processing of compounds can be found in the screenshot on the right, where the country triangle becomes the border triangle. First of all, it sounds quite simple, you simply separate terms that could stand as a single word and then index them. However, it is not quite that simple. Because not every compound may be separated, because it takes on a different meaning separately. Think, for example, of “pressure drop”, where the drop in pressure could also be interpreted as pressure and waste

The example of the “data scientist with experience” also illustrates another method of search engines: Terms do not have to be together. They can be further apart, which can sometimes be extremely annoying for the searcher if one of the terms in the search query is in a completely different context. The proximity, i.e. the proximity of the terms, can be a signal for the relevance of the terms present in the document for the search query. Google offers Proximity as a feature, but it is not clear how Proximity will be used as a ranking signal. And this only means the textual proximity, not yet the semantic proximity. Of course, there is much more processing in lexical analysis, apart from stop word removal etc. But for now, this is just a small insight.
So we see three points here that most SEO tools can’t do: stemming, proximity and decompounding. So when you talk about keyword density, TF/IDF or WDF/IDF in the tools, it’s usually based on exact matches and not the variants that a search engine processes. This is not clear with most tools; for example, the ever-popular Yoast SEO plugin for WordPress can only use the exact match and then calculates a keyword density (number of the term in relation to all words in the document). But ryte.com says, for example:
In addition, the formula WDF*IDF alone does not take into account that search terms can also occur more frequently in a paragraph, that stemming rules could apply or that a text works more with synonyms.
So as long as SEO tools can’t do that, we can’t assume that these tools give us “real” values, and that’s exactly what dear Karl Kratz has already said. These are values that were calculated on the basis of an exact match, whereas search engines use a different basis. Maybe it doesn’t matter at all, because everyone only uses the SEO tools and optimizes for them, we’ll take a look at that in the next part. But there are other reasons why the tools don’t give us the whole view, and we’ll take a closer look at them in the next section.
Can we measure TF/IDF or WDF/IDF properly at all?
Now, the definition of IDF already says why a tool that spits out TF/IDF has a small problem: It doesn’t know how many documents with the term are in the Google corpus, unless this number is also “scraped” from the results. And here we are dealing more with estimates. It is not for nothing that the search results always say “Approximately 92,800 results”. Instead, most tools use either the top 10, the top 100, or maybe even their own small index to calculate the IDF. In addition, we also need the number of ALL documents in the Google index (or all documents of a language area, which Karl Kratz drew my attention to again). According to Google, this is 130 trillion documents. So, in a very simplified way, we would have to calculate like this (I’ll take TF/IDF, so that the logarithm doesn’t scare everyone off, but the principle is the same):
TF/IDF = (Frequency of the term in the document/Number of words in the document)*log(130 trillion/”Approximately x results”),
where x is the number that Google displays per search result. So, and then we would have one number per document, but we don’t know what TF/IDF or WDF/IDF value the documents that are not among the top 10 or top 100 results examined. It could be that there is a document in 967th place that has better values. We only see our excerpt and assume that this excerpt explains the world to us.
And this is where chaos theory comes into play: Anyone who has seen Jurassic Park (or even read the book) may remember the chaos theorist, played by Jeff Goldblum in the film. Chaos theory plays a major role in Jurassic Park, because it is about the fact that complex systems can exhibit behavior that is difficult to predict. And so large parts of the park are monitored by video cameras, except for 3% of the area, and this is exactly where the female dinosaurs reproduce. Because they can change their sex (which frogs, for example, can also do). Transferred to TF/IDF and WDF/IDF, this means: we don’t see 97% of the area, but less than 1% (the top 10 or top 100 of the search results) and don’t know what’s lying dormant in the rest of our search results page. Nevertheless, we try to predict something on the basis of this small part.
Does this mean that TF/IDF or WDF/IDF are nonsense? No, so far I have only shown that these values do not necessarily have anything to do with what values a search engine has internally. And this is not even new information, but already documented by Karl and some tool providers. Therefore, in the next part, we will take a closer look at whether or not we can find a correlation between TF/IDF or WDF/IDF and position on the search results page.
Say it with data or it didn’t happen
In the enclosed R-notebook, I have chosen an example to illustrate this, which (hopefully) reminds us all of school, namely I have made a small corpus of Goethe poems (at least here I have no copyright problems, I was not quite so sure about the search results). A little more than 100 poems, one of which I still know by heart after 30 years. In this wonderful little corpus, I first normalize all the words by lowering them all, removing numbers, removing periods, commas, etc., and removing stop words.
Although there is a library tm in R with which you can calculate TF/IDF as well as TF (normalized)/IDF, but, scandal (!!), nothing about WDF/IDF. Maybe I’ll build a package for it myself. But for illustrative purposes, I just built all the variants myself and put them next to each other. So you can see for yourself what I did in my code. Let’s take a look at the data for the unstemmed version:

We can see here that the “ranking” would change if we were to sort by TF/IDF or TF (normalized)/IDF. So there is a difference between WDF/IDF and the “classical” methods. And now let’s take a look at the data for the managed version:
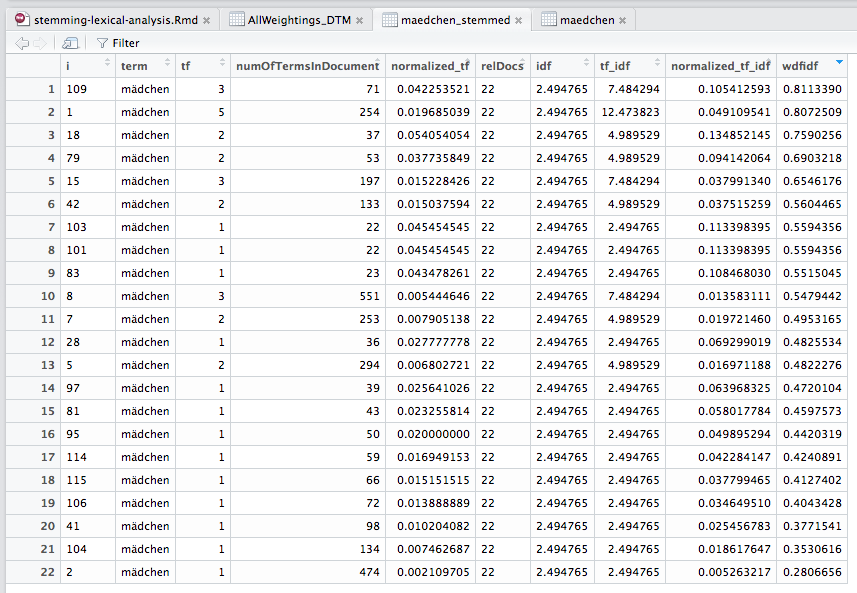
We see that two documents have cheated their way into the top 10, and also that we suddenly have 22 instead of 20 documents. This is logical, because a term with two or more different stems can now have become one. But we also see very quickly that all the numbers have changed. Because now we have a different basis. In other words, whatever SEOs read from WDF/IDF, the values are most likely not what actually happens at Google. And again: This is not news! Karl Kratz has already said this, and some tools also say this in their glossaries. After my lecture, however, it seemed as if I had said that God does not exist
And perhaps it is also the case that the rapprochement alone works. We’ll look at that in the next parts about data science and SEO.
Was that data science?
Phew. No. Not really. Just because you’re working with R doesn’t mean you’re doing data science. But at least we warmed up a bit by really understanding how our tool actually works.



